SkipList算法实现
SkipList是一种快速查找链表,链表元素的是有序的。由W.Pugh发明于1989年。
其算法复杂度如下:
Average Worst case
Space O(n) O(n log n)
Search O(log n) O(n)
Insert O(log n) O(n)
Delete O(log n) O(n)
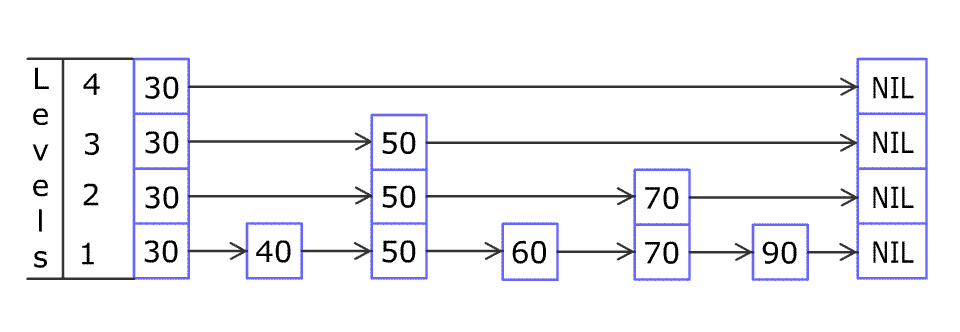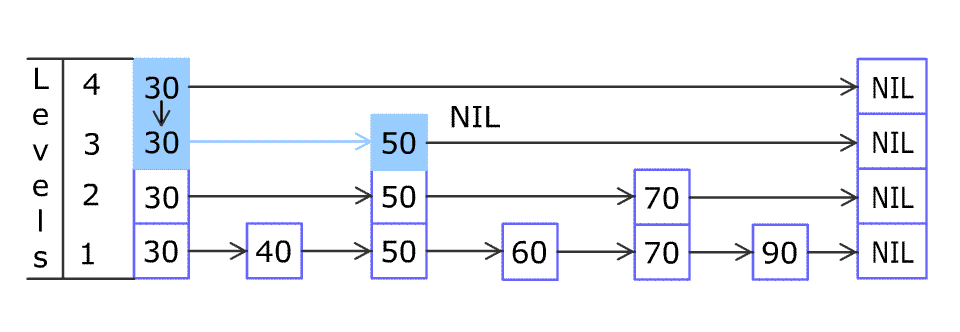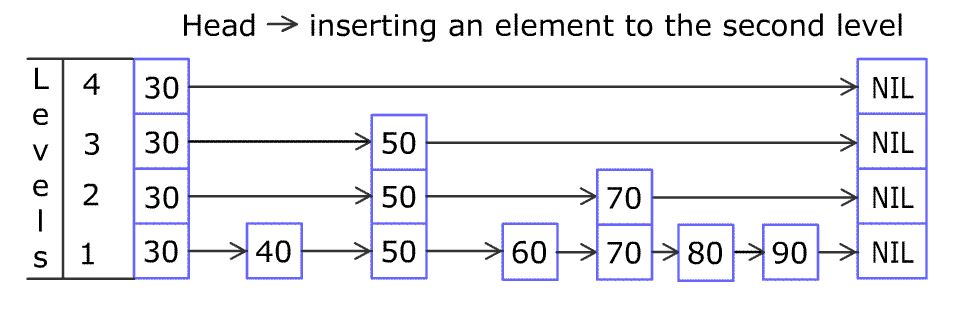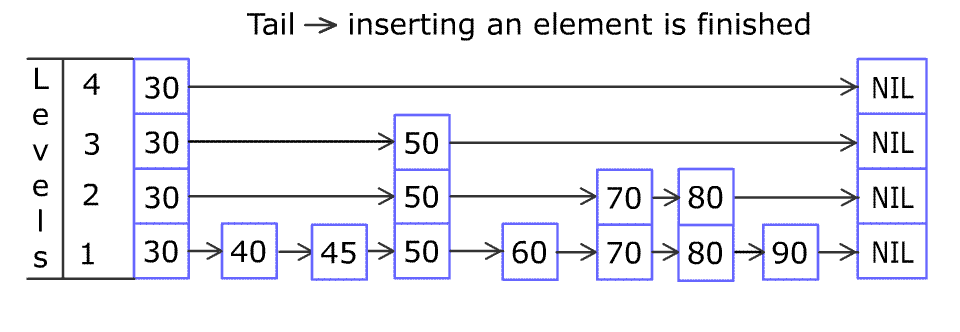
(图片来源于WiKi)
均算法复杂度不亚于AVL和红黑树。其数据结构和操作也简单。AVL树和红黑树为保
持平衡,维护树的平衡代价高。
SkipList 现用于Redis,LevelDB等开源项目, 维基百科可以看它到很多应用场景。
根据W.Pugh的论文,其算法实现如下:
#include <cstdio>
#include <iostream>
#include <cstdlib>
#include <random>
using namespace std; #define MaxLevel 5 typedef struct SkipListNode {
int value;
int key;
int level;
SkipListNode* forward[MaxLevel];
} SkipListNode; typedef struct SkipList {
SkipListNode* head;
int level;
int length;
} SkipList; SkipListNode* makeNode(int level, int key, int value)
{
SkipListNode* pNode = (SkipListNode *)malloc(sizeof(SkipListNode));
if (!pNode) {
return NULL;
}
pNode->key = key;
pNode->value = value;
pNode->level = level;
for (int i = ; i < MaxLevel; ++i)
pNode->forward[i] = NULL; return pNode;
} void initSkipList(SkipList *pSkipList)
{
if (!pSkipList)
return;
SkipListNode* head = makeNode(, , );
if (!head)
return;
pSkipList->head = head;
pSkipList->length = ;
pSkipList->level = ; for (int i = ; i < MaxLevel; i++)
pSkipList->head->forward[i] = NULL;
} int randomLevel()
{
int newLevel = ;
while ((rand() & 0xFFFF) < (0.4 * 0xFFFF))
++newLevel;
return newLevel < MaxLevel ? newLevel : MaxLevel;
}
bool insertNode(SkipList *pSkipList, int searchKey, int newValue)
{
SkipListNode* update[MaxLevel];
if (!pSkipList)
return false; SkipListNode* pNode = pSkipList->head;
if (!pNode) {
return false;
}
for (int i = pSkipList->level - ; i >= ; i--) {
while (pNode->forward[i] && pNode->forward[i]->key < searchKey)
pNode = pNode->forward[i]; // pNode->key < searchKey < pNode->forward[i]->key
update[i] = pNode;
}
pNode = pNode->forward[];
if (pNode && pNode->key == searchKey) {
pNode->value = newValue;
}
else {
int level = randomLevel();
if (level > pSkipList->level) {
for (int i = pSkipList->level; i < level; i++) {
update[i] = pSkipList->head;
}
pSkipList->level = level;
}
pNode = makeNode(level, searchKey, newValue);
if (!pNode) {
return false;
}
for (int i = ; i < pSkipList->level; ++i) {
pNode->forward[i] = update[i]->forward[i];
update[i]->forward[i] = pNode;
}
pSkipList->length++;
}
return true;
} SkipListNode* searchNode(SkipList *pSkipList, int searchKey) {
if (!pSkipList)
return NULL; SkipListNode *pNode = pSkipList->head;
if (!pNode)
return NULL; for (int i = pSkipList->level - ; i >= ; --i) {
while (pNode->forward[i] && pNode->forward[i]->key < searchKey)
pNode = pNode->forward[i];
} pNode = pNode->forward[];
if (pNode && pNode->key == searchKey)
return pNode;
return NULL;
} bool deleteNode(SkipList* pSkipList, int searchKey) {
if (!pSkipList)
return false; SkipListNode *pNode = pSkipList->head;
SkipListNode *update[MaxLevel]; for (int i = pSkipList->level - ; i >= ; i--) {
while (pNode->forward[i] && pNode->forward[i]->key < searchKey) {
pNode = pNode->forward[i];
}
update[i] = pNode;
} pNode = pNode->forward[];
if (pNode && pNode->key == searchKey) {
for (int i = ; i < pSkipList->level; ++i) {
if (update[i] && update[i]->forward[i] != pNode) {
break;
}
update[i]->forward[i] = pNode->forward[i];
}
free(pNode);
while (pSkipList->level > &&
pSkipList->head->forward[pSkipList->level - ] == NULL) {
pSkipList->level--;
}
pSkipList->length--;
return true;
}
return false;
} void travelList(SkipList* pSkipList)
{
SkipListNode* pNode = pSkipList->head;
if (!pNode)
return; while (pNode->forward[]) {
cout << pNode->forward[]->value << " " << pNode->forward[]->level << endl;
pNode = pNode->forward[];
}
} int main()
{
SkipList list;
initSkipList(&list); insertNode(&list, , );
insertNode(&list, , );
insertNode(&list, , ); travelList(&list); SkipListNode* pNode = searchNode(&list, );
cout << pNode->value << endl; pNode = searchNode(&list, );
cout << pNode->value << endl; cout << "----" << endl;
deleteNode(&list, );
travelList(&list); cout << "----" << endl;
deleteNode(&list, );
travelList(&list); cout << "----" << endl;
deleteNode(&list, );
travelList(&list);
return ;
}
SkipList算法实现的更多相关文章
- 深夜学算法之SkipList:让链表飞
1. 前言 上次写Python操作LevelDB时提到过,有机会要实现下SkipList.摘录下wiki介绍: 跳跃列表是一种随机化数据结构,基于并联的链表,其效率可比拟二叉查找树. 我们知道对于有序 ...
- 算法: skiplist 跳跃表代码实现和原理
SkipList在leveldb以及lucence中都广为使用,是比较高效的数据结构.由于它的代码以及原理实现的简单性,更为人们所接受. 所有操作均从上向下逐层查找,越上层一次next操作跨度越大.其 ...
- ssdb底层实现——ssdb底层是leveldb,leveldb根本上是skiplist(例如为存储多个list items,必然有多个item key,而非暴力string cat),用它来做redis的list和set等,势必在数据结构和算法层面上有诸多不适
我已经在用ssdb的hash结构,存储了很多数据了,但是我现在的用法正确吗? 我使用hash结构合理吗? 1. ssdb数据库说是类似redis,而且他们都有hash结构,但是他们的命名有点不同,ss ...
- 探索c#之跳跃表(SkipList)
阅读目录: 基本介绍 算法思想 演化步骤 实现细节 总结 基本介绍 SkipList是William Pugh在1990年提出的,它是一种可替代平衡树的数据结构. SkipList在实现上相对比较简单 ...
- [转载] 跳表SkipList
原文: http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html leveldb中memtable的思想本质上是一个skiplist ...
- 浅析SkipList跳跃表原理及代码实现
本文将总结一种数据结构:跳跃表.前半部分跳跃表性质和操作的介绍直接摘自<让算法的效率跳起来--浅谈“跳跃表”的相关操作及其应用>上海市华东师范大学第二附属中学 魏冉.之后将附上跳跃表的源代 ...
- 跳表SkipList
原文:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html 跳表SkipList 1.聊一聊跳表作者的其人其事 2. 言归正 ...
- skiplist 跳表(2)-----细心学习
快速了解skiplist请看:skiplist 跳表(1) http://blog.sina.com.cn/s/blog_693f08470101n2lv.html 本周我要介绍的数据结构,是我非常非 ...
- skiplist 跳表(1)
最近学习中遇到一种新的数据结构,很实用,搬过来学习. 原文地址:skiplist 跳表 为什么选择跳表 目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等. ...
随机推荐
- .net实现调用本地exe等应用程序的办法总结
根据客户需求用户要实现在一个BS系统上打开本地的一应用程序,在网上查了好多资料再加上自己的各种测试,到最后功能是实现了,只不过还存在一些问题,接下来会先把各种方法一一列举出来 1.先写最终测试通过的这 ...
- 基于Linux 的VM TOOLS Install
VMware Tools Install 在VMware中为Linux系统安装VM-Tools的详解教程 如果大家打算在VMware虚拟机中安装Linux的话,那么在完成Linux的安装后,如果没 ...
- 微信 网页授权获取用户基本信息(OAuth 2.0)
// 相关设置 $APPID = ""; $AppSecret = ""; $html = ""; // 拼接 URL // 跳转该连接 获 ...
- delphi action学习
procedure TEditAction.UpdateTarget(Target: TObject); begin if (Self is TEditCut) then Enabled := (Ge ...
- rediscluster 集群操作(摘抄)
一:关于redis cluster 1:redis cluster的现状 目前redis支持的cluster特性 1):节点自动发现 2):slave->master 选举,集群容错 3):Ho ...
- web测试特别点
1.浏览器的后退按钮 提交表单一条已经成功提交的记录,back后再提交,看系统会如何处理. 检查多次使用back健的情况在有back的地方,back,回到原来的页面,再back,重复几次,看是否会 ...
- MySQL表分区技术
MySQL表分区技术 MySQL有4种分区类型: 1.RANGE 分区 - 连续区间的分区 - 基于属于一个给定连续区间的列值,把多行分配给分区: 2.LIST 分区 - 离散区间的分区 - 类似于按 ...
- LoadRunner ---手动关联与预关联
手动关联 如果脚本很长,那么我们想找到一个脚本中哪些地方是需要关联的并不是一件容易的事情.这时,我们可以通过脚本对比的方法找 ...
- 常用JS汇总
01. 取文档url参数值 function getQueryString(name) { var reg = new RegExp("(^|&)" + name + &q ...
- SQLServer 关闭自增长,插入数据
怎样随心所欲的插入自增长的值? 关闭自增长 Demo 有表 [dbo].[tbl_Message] 其中ID是自增的要随意插入ID的值 (前提:这个Id当然是不存在的,存在也可以删除) SET IDE ...