python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter=
分析网址'?'符号后的参数,第一个参数'start=0',这个代表页数,‘=0’时代表第一页,‘=25’代表第二页。。。以此类推
一、分析网页:

明确要爬取的元素 :排名、名字、导演、评语、评分,在这里利用Chrome浏览器,查看元素的所在位置
每一部电影信息都在<li></li>当中
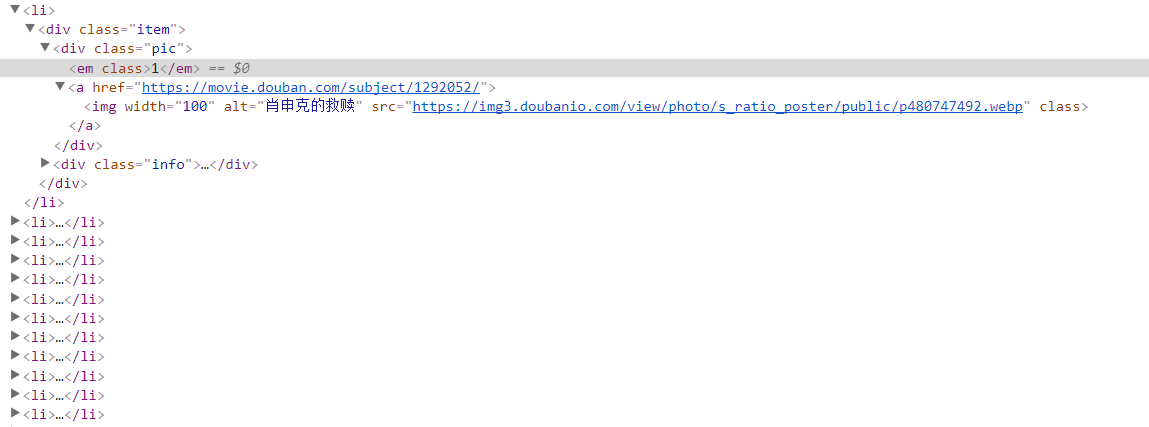
爬取元素的所在位置
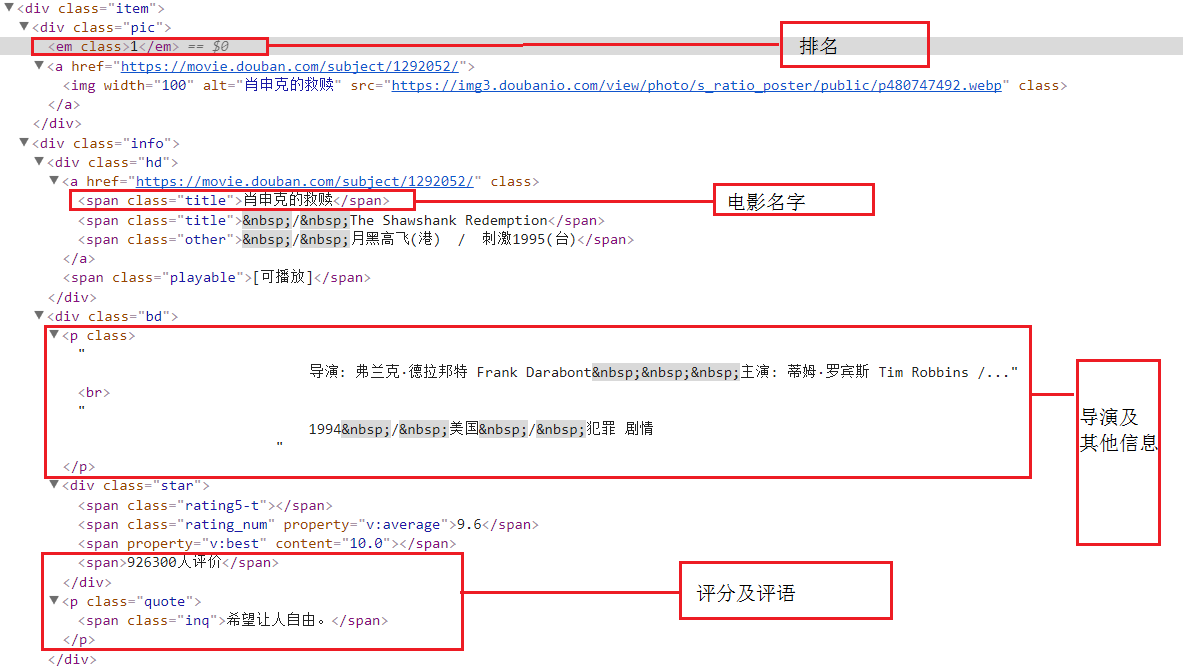
分析完要爬取的元素,开始准备爬取的工作
二、爬取部分:
工具:
Python3
requests
BeautifulSoup
1、获取每一部电影的信息
def get_html(web_url): # 爬虫获取网页没啥好说的
header = {
"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"}
html = requests.get(url=web_url, headers=header).text#不加text返回的是response,加了返回的是字符串
Soup = BeautifulSoup(html, "lxml")
data = Soup.find("ol").find_all("li") # 还是有一点要说,就是返回的信息最好只有你需要的那部分,所以这里进行了筛选
return data
requests.get()函数,会根据参数中url的链接,返回response对象
.text会将response对象转换成str类型
find_all()函数,会将html文本中的ol标签下的每一个li标签中的内容筛选出来
2、筛选出信息,保存进文本
def get_info(all_move):
f = open("F:\\Pythontest1\\douban.txt", "a") for info in all_move:
# 排名
nums = info.find('em')
num = nums.get_text() # 名字
names = info.find("span") # 名字比较简单 直接获取第一个span就是
name = names.get_text() # 导演
charactors = info.find("p") # 这段信息中有太多非法符号你需要替换掉
charactor = charactors.get_text().replace(" ", "").replace("\n", "") # 使信息排列规律
charactor = charactor.replace("\xa0", "").replace("\xee", "").replace("\xf6", "").replace("\u0161", "").replace(
"\xf4", "").replace("\xfb", "").replace("\u2027", "").replace("\xe5", "") # 评语
remarks = info.find_all("span", {"class": "inq"})
if remarks: # 这个判断是因为有的电影没有评语,你需要做判断
remark = remarks[0].get_text().replace("\u22ef", "")
else:
remark = "此影片没有评价"
print(remarks) # 评分
scores = info.find_all("span", {"class": "rating_num"})
score = scores[0].get_text() f.write(num + '、')
f.write(name + "\n")
f.write(charactor + "\n")
f.write(remark + "\n")
f.write(score)
f.write("\n\n") f.close() # 记得关闭文件
注意爬取元素的时候,会有非法符号(因为这些符号的存在,会影响你写入文本中),所以需要将符号用replace函数替换
其余的部分就不做解释了~~
3、全部代码
from bs4 import BeautifulSoup
import requests
import os def get_html(web_url): # 爬虫获取网页没啥好说的
header = {
"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"}
html = requests.get(url=web_url, headers=header).text#不加text返回的是response,加了返回的是字符串
Soup = BeautifulSoup(html, "lxml")
data = Soup.find("ol").find_all("li") # 还是有一点要说,就是返回的信息最好只有你需要的那部分,所以这里进行了筛选
return data def get_info(all_move):
f = open("F:\\Pythontest1\\douban.txt", "a") for info in all_move:
# 排名
nums = info.find('em')
num = nums.get_text() # 名字
names = info.find("span") # 名字比较简单 直接获取第一个span就是
name = names.get_text() # 导演
charactors = info.find("p") # 这段信息中有太多非法符号你需要替换掉
charactor = charactors.get_text().replace(" ", "").replace("\n", "") # 使信息排列规律
charactor = charactor.replace("\xa0", "").replace("\xee", "").replace("\xf6", "").replace("\u0161", "").replace(
"\xf4", "").replace("\xfb", "").replace("\u2027", "").replace("\xe5", "") # 评语
remarks = info.find_all("span", {"class": "inq"})
if remarks: # 这个判断是因为有的电影没有评语,你需要做判断
remark = remarks[0].get_text().replace("\u22ef", "")
else:
remark = "此影片没有评价"
print(remarks) # 评分
scores = info.find_all("span", {"class": "rating_num"})
score = scores[0].get_text() f.write(num + '、')
f.write(name + "\n")
f.write(charactor + "\n")
f.write(remark + "\n")
f.write(score)
f.write("\n\n") f.close() # 记得关闭文件 if __name__ == "__main__":
if os.path.exists("F:\\Pythontest1") == False: # 两个if来判断是否文件路径存在 新建文件夹 删除文件
os.mkdir("F:\\Pythontest1")
if os.path.exists("F:\\Pythontest1\\douban.txt") == True:
os.remove("F:\\Pythontest1\\douban.txt") page = 0 # 初始化页数,TOP一共有250部 每页25部
while page <= 225:
web_url = "https://movie.douban.com/top250?start=%s&filter=" % page
all_move = get_html(web_url) # 返回每一页的网页
get_info(all_move) # 匹配对应信息存入本地
page += 25
python3 爬虫---爬取豆瓣电影TOP250的更多相关文章
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- [151116 记录] 使用Python3.5爬取豆瓣电影Top250
这一段时间,一直在折腾Python爬虫.已有的文件记录显示,折腾爬虫大概个把月了吧.但是断断续续,一会儿鼓捣python.一会学习sql儿.一会调试OpenCV,结果什么都没学好.前几天,终于耐下心来 ...
- Python爬虫-爬取豆瓣电影Top250
#!usr/bin/env python3 # -*- coding:utf-8-*- import requests from bs4 import BeautifulSoup import re ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
随机推荐
- js 添加事件 attachEvent 和 addEventListener 的区别
1.addEventListener 适用w3c标准方法addEventListener绑定事件,如下,事件的执行顺序和绑定顺序一致,执行顺序为method1->method2->meth ...
- n! 进制
n! 进制 Time limit per test: 1.0 seconds Time limit all tests: 1.0 seconds Memory limit: 256 megabytes ...
- MS-SQL 错误: The offset specified in a OFFSET clause may not be negative
Example 1 : (Fetch clause must be greater than zero) USE AdventureWorks2012 GO SELECT * FROM [HumanR ...
- Vue.js优雅的实现列表清单的操作
一.Vue.js简要说明 Vue.js (读音 /vjuː/,类似于 view) 是一套构建用户界面的渐进式框架.与前端框架Angular一样, Vue.js在设计上采用MVVM模式,当Vie ...
- 《Linux命令行与shell脚本编程大全》 第八章管理文件系统
8.1 探索linux文件系统 8.1.1 基本的Linux文件系统 ext:最早的文件系统,叫扩展文件系统.使用虚拟目录操作硬件设备,在物理设备上按定长的块来存储数据. 用索引节点的系统来存放虚拟目 ...
- Storm入门之第二章
1.准备开始 本章创建一个Storm工程和第一个Storm拓扑结构. 需要提供JER版本在1.6以上,下载地址http://www.java .com/downloads/. 2.操作模式 Storm ...
- tornado之子模板
#!/usr/bin/env python26 #-*- coding:utf8 -*- import tornado.httpserver import tornado.ioloop import ...
- IIS发布网站浏览之后看到的是文件目录 & Internal Server Error 处理程序“ExtensionlessUrlHandler-ISAPI-4.0_64bit”在其模块列表中有一个错误模块“IsapiModule” 解决方法 & App_global.asax.pduxejp_.dll”--“拒绝访问。 ”
Q:IIS发布网站浏览之后看到的是文件目录 A:它出现了一个说到.NET4.0 更高框架什么的错误,所以我将 .NTE CRL版本由4.0改为2.0了,改为2.0后就出现了只能浏览文件目录了.改为4. ...
- 重温CSS3
基础不牢,地动山摇!没办法,只能重温"经典"! 1.CSS3边框:border-radius; box-shadow; border-image border-radius:r1, ...
- Python基础-数据类型和变量
数据类型 python中包含6种标准数据类型:1.Number 数值类型2.String 字符串类型3.List 列表类型4.Tuple 元祖类型5.Dict 字典类型6.Set 集合类型 注意:除了 ...