Hadoop 之 NameNode 元数据原理
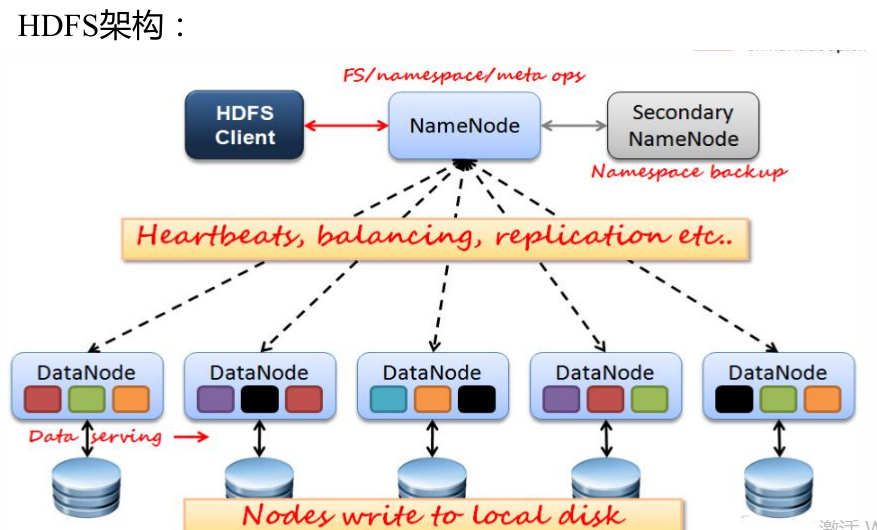
在对NameNode节点进行格式化时,调用了FSImage的saveFSImage()方法和FSEditLog.createEditLogFile()存储当前的元数据。Namenode主要维护两个文件,一个是fsimage,一个是editlog。
fsimage :保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。简单的说,Fsimage就是在某一时刻,整个hdfs 的快照,就是这个时刻hdfs上所有的文件块和目录,分别的状态,位于哪些个datanode,各自的权限,各自的副本个数等。
注意:Block的位置信息不会保存到fsimage,Block保存在哪个DataNode(由DataNode启动时上报)。
editlog :主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
读取元数据:
启动NameNode节点时,又要从镜像和编辑日志中读取元数据。
写入元数据:
在NameNode运行时会将内存中的元数据信息存储到所指定的文件,即${dfs.name.dir}/current目录下的fsimage文件,此外还会将另外一部分对NameNode更改的日志信息存储到${dfs.name.dir}/current目录下的edits文件中。fsimage文件和edits文件可以确定NameNode节点当前的状态,这样在NameNode节点由于突发原因崩溃时,可以根据这两个文件中的内容恢复到节点崩溃前的状态,所以对NameNode节点中内存元数据的每次修改都必须保存下来。但是如果每次都保存到fsimage文件中,这样效率就特别低效,所以引入编辑日志文件edits,保存对对元数据的修改信息,也就是fsimage文件保存NameNode节点中某一时刻内存中的元数据(即目录树),edits保存这一时刻之后的对元数据的更改信息。
镜像的保存:

SecondaryNameNode:主要由两个作用,一是镜像备份(不是NN的备份,但可以做备份),二是日志与镜像的定期合并。
第一步:将hdfs更新记录写入一个新的文件——edits.new。
第二步:将fsimage和editlog通过http协议发送至secondary namenode。
第三步:将fsimage与editlog合并,生成一个新的文件——fsimage.ckpt。这步之所以要在secondary namenode中进行,是因为比较耗时,如果在namenode中进行,或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edits。
第六步:等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在core-site.xml文件中进行配置。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。例如如下:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>
Hadoop 之 NameNode 元数据原理的更多相关文章
- hadoop的Namenode HA原理详解
为什么要Namenode HA? 1. NameNode High Availability即高可用. 2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNod ...
- Hadoop NameNode元数据相关文件目录解析
在<Hadoop NameNode元数据相关文件目录解析>文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件: 1 current/ ...
- Hadoop介绍-4.Hadoop中NameNode、DataNode、Secondary、NameNode、JobTracker TaskTracker
Hadoop是一个能够对大量数据进行分布式处理的软体框架,实现了Google的MapReduce编程模型和框架,能够把应用程式分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行.在MapR ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- Hadoop的RPC通信原理
RPC调用: RPC(remote procedure call)远程过程调用: 不同java进程间的对象方法的调用. 一方称作服务端(server),一方称为客户端(client): server端 ...
- Hadoop的RPC工作原理
RPC远程过程调用: Hadoop的远程过程调用(Remote Procedure Call,RPC)是Hadoop中核心通信机制,RPC主要通过所有Hadoop的组件元数据交换,如MapReduce ...
- Hadoop- NameNode和Secondary NameNode元数据管理机制
元数据的存储机制 A.内存中有一份完整的元数据(内存meta data) B.磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中) C.用于衔接内存metadata ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
随机推荐
- 2017全球互联网技术大会回顾(附PPT)
有幸遇见 GITC2017上海站,刚好遇见你! 为期两天(6.23~24)的GITC大会在上海举行,我有幸参加了24号的那场,也就是上周六,之所以今天才来回顾,是我想等PPT出来后分享给大家! 这应该 ...
- pdf.js在国际化的时候,显示不了中文的解决办法
在项目中使用了pdf实现在线预览功能,开始工具栏中一直都是英文的,在view.js中设置了也不起作用,偶然发现了问题所在 当我把网站发布到iis上的时候,用google浏览器的审查元素功能的审核发现j ...
- 用php+mysql+ajax实现淘宝客服或阿里旺旺聊天功能 之 后台页面
在上一篇随笔中,我们已经看了如何实现前台的对话功能:前台我限定了店主只有一人,店铺只有一个,所有比较单一,但后台就不一样了,而后台更像是我们常见的聊天软件:当然,前台也应该实现这种效果,但原理懂了,可 ...
- python命令行神器Click
原文: http://www.lengirl.com/code/python-click.html Click 是用Python写的一个第三方模块,用于快速创建命令行.我们知道,Python内置了一个 ...
- java中变量赋值的理解
1.当赋值的值超出声明变量的范围时候,会报错! byte a =200 //会报错,因超出范围. byte a =(byte)200;//进行一个强制转换,就不会报错,不过会超出范围,超出部分会从头开 ...
- 字符的读写函数:fgetc()和fputc()
fgetc(); 功能: 从文件中读取字符. 头文件: #include <stdio.h> 函数原型:int fgetc(FILE *stream); 返 ...
- PHP获取文件夹中的所有文件(包括子目录)
方法一: 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 function tree($directory) ...
- Android - 读取JSON文件数据
Android读取JSON文件数据 JSON - JavaScript Object Notation 是一种存储和交换文本信息的语法. JSON对象在花括号中书写.用逗号来分隔值. JSON数组在方 ...
- 【转载】CANoe 入门 Step by step系列(一)基础应用
来源:http://www.cnblogs.com/dongdonghuihui/archive/2012/09/26/2704611.html CANoe是Vector公司的针对汽车电子行业的总线分 ...
- “玲珑杯”ACM比赛 Round #12 (D) 【矩阵快速幂的时间优化】
//首先,感谢Q巨 题目链接 定义状态向量b[6] b[0]:三面临红色的蓝色三角形个数 b[1]:两面临红色且一面临空的蓝色三角形个数 b[2]:一面临红色且两面临空的蓝色三角形个数 b[3]:三面 ...