Hadoop 之 NameNode 元数据原理
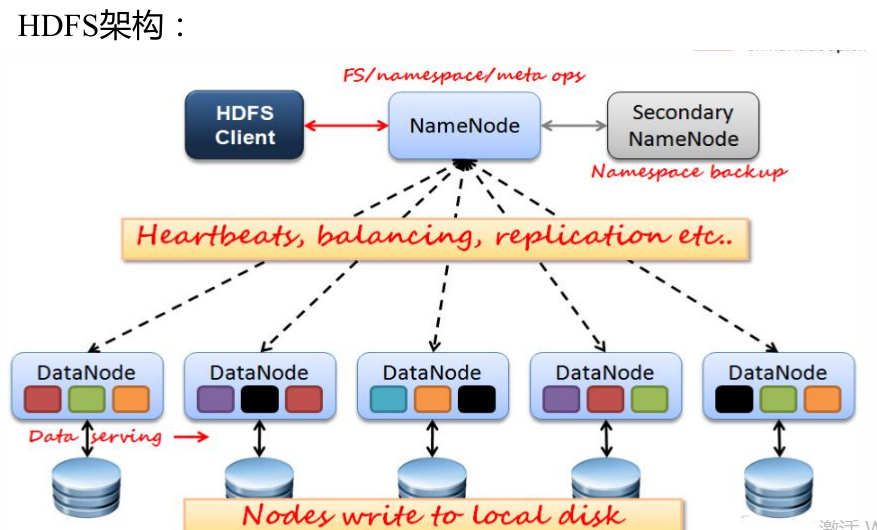
在对NameNode节点进行格式化时,调用了FSImage的saveFSImage()方法和FSEditLog.createEditLogFile()存储当前的元数据。Namenode主要维护两个文件,一个是fsimage,一个是editlog。
fsimage :保存了最新的元数据检查点,包含了整个HDFS文件系统的所有目录和文件的信息。对于文件来说包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。简单的说,Fsimage就是在某一时刻,整个hdfs 的快照,就是这个时刻hdfs上所有的文件块和目录,分别的状态,位于哪些个datanode,各自的权限,各自的副本个数等。
注意:Block的位置信息不会保存到fsimage,Block保存在哪个DataNode(由DataNode启动时上报)。
editlog :主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
读取元数据:
启动NameNode节点时,又要从镜像和编辑日志中读取元数据。
写入元数据:
在NameNode运行时会将内存中的元数据信息存储到所指定的文件,即${dfs.name.dir}/current目录下的fsimage文件,此外还会将另外一部分对NameNode更改的日志信息存储到${dfs.name.dir}/current目录下的edits文件中。fsimage文件和edits文件可以确定NameNode节点当前的状态,这样在NameNode节点由于突发原因崩溃时,可以根据这两个文件中的内容恢复到节点崩溃前的状态,所以对NameNode节点中内存元数据的每次修改都必须保存下来。但是如果每次都保存到fsimage文件中,这样效率就特别低效,所以引入编辑日志文件edits,保存对对元数据的修改信息,也就是fsimage文件保存NameNode节点中某一时刻内存中的元数据(即目录树),edits保存这一时刻之后的对元数据的更改信息。
镜像的保存:

SecondaryNameNode:主要由两个作用,一是镜像备份(不是NN的备份,但可以做备份),二是日志与镜像的定期合并。
第一步:将hdfs更新记录写入一个新的文件——edits.new。
第二步:将fsimage和editlog通过http协议发送至secondary namenode。
第三步:将fsimage与editlog合并,生成一个新的文件——fsimage.ckpt。这步之所以要在secondary namenode中进行,是因为比较耗时,如果在namenode中进行,或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edits。
第六步:等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在core-site.xml文件中进行配置。fs.checkpoint.period表示多长时间记录一次hdfs的镜像。默认是1小时。fs.checkpoint.size表示一次记录多大的size,默认64M。例如如下:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>
Hadoop 之 NameNode 元数据原理的更多相关文章
- hadoop的Namenode HA原理详解
为什么要Namenode HA? 1. NameNode High Availability即高可用. 2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNod ...
- Hadoop NameNode元数据相关文件目录解析
在<Hadoop NameNode元数据相关文件目录解析>文章中提到NameNode的$dfs.namenode.name.dir/current/文件夹的几个文件: 1 current/ ...
- Hadoop介绍-4.Hadoop中NameNode、DataNode、Secondary、NameNode、JobTracker TaskTracker
Hadoop是一个能够对大量数据进行分布式处理的软体框架,实现了Google的MapReduce编程模型和框架,能够把应用程式分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行.在MapR ...
- Namenode HA原理详解(脑裂)
转自:http://blog.csdn.net/tantexian/article/details/40109331 Namenode HA原理详解 社区hadoop2.2.0 release版本开始 ...
- Hadoop数据管理介绍及原理分析
Hadoop数据管理介绍及原理分析 最近2014大数据会议正如火如荼的进行着,Hadoop之父Doug Cutting也被邀参加,我有幸听了他的演讲并获得亲笔签名书一本,发现他竟然是左手写字,当然这个 ...
- Hadoop的RPC通信原理
RPC调用: RPC(remote procedure call)远程过程调用: 不同java进程间的对象方法的调用. 一方称作服务端(server),一方称为客户端(client): server端 ...
- Hadoop的RPC工作原理
RPC远程过程调用: Hadoop的远程过程调用(Remote Procedure Call,RPC)是Hadoop中核心通信机制,RPC主要通过所有Hadoop的组件元数据交换,如MapReduce ...
- Hadoop- NameNode和Secondary NameNode元数据管理机制
元数据的存储机制 A.内存中有一份完整的元数据(内存meta data) B.磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中) C.用于衔接内存metadata ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
随机推荐
- linux下查找某个文件或目录
以查找samba为例:find / -name samba 查找之后得到的结果集如下:/var/lib/samba/var/spool/samba/var/log/samba/usr/lib64/sa ...
- 【Android Developers Training】 98. 获取联系人列表
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- 【Android Developers Training】 41. 向另一台设备发送文件
注:本文翻译自Google官方的Android Developers Training文档,译者技术一般,由于喜爱安卓而产生了翻译的念头,纯属个人兴趣爱好. 原文链接:http://developer ...
- maven仓库--搭建局域网私服(windows版)
使用nexus搭建局域网私服 一. 认识maven仓库 1.1 maven仓库的作用 回想之前不用maven的时候,我们用eclipse原始的项目骨架构建项目时,在工程目录下往往有一个lib文件夹 ...
- 如何编写高效的SQL
编写高效的sql可以给用户带来好的体验,需要开发这没有意识到这一点因为他们不关心也不知道怎么做.高效的sql可以给用户节省很多时间,这样就不需要dba来找上门,也不需要搭建RCA和性能调优. 性能不好 ...
- 基于Json序列化和反序列化通用的封装
1. 最近项目已经上线了 ,闲暇了几天 想将JSON的序列化以及反序列化进行重新的封装一下本人定义为JSONHelp,虽然Microsoft 已经做的很好了.但是我想封装一套为自己开发的项目使用.方便 ...
- SQL Server分页查询方法整理
SQL Server数据库分页查询一直是SQL Server的短板,闲来无事,想出几种方法,假设有表ARTICLE,字段ID.YEAR...(其他省略),数据53210条(客户真实数据,量不大),分页 ...
- kali切换字符界面模式和切换图形界面模式
我也是走了很多弯路,下面把正确的命令写出来,网上的不是说不正确,是linux命令做出了更改 Systemd是一种新的linux系统服务管理器 它替代了init, 直接上命令吧! 切换至字符界面 sud ...
- Java 日志框架终极教程
概述 对于现代的 Java 应用程序来说,只要被部署到真实的生产环境,其日志的重要性就是不言而喻的,很难想象没有任何日志记录功能的应用程序被运行于生产环境中.日志 API 所能提供的功能是多种多样的, ...
- Java项目集成SAP BO
SAP BO报表查看需要登录SAP BO系统,为了方便公司希望将BO报表集成到OA系统中,所以参考网上资料加上与SAP BO的顾问咨询整理出一套通过Java来集成SAP BO的功能. SAPBO中的报 ...