Dinic算法详解及实现
预备知识:
残留网络:设有容量网络G(V,E)及其上的网络流f,G关于f的残留网络即为G(V',E'),其中G’的顶点集V'和G的顶点集V相同,即V'=V,对于G中任何一条弧<u,v>,如果f(u,v)<c(u,v),那么在G'中有一条弧<u,v>∈E',其容量为c'(u,v)=c(u,v)-f(u,v),如果f(u,v)>0,则在G'中有一条弧<v,u>∈E',其容量为c’(v,u)=f(u,v).
从残留网络的定义来看,原容量网络中的每条弧在残留网络中都化为一条或者两条弧。在残留网络中,从源点到汇点的任意一条简单路径都对应一条增光路,路径上每条弧容量的最小值即为能够一次增广的最大流量。
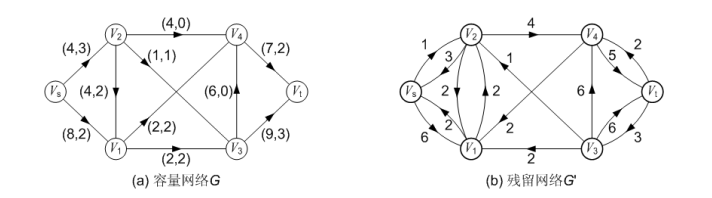
顶点的层次:在残留网络中,把从源点到顶点u的最短路径长度,称为顶点u的层次。源点 Vs的层次为0.例如下图就是一个分层的过程。
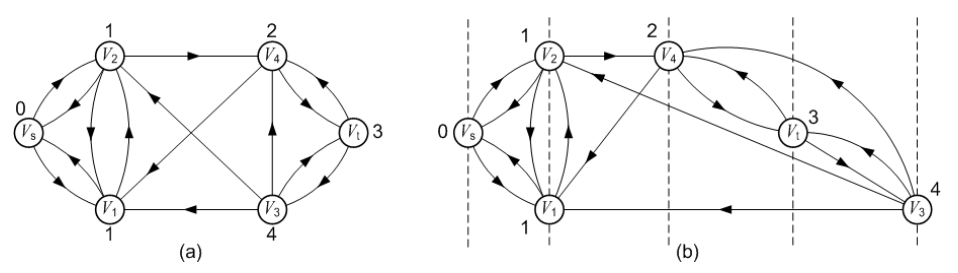
注意:
(1)对残留网路进行分层后,弧可能有3种可能的情况。
1、从第i层顶点指向第i+1层顶点。
2、从第i层顶点指向第i层顶点。
3、从第i层顶点指向第j层顶点(j < i)。
(2)不存在从第i层顶点指向第i+k层顶点的弧(k>=2)。
(3)并非所有的网络都能分层。
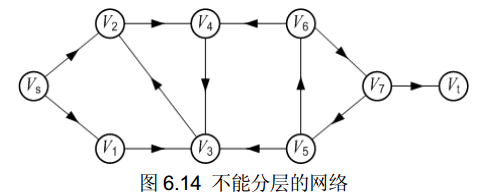
2、最短路增广路径的算法思想
最短增广路的算法思想是:每次在层次网络中找一条含弧数最少的增广路进行增广。最短增广路算法的具体步骤如下:
(1)初始化容量网络和网络流。
(2)构造残留网络和层次网络,若汇点不在层次网络中,则算法结束。
(3)在层次网络中不断用BFS增广,直到层次网络中没有增广路为止;每次增广完毕,在层次网络中要去掉因改进流量而导致饱和的弧。
(4)转步骤(2)。
在最短增广路算法中,第(2)、(3)步被循环执行,将执行(2)、(3)步的一次循环称为一个阶段。在每个阶段中,首先根据残留网络建立层次网络,然后不断用BFS在层次网络中增广,直到出现阻塞流。注意每次增广后,在层次网络中要去掉因改进流量而饱和的弧。该阶段的增广完毕后,进入下一阶段。这样的不断重复,直到汇点不在层次网络中为止。汇点不在层次网络中意味着在残留网络中不存在一条从源点到汇点的路径,即没有增广路。
在程序实现的时候,并不需要真正“构造”层次网络,只需要对每个顶点标记层次,增广的时候,判断边是否满足level(v) = level(u)+1这一约束条件即可。
3、最短增广路算法复杂度分析
最短增广路的复杂度包括建立层次网络和寻找增广路两部分。
在最短增广路中,最多建立n个层次网络,每个层次网络用BFS一次遍历即可得到。一次BFS的复杂度为O(m),所以建层次图的总复杂度为O(n*m)。
每增广一次,层次网络中必定有一条边会被删除。层次网络中最多有m条边,所以认为最多可以增广m次。在最短增广路算法中,用BFS来增广,一次增广的复杂度为O(n+m),其中O(m)为BFS的花费,O(n)为修改流量的花费。所以在每一阶段寻找增广路的复杂度为O(m*(m+n)) = O(m*m)。因此n个阶段寻找增广路的算法总复杂度为O(n*m*m)。
两者之和为O(n*m*m)。
以上介绍最短增广路算法只是为下面介绍Dinic算法而提供给大家一个铺垫,有了以上的基础,接下来我们来介绍Dinic算法,Dinic其实是最短增广路算法的优化版。
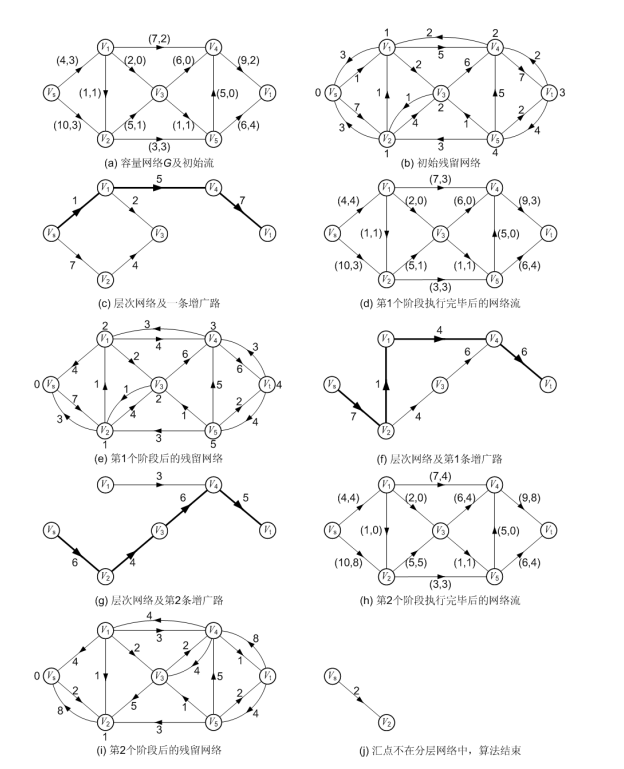
连续最短增广路算法----Dinic算法
1、Dinic算法思路
Dinic算法的思想也是分阶段地在层次网络中增广。它与最短增广路算法不同之处是:最短增广路每个阶段执行完一次BFS增广后,要重新启动BFS从源点Vs开始寻找另一条增广路;而在Dinic算法中,只需一次DFS过程就可以实现多次增广,这是Dinic算法的巧妙之处。Dinic算法具体步骤如下:
(1)初始化容量网络和网络流。
(2)构造残留网络和层次网络,若汇点不再层次网络中,则算法结束。
(3)在层次网络中用一次DFS过程进行增广,DFS执行完毕,该阶段的增广也执行完毕。
(4)转步骤(2)。
在Dinic的算法步骤中,只有第(3)步与最短增广路相同。在下面实例中,将会发现DFS过程将会使算法的效率有非常大的提高。
Dinic算法复杂度分析
与最短增广路算法一样,Dinic算法最多被分为n个阶段,每个阶段包括建层次网络和寻找增广路两部分,其中建立层次网络的复杂度仍是O(n*m)。
现在来分析DFS过程的总复杂度。在每一阶段,将DFS分成两部分分析。
(1)修改增广路的流量并后退的花费。在每一阶段,最多增广m次,每次修改流量的费用为O(n)。而一次增广后在增广路中后退的费用也为O(n)。所以在每一阶段中,修改增广路以及后退的复杂度为O(m*n)。
(2)DFS遍历时的前进与后退。在DFS遍历时,如果当前路径的最后一个顶点能够继续扩展,则一定是沿着第i层的顶点指向第i+1层顶点的边向汇点前进了一步。因为增广路经长度最长为n,所以最坏的情况下前进n步就会遇到汇点。在前进的过程中,可能会遇到没有边能够沿着继续前进的情况,这时将路径中的最后一个点在层次图中删除。
注意到每后退一次必定会删除一个顶点,所以后退的次数最多为n次。在每一阶段中,后退的复杂度为O(n)。
假设在最坏的情况下,所有的点最后均被退了回来,一共共后退了n次,这也就意味着,有n次的前进被“无情”地退了回来,这n次前进操作都没有起到“寻找增广路”的作用。除去这n次前进和n次后退,其余的前进都对最后找到增广路做了贡献。增广路最多找到m次。每次最多前进n个点。所以所有前进操作最多为n+m*n次,复杂度为O(n*m)。
于是得到,在每一阶段中,DFS遍历时前进与后退的花费为O(m*n)。
综合以上两点,一次DFS的复杂度为O(n*m)。因此,Dinic算法的总复杂度即O(m*n*n)。

下面的实现,有借鉴别人的方法。主要是利用BFS构建层次网络,这里用level数组来存储每个顶点的层数。
然后利用dfs进行增广,默认M个节点,第M个节点就是汇点。然后当第M个节点不在分层网络时,就结束。
#include <iostream>
#include <queue>
using namespace std; const int INF = 0x7fffffff;
int V, E;
int level[];
int Si, Ei, Ci; struct Dinic
{
int c;
int f;
}edge[][]; bool dinic_bfs() //bfs方法构造层次网络
{
queue<int> q;
memset(level, , sizeof(level));
q.push();
level[] = ;
int u, v;
while (!q.empty()) {
u = q.front();
q.pop();
for (v = ; v <= E; v++) {
if (!level[v] && edge[u][v].c>edge[u][v].f) {
level[v] = level[u] + ;
q.push(v);
}
}
}
return level[E] != ; //question: so it must let the sink node is the Mth?/the way of yj is give the sink node's id
} int dinic_dfs(int u, int cp) { //use dfs to augment the flow
int tmp = cp;
int v, t;
if (u == E)
return cp;
for (v = ; v <= E&&tmp; v++) {
if (level[u] + == level[v]) {
if (edge[u][v].c>edge[u][v].f) {
t = dinic_dfs(v, min(tmp, edge[u][v].c - edge[u][v].f));
edge[u][v].f += t;
edge[v][u].f -= t;
tmp -= t;
}
}
}
return cp - tmp;
}
int dinic() {
int sum=, tf=;
while (dinic_bfs()) {
while (tf = dinic_dfs(, INF))
sum += tf;
}
return sum;
} int main() {
while (scanf("%d%d", &V, &E)) {
memset(edge, , sizeof(edge));
while (V--) {
scanf("%d%d%d", &Si, &Ei, &Ci);
edge[Si][Ei].c += Ci;
}
int ans = dinic();
printf("%d\n", ans);
}
return ;
}
Dinic算法详解及实现的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- JVM总结之命令行工具
jps jps位于jdk的bin目录下,其作用是显示当前系统的java进程情况,及其id号. jps相当于Solaris进程工具ps.不象"pgrep java"或"ps ...
- hasOwnProperty的用法
判断一个属性倒底是在原型中,还是在实例中 hasOwnProperty() 来个栗子 function Person(){ }; Person.prototype.name = "hezhi ...
- 记一次SAP新业务开发项目
直到笔者写这篇博文的时候,这个开发项目名义上已经上线,但其实开发以及优化的工作还在继续,数据的修复也仍在继续... IT系统环境很简单,一个基于JAVA+Mysql的Web平台,一个是宇宙第一的SAP ...
- Microsoft office2010页码设置----论文、课程设计报告格式
思想:将目录页(含目录页)与目录页以下的页面用分隔符分隔开,单独设置目录页以下的页面页码,删除目录页(含目录)以前的页码. 1.在目录页页面内容最下面一行插入分隔符,实现与下面页面分隔开的目的. 页面 ...
- 合格的IT人士需要养成的习惯:设置系统还原点
系统还原可帮助您将计算机的系统文件及时还原到早期的还原点.此方法可以在不影响个人文件(比如电子邮件.文档.照片等)的情况下,撤销对计算机的系统更改.有时,安装一个程序或驱动程序会导致对计算机的异常更改 ...
- data-packed volume container - 每天5分钟玩转 Docker 容器技术(43)
在上一节的例子中 volume container 的数据归根到底还是在 host 里,有没有办法将数据完全放到 volume container 中,同时又能与其他容器共享呢? 当然可以,通常我们称 ...
- 实时音视频互动系列(下):基于 WebRTC 技术的实战解析
在 WebRTC 项目中,又拍云团队做到了覆盖系统全局,保证项目进程流畅.这牵涉到主要三大块技术点: 网络端.服务端的开发和传输算法 WebRTC 协议中牵扯到服务端的应用协议和信令服务 客户端iOS ...
- neo4j 数据库导入导出
工作中需要将 A 图数据库的数据完全导出,并插入到 B 图数据库中.查找资料,好多都是通过导入,导出 CSV 文件来实现.然而,经过仔细研究发现,导出的节点/关系 都带有 id 属性 ,因为 A B ...
- iOS 模式详解—「runtime面试、工作」看我就 🐒 了 ^_^.
引导 Copyright © PBwaterln Unauthorized shall not be *copy reprinted* . 对于从事 iOS 开发人员来说,所有的人都会答出「runti ...
- gdb命令中查看地址之x命令
可以使用examine命令(简写是x)来查看内存地址中的值.x命令的语法如下所示: x/<n/f/u> <addr> n.f.u是可选的参数. n是一个正整数,表示需要显示的内 ...