ElasticSearch 集群监控
要监控哪些 ElasticSearch metrics?
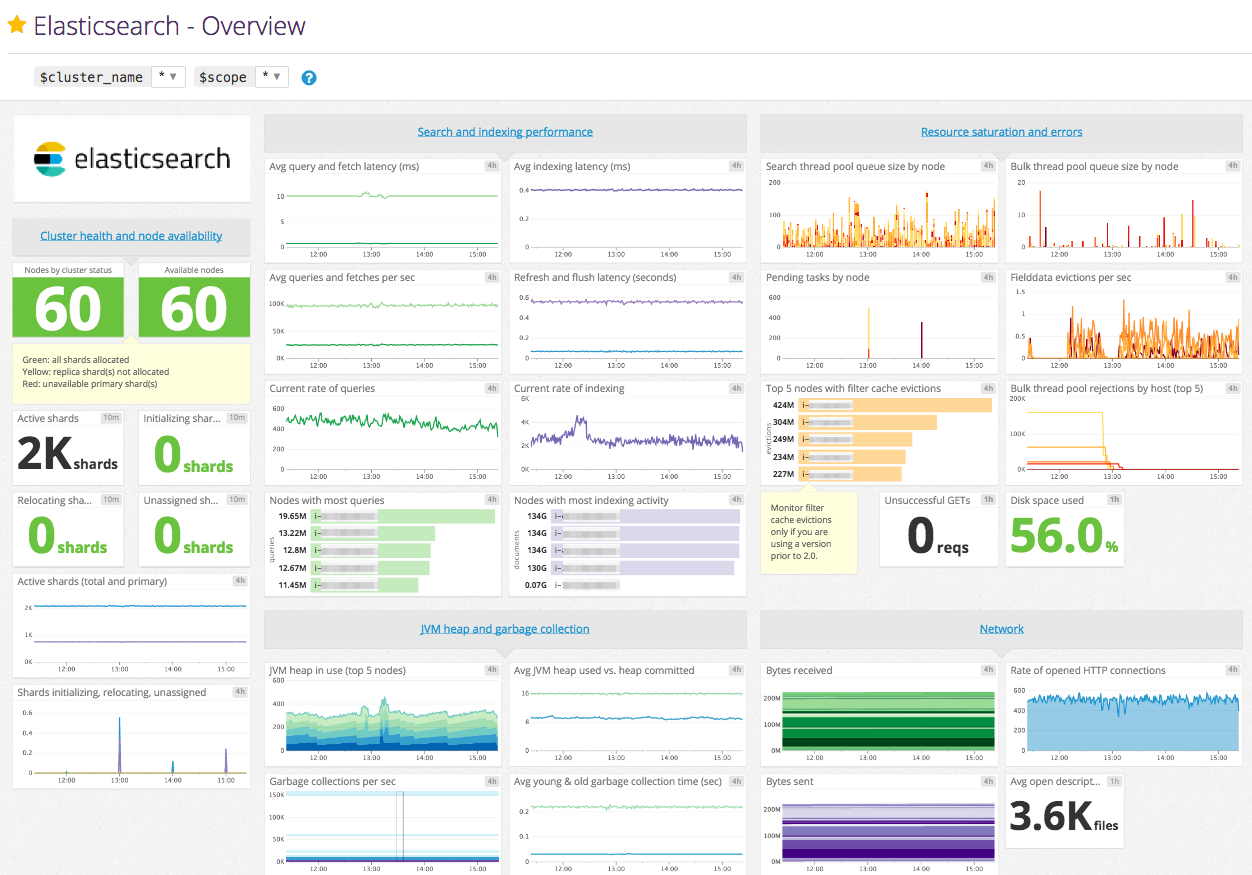
Elasticsearch 提供了大量的 Metric,可以帮助您检测到问题的迹象,在遇到节点不可用、out-of-memory、long garbage collection times 的时候采取相应措施。但是指标太多了,有时我们并不需要这么多,这就需要我们进行筛选。
集群健康
一个 Elasticsearch 集群至少包括一个节点和一个索引。或者它 可能有一百个数据节点、三个单独的主节点,以及一小打客户端节点——这些共同操作一千个索引(以及上万个分片)。
不管集群扩展到多大规模,你都会想要一个快速获取集群状态的途径。Cluster Health API 充当的就是这个角色。你可以把它想象成是在一万英尺的高度鸟瞰集群。它可以告诉你安心吧一切都好,或者警告你集群某个地方有问题。
让我们执行一下 cluster-health API 然后看看响应体是什么样子的:
GET _cluster/health
和 Elasticsearch 里其他 API 一样,cluster-health 会返回一个 JSON 响应。这对自动化和告警系统来说,非常便于解析。响应中包含了和你集群有关的一些关键信息:
{
"cluster_name": "elasticsearch_zach",
"status": "green",
"timed_out": false,
,
,
,
,
,
,
}
响应信息中最重要的一块就是 status 字段。状态可能是下列三个值之一:

number_of_nodes 和 number_of_data_nodes 这个命名完全是自描述的。
active_primary_shards 指出你集群中的主分片数量。这是涵盖了所有索引的汇总值。
active_shards 是涵盖了所有索引的所有分片的汇总值,即包括副本分片。
relocating_shards 显示当前正在从一个节点迁往其他节点的分片的数量。通常来说应该是 0,不过在 Elasticsearch 发现集群不太均衡时,该值会上涨。比如说:添加了一个新节点,或者下线了一个节点。
initializing_shards 是刚刚创建的分片的个数。比如,当你刚创建第一个索引,分片都会短暂的处于 initializing 状态。这通常会是一个临时事件,分片不应该长期停留在 initializing状态。你还可能在节点刚重启的时候看到 initializing 分片:当分片从磁盘上加载后,它们会从initializing 状态开始。
unassigned_shards 是已经在集群状态中存在的分片,但是实际在集群里又找不着。通常未分配分片的来源是未分配的副本。比如,一个有 5 分片和 1 副本的索引,在单节点集群上,就会有 5 个未分配副本分片。如果你的集群是 red 状态,也会长期保有未分配分片(因为缺少主分片)。
集群统计
集群统计信息包含 集群的分片数,文档数,存储空间,缓存信息,内存作用率,插件内容,文件系统内容,JVM 作用状况,系统 CPU,OS 信息,段信息。
查看全部统计信息命令:
curl -XGET 'http://localhost:9200/_cluster/stats?human&pretty'
返回 JSON 结果:
{
,
"cluster_name": "elasticsearch",
"status": "green",
"indices": {
,
"shards": {
,
,
,
"index": {
"shards": {
,
,
},
"primaries": {
,
,
},
"replication": {
,
,
}
}
},
"docs": {
,
},
"store": {
"size": "16.2kb",
,
"throttle_time": "0s",
},
"fielddata": {
"memory_size": "0b",
,
},
"query_cache": {
"memory_size": "0b",
,
,
,
,
,
,
},
"completion": {
"size": "0b",
},
"segments": {
,
"memory": "8.6kb",
,
"terms_memory": "6.3kb",
,
"stored_fields_memory": "1.2kb",
,
"term_vectors_memory": "0b",
,
"norms_memory": "384b",
,
"doc_values_memory": "744b",
,
"index_writer_memory": "0b",
,
"version_map_memory": "0b",
,
"fixed_bit_set": "0b",
,
"file_sizes": {}
},
"percolator": {
}
},
"nodes": {
"count": {
,
,
,
,
},
"versions": [
"5.6.3"
],
"os": {
,
,
"names": [
{
"name": "Mac OS X",
}
],
"mem" : {
"total" : "16gb",
,
"free" : "78.1mb",
,
"used" : "15.9gb",
,
,
}
},
"process": {
"cpu": {
},
"open_file_descriptors": {
,
,
}
},
"jvm": {
"max_uptime": "13.7s",
,
"versions": [
{
"version": "1.8.0_74",
"vm_name": "Java HotSpot(TM) 64-Bit Server VM",
"vm_version": "25.74-b02",
"vm_vendor": "Oracle Corporation",
}
],
"mem": {
"heap_used": "57.5mb",
,
"heap_max": "989.8mb",
},
},
"fs": {
"total": "200.6gb",
,
"free": "32.6gb",
,
"available": "32.4gb",
},
"plugins": [
{
"name": "analysis-icu",
"version": "5.6.3",
"description": "The ICU Analysis plugin integrates Lucene ICU module into elasticsearch, adding ICU relates analysis components.",
"classname": "org.elasticsearch.plugin.analysis.icu.AnalysisICUPlugin",
"has_native_controller": false
},
{
"name": "ingest-geoip",
"version": "5.6.3",
"description": "Ingest processor that uses looksup geo data based on ip adresses using the Maxmind geo database",
"classname": "org.elasticsearch.ingest.geoip.IngestGeoIpPlugin",
"has_native_controller": false
},
{
"name": "ingest-user-agent",
"version": "5.6.3",
"description": "Ingest processor that extracts information from a user agent",
"classname": "org.elasticsearch.ingest.useragent.IngestUserAgentPlugin",
"has_native_controller": false
}
]
}
}
内存使用和 GC 指标
在运行 Elasticsearch 时,内存是您要密切监控的关键资源之一。 Elasticsearch 和 Lucene 以两种方式利用节点上的所有可用 RAM:JVM heap 和文件系统缓存。 Elasticsearch 运行在Java虚拟机(JVM)中,这意味着JVM垃圾回收的持续时间和频率将成为其他重要的监控领域。
上面返回的 JSON监控的指标有我个人觉得有这些:
nodes.successful nodes.failed nodes.total nodes.mem.used_percent nodes.process.cpu.percent nodes.jvm.mem.heap_used
可以看到 JSON 文件是很复杂的,如果从这复杂的 JSON 中获取到对应的指标(key)的值呢,这里看文章 :JsonPath —— JSON 解析神器
本文主要讲述ES 集群的一些监控信息,有些监控指标是个人觉得需要监控的,但是具体情况还是得看需求了。
原文地址:http://www.roncoo.com/article/index
ElasticSearch 集群监控的更多相关文章
- Elasticsearch 集群和索引健康状态及常见错误说明
之前在IDC机房线上环境部署了一套ELK日志集中分析系统, 这里简单总结下ELK中Elasticsearch健康状态相关问题, Elasticsearch的索引状态和集群状态传达着不同的意思. 一. ...
- Prometheus监控elasticsearch集群(以elasticsearch-6.4.2版本为例)
部署elasticsearch集群,配置文件可"浓缩"为以下: cluster.name: es_cluster node.name: node1 path.data: /app/ ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Elasticsearch集群搭建
现有两部机器:192.168.31.86,192.168.31.87 参考以往博文对Elasticsearch进行配置完成:http://www.cnblogs.com/zhongshengzhe ...
- 实战之elasticsearch集群及filebeat server和logstash server
author:JevonWei 版权声明:原创作品 实战之elasticsearch集群及filebeat server和logstash server 环境 elasticsearch集群节点环境为 ...
- CentOS下 elasticsearch集群安装
1.进入root目录并下载elasticsearch cd /root wget https://download.elastic.co/elasticsearch/elasticsearch/ela ...
- Docker部署Elasticsearch集群
http://blog.sina.com.cn/s/blog_8ea8e9d50102wwik.html Docker部署Elasticsearch集群 参考文档: https://hub.docke ...
- Elasticsearch从入门到精通之Elasticsearch集群内的原理
上一章节我介绍了Elasticsearch安装与运行,本章节及后续章节将全方位介绍 Elasticsearch 的工作原理 在这个章节中,我将会再进一步介绍 cluster . node . shar ...
- Elasticsearch 集群 单服务器 超级详细教程
前言 之前了解了Elasticsearch的基本概念.将spring boot + ElasticSearch + head插件 搞通之后.紧接着对es进行下一步的探索:集群.查阅资料的过程中,找到了 ...
随机推荐
- 为什么MOBA、“吃鸡”游戏不推荐用tcp协议——实测数据
欢迎大家前往云加社区,获取更多腾讯海量技术实践干货哦~ 作者:腾讯云游戏行业资深架构师 余国良 MOBA类和"吃鸡"游戏为什么对网络延迟要求高? 我们知道,不同类型的游戏因为玩法. ...
- 浅析node.js
大家好,今天来给大家讨论node.js这个东西,说起这个东西啊,可能大家已经很熟悉了,因为现在市场上运用的越来越广泛,毕竟它的优点还是有目共睹的! 那么,什么是node.js呢?官方给出了这样的定义: ...
- matplotlib简介及安装
官网介绍: Matplotlib is a Python 2D plotting library which produces publication quality figures in a var ...
- zTree多条件模糊查询
function searchFun() { var zTrees=$.fn.zTree.getZTreeObj("ztree");//获得所有几点 var hiddenNodes ...
- Pycharm配置(一)
Pycharm作为一款强力的Python IDE,在使用过程中感觉一直找不到全面完整的参考手册,因此决定对官网的Pycharm教程进行简要翻译,与大家分享. 1.准备工作 官网下载 2.如何选择Pyc ...
- JMeter脚本java代码String数组要写成String[] args,不能写成String args[],否则报错。
JMeter脚本java代码String数组中括号要写在类型关键字后面,不能写在变量名后面.
- SQL Server 服务器主体拥有一个或多个端点无法删除;错误15141
一.问题描述 当前数据库实例之前已经加入过一个域环境同时也是alwayson集群的一个副本,现在已经退出了以前的域加入一个新域,而且配置的数据库启动服务的域用户和密码和之前的一样.重新使用之前已经存在 ...
- GitLab配置ssh key
一.背景 当前很多公司都选择git作为代码版本控制工具,然后自己公司搭建私有的gitlab来管理代码,我们在clone代码的时候可以选择http协议,当然我们亦可以选择ssh协议来拉取代码.但是网上很 ...
- SQL基本查询_子查询(实验四)
SQL基本查询_子查询(实验四) 1.查询所有员工中薪水低于"孙军"的员工姓名和薪水: 2.查询与部门编号为"01"的岗位相同的员工姓名.岗位.薪水及部门号: ...
- 程序员的自我救赎---11.1:RPC接口使用规范
<前言> (一) Winner2.0 框架基础分析 (二)PLSQL报表系统 (三)SSO单点登录 (四) 短信中心与消息中心 (五)钱包系统 (六)GPU支付中心 (七)权限系统 (八) ...