YARN中FIFO、Capacity以及Fari调度器的详细介绍
(1)FIFO Scheduler
将所有的Applications放到队列中,先按照作业的优先级高低、再按照到达时间的先后,为每个app分配资源。如果第一个app需要的资源被满足了,如果还剩下了资源并且满足第二个app需要的资源,那么就为第二个app分配资源,and so on。
优点:简单,不需要配置。
缺点:不适合共享集群。如果有大的app需要很多资源,那么其他app可能会一直等待。
一个例子
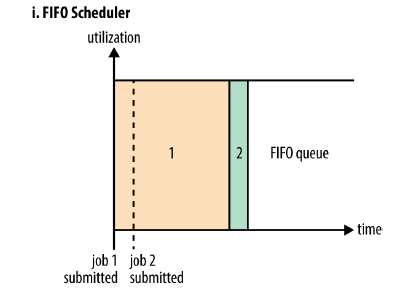
上图的示例:有一个很大的job1,它先提交,并且占据了全部的资源。那么job2提交时发现没有资源了,则job2必须等待job1执行结束,才能获得资源执行。
配置
FIFO Scheduler不需要配置
(2)Capacity Scheduler
CapacityScheduler用于一个集群(集群被多个组织共享)中运行多个Application的情况,目标是最大化吞吐量和集群利用率。
CapacityScheduler允许将整个集群的资源分成多个部分,每个组织使用其中的一部分,即每个组织有一个专门的队列,每个组织的队列还可以进一步划分成层次结构(Hierarchical Queues),从而允许组织内部的不同用户组的使用。
每个队列内部,按照FIFO的方式调度Applications。当某个队列的资源空闲时,可以将它的剩余资源共享给其他队列。
if there is more than one job in the queue and there are idle resources available, then the Capacity Scheduler may allocate the spare resources to jobs in the queue, even if that causes the queue’s capacity to be exceeded This behavior is known as queue elasticity.
配置
CapacityScheduler的配置文件etc/hadoop/capacity-scheduler.xml
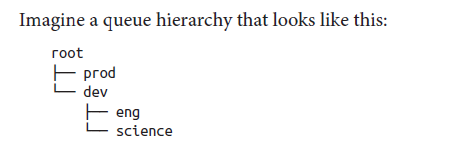

说明:root队列下面有两个队列,分别为prod(40%的容量,即使用40%的集群资源)和dev(60%的容量,最大的75% -> 说明即使prod队列空闲了,那么dev最多只能使用75%的集群资源。这样就可以保证prod中添加新的apps时马上可以使用25%的资源)。
除了队列的容量和层次,还可以指定单个用户或者应用被分配的资源大小、同时可以运行的app数量、队列的ACLs。
可以指定app要放在哪个队列中。如果不指定,app将会被放在名字是 default的队列中。
CapacityScheduler的队列名字必须是层次结构最后的名字,比如eng。不能是root.dev.eng或者dev.eng。
一个例子

上图的示例:有一个专门的队列允许小的apps提交之后能够尽快执行,注意到job1先提交,先执行时并没有占用系统的全部资源(假如job1需要100G内存,但是整个集群只有100G内存,那么只分配给job1 80G),而是保留了一部分的系统资源。
(3)Fair Scheduler
FairScheduler允许应用在一个集群中公平地共享资源。默认情况下FairScheduler的公平调度只基于内存,也可以配置成基于memory and CPU。当集群中只有一个app时,它独占集群资源。当有新的app提交时,空闲的资源被新的app使用,这样最终每个app就会得到大约相同的资源。可以为不同的app设置优先级,决定每个app占用的资源百分比。FairScheduler可以让短的作业在合理的时间内完成,而不必一直等待长作业的完成。
Fair Sharing: Scheduler将apps组织成queues,将资源在这些queues之间公平分配。默认情况下,所有的apps都加入到名字为“default“的队列中。app也可以指定要加入哪个队列中。队列内部的默认调度策略是基于内存的共享策略,也可以配置成FIFO和multi-resource with Dominant Resource Fairness
Minimum Sharing:FairScheduller提供公平共享,还允许指定minimum shares to queues,从而保证所有的用户以及Apps都能得到足够的资源。如果有的app用不了指定的minimum的资源,那么可以将超出的资源分给别的app使用。
FairScheduler默认让所有的apps都运行,但是也可以通过配置文件小智每个用户以及每个queue运行的apps的数量。这是针对一个用户一次提交hundreds of apps产生大量中间结果数据或者大量的context-switching的情况。
一个例子

示例1:大的任务job1提交并执行,占用了集群的全部资源,开始执行。之后小的job2执行时,获得系统一半的资源,开始执行。因此每个job可以公平地使用系统的资源。当job2执行完毕,并且集群中没有其他的job加入时,job1又可以获得全部的资源继续执行。
注意:job2提交之后并不能马上就获取到集群一半的资源,因为job2必须等待job1释放containers。
一个例子
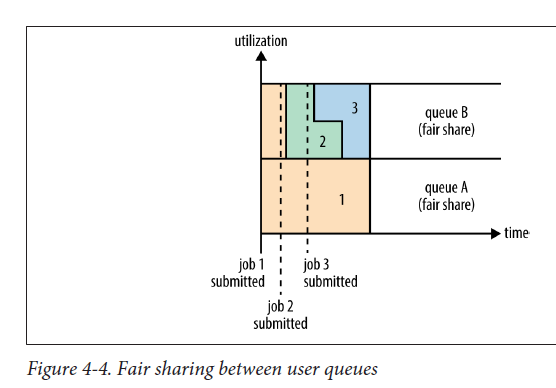
示例2:两个用户A和B。A提交job1时集群内没有正在运行的app,因此job1独占集群中的资源。用户B的job2提交时,job2在job1释放一半的containers之后,开始执行。job2还没执行完的时候,用户B提交了job3,job2释放它占用的一半containers之后,job3获得资源开始执行。
配置:
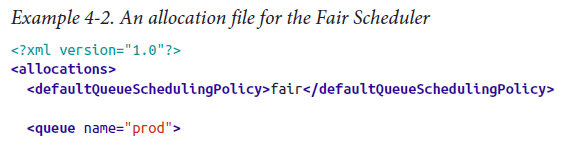

使用FairScheduler需要修改yarn-size.xml文件,创建allocation file,列出存在的队列和各自的 weights and capacities
prod和dev的权重也可以设置成2和3。
dev下的两个sub-queue没有指定权重,则为1:1。
在设置权重时,需要考虑default queue和用户命名的queue的权重,这些没有在xml文件中指定,但是它们的权重都是1.
队列还可以被配置minimum maximum Resources以及可以运行的最大的apps的数量
FairScheduler支持preemption(抢占),当queue占用的资源大于它应得的,那么调度器可以杀掉queue对应的containers,将yarn.scheduler.fair.preemption设置成true即可。
FairScheduler和CapacityScheduler的异同
相同:
(1)以队列划分资源
(2)设定最低保证和最大使用上限
(3)在某个队列空闲时可以将资源共享给其他队列。
不同:
(1)Fair Scheduler队列内部支持多种调度策略,包括FIFO、Fair(队列中的N个作业,每个获得该队列1 / N的资源)、DRF(Dominant Resource Fairness)(多种资源类型e.g. CPU,内存 的公平资源分配策略)
(2)Fair Scheduler支持资源抢占。当队列中有新的应用提交时,系统调度器理应为它回收资源,但是考虑到共享的资源正在进行计算,所以调度器采用先等待再强制回收的策略,即等待一段时间后入股仍没有获得资源,那么从使用共享资源的队列中杀死一部分任务
(3)Fair Scheduler中有一个基于任务数量的负载均衡机制,该机制尽可能将系统中的任务分配到各个节点
(4)Fair Scheduler可以为每个队列单独设置调度策略(FIFO Fair DRF)
(5)Fair Scheduler由于可以采用Fair算法,因此可以使得小应用快速获得资源,避免了饿死的情况。
Hierarchical queues with pluggable policies
FairScheduler支持层次队列(hierarchical queues),所有队列都从root队列开始,root队列的孩子队列公平地共享可用的资源。孩子队列再把可用资源公平地分配给他们的孩子队列。apps可能只会在叶子队列被调度。此外,用户可以为每个队列设置不同的共享资源的策略,内置的队列策略包括 FifoPolicy, FairSharePolicy (default), and DominantResourceFairnessPolicy。
用户可以通过继承org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy实现自己定义的策略。
(4)Delay Scheduling&Dominant Resource Fairness
CapacityScheduler和FairScheduler都支持Delay Scheduling和DRF
不同的apps对CPU和内存的需求量不一样,有的可能需要大量的CPU和一点点内存,有的可能正相反。这会使调度变得复杂。YARN解决的方法是Dominant Resource Fairness,即看app主要需要的资源是什么,用它作为该app对集群使用的度量。
参考:
(1)《Hadoop The Definitive Guide 4th》
(2)官方文档
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
YARN中FIFO、Capacity以及Fari调度器的详细介绍的更多相关文章
- yarn的学习之2-容量调度器和预订系统
本文翻译自 http://hadoop.apache.org/docs/r2.8.0/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html 和http ...
- 二 Capacity Scheduler 计算能力调度器
官网的写的太难懂,参考:http://www.360doc.com/content/14/0603/14/14935022_383254798.shtml Capacity Scheduler 一种可 ...
- golang中GPM模型原理与调度器设计策略
一.GMP模型原理first: 1. 全局队列:存放待运行的G2. P的本地队列:同全局队列类似,存放待运行的G,存储的数量有限:256个,当创建新的G'时,G'优先加入到P的本地队列,如果队列已满, ...
- Linux IO调度器相关算法介绍(转)
IO调度器(IO Scheduler)是操作系统用来决定块设备上IO操作提交顺序的方法.存在的目的有两个,一是提高IO吞吐量,二是降低IO响应时间.然而IO吞吐量和IO响应时间往往是矛盾的,为了尽量平 ...
- 网卡配置和DNS配置,手动挂在nas存储的共享目录,网络相关其它操作命令,修改防火墙中的端口配置,resolv.conf配置详细介绍和网卡信息配置详细介绍
1. 网卡配置和DNS配置 若想服务器能够发邮件,需要让部署的服务器能够访问到外网环境.若部署的服务器访问不到外网,通过ping www.baidu.com的方式执行的时候,会出现以下问题: &q ...
- 大数据调度工具oozie详细介绍
背景 之前项目中的sqoop等离线数据迁移job都是利用shell脚本通过crontab进行定时执行,这样实现的话比较简单,但是随着多个job复杂度的提升,无论是协调工作还是任务监控都变得麻烦,我们选 ...
- 『动善时』JMeter基础 — 20、JMeter配置元件【HTTP Cookie管理器】详细介绍
目录 1.HTTP Cookie管理器介绍 2.HTTP Cookie管理器界面详解 3.JMeter中对Cookie的管理 (1)Cookie的存储 (2)Cookie的管理策略 4.补充:Cook ...
- CSS中 Padding和Margin两个属性的详细介绍和举例说明
代码示例: <!doctype html> <html lang="en"> <head> <meta charset="UTF ...
- java中的IO处理和使用,API详细介绍(二)
字符流 [向文件中写入数据] 现在我们使用字符流 /** * 字符流 * 写入数据 * */ import java.io.*; class hello{ public static void mai ...
随机推荐
- 关于JQuery的绑定方法
从jQuery1.7开始,jQuery引入了全新的事件绑定机制,on()和off()两个函数统一处理事件绑定.因为在此之前有bind(), live(), delegate()等方法来处理事件绑定,j ...
- swift 创建九宫格在后面加按钮
项目中的需求是前面图片,在图片最后面始终有按钮如图 图片 let space:CGFloat = 10 for i in 0..model.count{ let itemWidth:CGFloat = ...
- alpha冲刺第六天
一.合照 二.项目燃尽图 三.项目进展 主界面首页内容呈现 我的栏目之我的问题完成 我的栏目之我的提问完成 还是插不进去,然后打算先放一放,一直在一个地方纠结那么久脑子太乱 四.明日规划 问答界面问题 ...
- c语言第1次作业
一.PTA实验作业 题目1:7-3 温度转换 本题要求编写程序,计算华氏温度150°F对应的摄氏温度.计算公式:C=5×(F−32)/9,式中:C表示摄氏温度,F表示华氏温度,输出数据要求为整型. 1 ...
- nyoj VF
VF 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描述 Vasya is the beginning mathematician. He decided to make ...
- 《javascript设计模式与开发实践》阅读笔记(13)—— 职责链模式
职责链模式 使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止. 书里的订单的例子 假设我们负责一个售卖手机 ...
- JAVA_SE基础——31.this关键字
黑马程序员入学blog... 也算是学习笔记体会. this的通俗解释: 有一个A类,一个B方法,一个C变量,其中B和C都在类A中 this.B()就是调用A类中的B方法 this.C=1(假设C是一 ...
- ( 转 ) CORS 有一次 OPTIONS 请求的原理
刚接触前端的时候,以为HTTP的Request Method只有GET与POST两种,后来才了解到,原来还有HEAD.PUT.DELETE.OPTIONS-- 目前的工作中,HEAD.PUT.DELE ...
- wpf研究之道——datagrid控件分页
这是我们的datagrid分页效果图,有上一页,下一页,可以跳到任何一页.当页码比较多的时候,只显示几页,其余用点点,界面实现如下: <!--分页--> <StackPanel Or ...
- JavaScript 基础学习1-day14
JavaScript 基础学习1 知识预览JavaScript概述二 JavaScript的基础三 JavaScript的对象BOM对象DOM对象实例练习js扩展 JavaScript概述 JavaS ...