JDK源码分析(11)之 BlockingQueue 相关
本文将主要结合源码对 JDK 中的阻塞队列进行分析,并比较其各自的特点;
一、BlockingQueue 概述
说到阻塞队列想到的第一个应用场景可能就是生产者消费者模式了,如图所示;
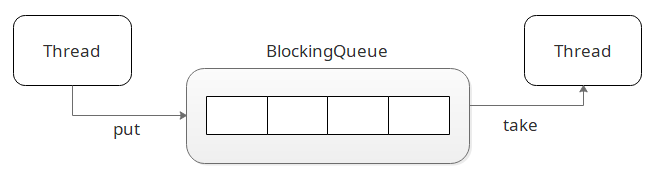
根据上图所示,明显在入队和出队的时候,会发生竞争;所以一种很自然的想法就是使用锁,而在 JDK 中也的确是通过锁来实现的;所以 BlockingQueue 的源码其实可以当成锁的应用示例来查看;同时 JDK 也为我们提供了多种不同功能的队列:
- ArrayBlockingQueue :基于数组的有界队列;
- LinkedBlockingQueue :基于链表的无界队列(可以设置容量);
- PriorityBlockingQueue :基于二叉堆的无界优先级队列;
- DelayQueue :基于 PriorityBlockingQueue 的无界延迟队列;
- SynchronousQueue :无容量的阻塞队列(Executors.newCachedThreadPool() 中使用的队列);
- LinkedTransferQueue :基于链表的无界队列;
接下来我们就对最常用的 ArrayBlockingQueue 和 LinkedBlockingQueue 进行分析;
二、 ArrayBlockingQueue 源码分析
1. 结构概述
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
final Object[] items; // 容器数组
int takeIndex; // 出队索引
int putIndex; // 入队索引
int count; // 排队个数
final ReentrantLock lock; // 全局锁
private final Condition notEmpty; // 出队条件队列
private final Condition notFull; // 入队条件队列
...
}
ArrayBlockingQueue 的结构如图所示:
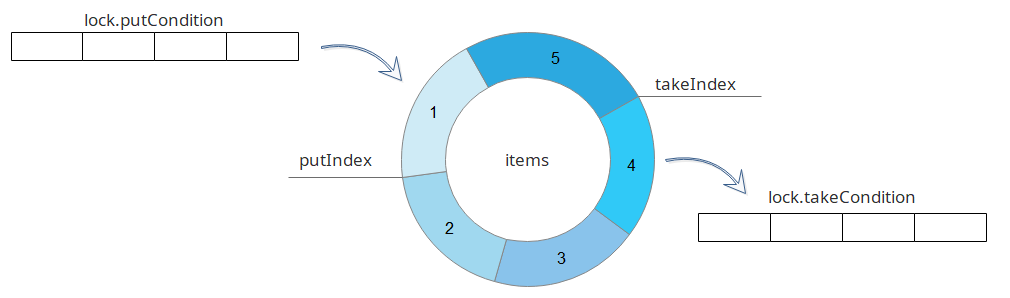
如图所示,
ArrayBlockingQueue的数组其实是一个逻辑上的环状结构,在添加、取出数据的时候,并没有像ArrayList一样发生数组元素的移动(当然除了removeAt(final int removeIndex));- 并且由
takeIndex和putIndex指示读写位置; - 在读写的时候还有两个读写条件队列;
下面我们就读写操作,对源码简单分析:
2. 入队
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length) // 当队列已满的时候放入 putCondition 条件队列
notFull.await();
enqueue(e); // 入队
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x; // 插入队列
if (++putIndex == items.length) putIndex = 0; // 指针走一圈的时候复位
count++;
notEmpty.signal(); // 唤醒 takeCondition 条件队列中等待的线程
}
3. 出队
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) // 当队列为空的时候,放入 takeCondition 条件
notEmpty.await();
return dequeue(); // 出队
} finally {
lock.unlock();
}
}
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex]; // 取出元素
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal(); // 取出元素后,队列空出一位,所以唤醒 putCondition 中的线程
return x;
}
三、LinkedBlockingQueue 源码分析
1. 结构概述
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
private final int capacity; // 默认 Integer.MAX_VALUE
private final AtomicInteger count = new AtomicInteger(); // 容量
transient Node<E> head; // 头结点 head.item == null
private transient Node<E> last; // 尾节点 last.next == null
private final ReentrantLock takeLock = new ReentrantLock(); // 出队锁
private final Condition notEmpty = takeLock.newCondition(); // 出队条件
private final ReentrantLock putLock = new ReentrantLock(); // 入队锁
private final Condition notFull = putLock.newCondition(); // 入队条件
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
}
LinkedBlockingQueue 的结构如图所示:
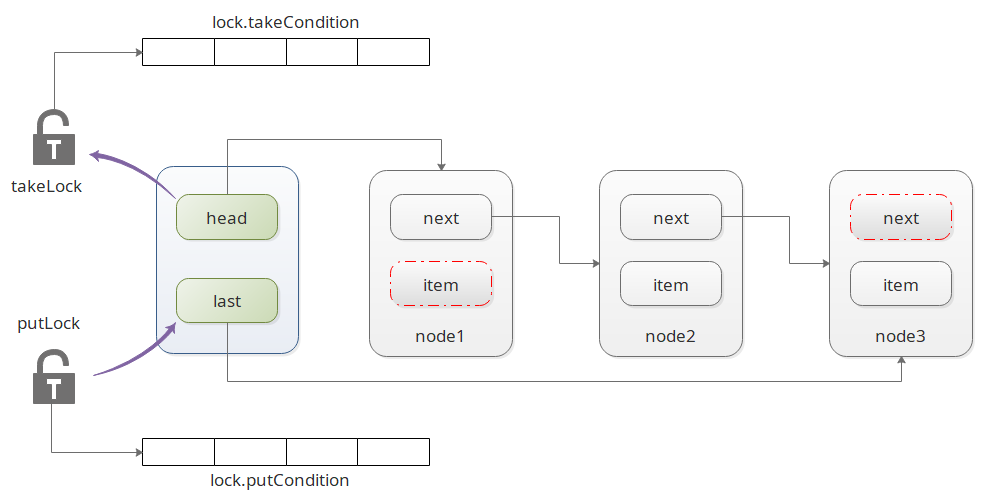
如图所示,
LinkedBlockingQueue其实就是一个简单的单向链表,其中头部元素的数据为空,尾部元素的 next 为空;- 因为读写都有竞争,所以在头部和尾部分别有一把锁;同时还有对应的两个条件队列;
下面我们就读写操作,对源码简单分析:
2. 入队
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
final AtomicInteger count = this.count;
if (count.get() == capacity) return false; // 如果队列已满,直接返回失败
int c = -1;
Node<E> node = new Node<E>(e); // 将数据封装为节点
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
if (count.get() < capacity) {
enqueue(node); // 入队
c = count.getAndIncrement();
if (c + 1 < capacity) // 如果队列未满,则继续唤醒 putCondition 条件队列
notFull.signal();
}
} finally {
putLock.unlock();
}
if (c == 0) // 如果添加之前的容量为0,说明在出队的时候有竞争,则唤醒 takeCondition
signalNotEmpty(); // 因为是两把锁,所以在唤醒 takeCondition的时候,还需要获取 takeLock
return c >= 0;
}
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node; // 连接节点,并设置尾节点
}
3. 出队
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) { // 如果队列为空,则加入 takeCondition 条件队列
notEmpty.await();
}
x = dequeue(); // 出队
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal(); // 如果队列还有剩余,则继续唤醒 takeCondition 条件队列
} finally {
takeLock.unlock();
}
if (c == capacity) // 如果取之前队列是满的,说明入队的时候有竞争,则唤醒 putCondition
signalNotFull(); // 同样注意是两把锁
return x;
}
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC // 将next引用指向自己,则该节点不可达,在下一次GC的时候回收
head = first;
E x = first.item;
first.item = null;
return x;
}
四、ABQ、LBQ 对比
根据以上的讲解,我们可以逐步分析出一些不同,以及在不同场景队列的选择:
- 结构不同
- ABQ:基于数组,有界,一把锁;
- LBQ:基于链表,无界,两把锁;
- 内存分配
- ABQ:队列空间预先初始化,受堆空间影响小,稳定性高;
- LBQ:队列空间动态变化,受对空间影响大,稳定性差;
- 入队、出队效率
- ABQ:数据直接赋值,移除;队列空间重复使用,效率高;
- LBQ:数据需要包装为节点;需开辟新空间,效率低;
- 竞争方面
- ABQ:出入队共用一把锁,相互影响;竞争严重时效率低;
- LBQ:出入队分用两把锁,互不影响;竞争严重时效率影响小;
所以在这里并不能简单的给出详细的数据,证明哪个队列更适合什么场景,最好是结合实际使用场景分析;
JDK源码分析(11)之 BlockingQueue 相关的更多相关文章
- JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue
JDK源码分析—— ArrayBlockingQueue 和 LinkedBlockingQueue 目的:本文通过分析JDK源码来对比ArrayBlockingQueue 和LinkedBlocki ...
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- 【JDK】JDK源码分析-TreeMap(2)
前文「JDK源码分析-TreeMap(1)」分析了 TreeMap 的一些方法,本文分析其中的增删方法.这也是红黑树插入和删除节点的操作,由于相对复杂,因此单独进行分析. 插入操作 该操作其实就是红黑 ...
- 【JDK】JDK源码分析-Vector
概述 上文「JDK源码分析-ArrayList」主要分析了 ArrayList 的实现原理.本文分析 List 接口的另一个实现类:Vector. Vector 的内部实现与 ArrayList 类似 ...
- 【JDK】JDK源码分析-ArrayList
概述 ArrayList 是 List 接口的一个实现类,也是 Java 中最常用的容器实现类之一,可以把它理解为「可变数组」. 我们知道,Java 中的数组初始化时需要指定长度,而且指定后不能改变. ...
- 【JDK】JDK源码分析-List, Iterator, ListIterator
List 是最常用的容器之一.之前提到过,分析源码时,优先分析接口的源码,因此这里先从 List 接口分析.List 方法列表如下: 由于上文「JDK源码分析-Collection」已对 Collec ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(3)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(2)」分析了 AQS 在独占模式下获取资源的流程,本文分析共享模式下的相关操作. 其实二者的操作大部分是类似的,理解了 ...
随机推荐
- 51nod 1135 原根 就是原根...
%%% dalao Orz ,筛素数到sqrt(n),分解ϕ(p),依次枚举判断就好了 #include<cstdio> #include<cstring> #include& ...
- Micropython TPYBoard ADC的使用方法
基本用法 import pybadc = pyb.ADC(Pin('Y11')) # create an analog object from a pinadc = pyb.ADC(pyb.Pin.b ...
- 轻松搞定JSONP跨域请求
一.同源策略 要理解跨域,先要了解一下"同源策略".所谓同源是指,域名,协议,端口相同.所谓"同源策略",简单的说就是基于安全考虑,当前域不能访问其他域的东西. ...
- Spring里的Async注解实现异步操作
异步执行一般用来发送一些消息数据,数据一致性不要求太高的场景,对于spring来说,它把这个异步进行了封装,使用一个注解就可以实现. 用法 程序启动时开启@EnableAsync注解 建立新的类型,建 ...
- MyBatis中主键回填的两种实现方式
主键回填其实是一个非常常见的需求,特别是在数据添加的过程中,我们经常需要添加完数据之后,需要获取刚刚添加的数据 id,无论是 Jdbc 还是各种各样的数据库框架都对此提供了相关的支持,本文我就来和和大 ...
- 带你由浅入深探索webpack4(一)
相信你或多或少也听说过webpack.gulp等这些前端构建工具.近年来webpack越来越火,可以说成为了前端开发者必备的工具.如果你有接触过vue或者react项目,我想你应该对它有所了解. 这几 ...
- Java集合详解7:HashSet,TreeSet与LinkedHashSet
今天我们来探索一下HashSet,TreeSet与LinkedHashSet的基本原理与源码实现,由于这三个set都是基于之前文章的三个map进行实现的,所以推荐大家先看一下前面有关map的文章,结合 ...
- JavaScript实现登录窗口的拖拽
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 为什么Eureca Client要分成服务提供者和服务消费者呢?
[学习笔记]转载 6)为什么Eureca Client要分成服务提供者和服务消费者呢? 通 常来讲,服务提供方是重量的耗时的,所以可能在n台机器上.而服务消费方是轻量的,通过配置ribbon和@Loa ...
- android 自定义权限管理
在Android6.0后有些权限就需要进行询问,虽然可以将targetSdkVersion设置成小于等于23,但是这样可能有些东西无法使用,所以要进行权限的管理. 实现逻辑:打开页面就询问权限,如果没 ...