java stream 原理
java stream 原理
需求
从"Apple" "Bug" "ABC" "Dog"中选出以A开头的名字,然后从中选出最长的一个,并输出其长度
1. 最直白的实现
缺点
- 迭代次数过多
- 频繁产生中间结果,性能无法接受
2. 平常写法
int longest = 0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以张开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
}
}
System.out.println(longest);
缺点
- 具体业务与算法混在一起,不利于代码复用
- 耦合性太强,代码不清晰
3. 责任链模式解耦
public interface Chain {
void proceed(Object object);
}
public class ForChain implements Chain {
private final Chain chain;
public ForChain(Chain chain){
this.chain = chain;
}
@Override
public void proceed(Object object) {
List<String> list = (List<String>) object;
for(String a : list){
if(a.startsWith("A"))
chain.proceed(a);
}
}
}
public class LengthChain implements Chain {
private final Chain chain;
public LengthChain(Chain chain){
this.chain = chain;
}
@Override
public void proceed(Object object) {
String string = (String)object;
chain.proceed(string.length());
}
}
public class ResultChain implements Chain {
private Integer result = 0;
@Override
public void proceed(Object object) {
Integer integer = (Integer) object;
result = Math.max(integer,result);
}
public Integer getResult() {
return result;
}
}
public class Client {
public static void main(String[] args) {
ResultChain resultChain = new ResultChain();
LengthChain lengthChain = new LengthChain(resultChain);
ForChain forChain = new ForChain(lengthChain);
List<String> list = Arrays.asList("Apple","Bug","ABC","Dog");
forChain.proceed(list);
System.out.println("result is "+ resultChain.getResult());
}
}
4. java stream 实现
OptionalInt max = Stream.of("Apple", "Bug", "ABC", "Dog").
filter(e -> e.startsWith("A")).
mapToInt(e -> e.length()).
max();
System.out.println("result is "+ max.getAsInt());
优点
- 开发者是需要关注具体的业务,顶层算法都封装在框架中
- 代码结构清晰,代码量少,减少出错的机会
5. Stream 的原理
5.1 stream与集合比较
尽管stream与集合框架在表现上非常相似,二者都是对数据进行处理,但事实上二者完全不同。集合是一种数据结构,主要关注在内存中组织数据,会在一段时间在内存中持续的存在,而流的主要关注在计算,不为数据提供任何存储空间,只会通过管道提供计算结果。
5.2 stream 操作分类
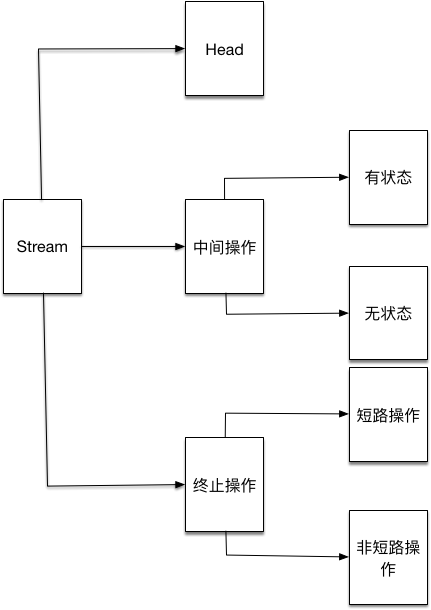
中间操作:返回一个新的stream
- 有状态:必须等上一步操作完,才能执行下一步操作
- 无状态:该操作不受上一步操作的影响
终止操作:返回结果
- 短路:找到即返回
- 费短路:遍历所有元素
以上操作决定了Stream一定是先构建完毕再执行的特点,也就是延迟执行,当需要结果(终端操作时)开始执行流水线。
5.3 stream 结构示意图
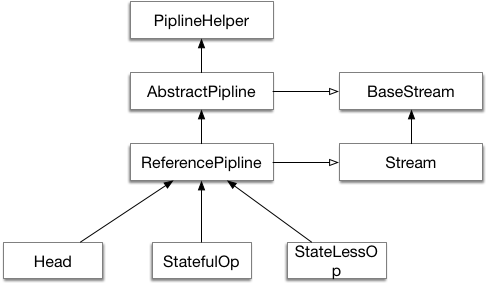
5.4 操作如何记录
- Head记录起始操作
- StateLessOp记录中间操作
- StatefulOp记录有状态的中间操作
这三个操作,在实例化的时候回指向前一个操作,和后一个操作,形成双向链表,每一步操作都能得知上一步和下一步操作。
对于Head:
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;
this.sourceSpliterator = source;
this.sourceStage = this;
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;
this.parallel = parallel;
}
对于其他操作:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this; // 构造双向链表
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
例子:
data.stream()
.filter(x -> x.length() == 2)
.map(x -> x.replace(“三”,”五”))
.sorted()
.filter(x -> x.contains(“五”))
.forEach(System.out::println);
Stage

5.5 操作如何叠加
从终止操作依次构造Sink,如此Sink链构造完成
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
// 依次构造sink
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
sink

- 依次调用sink的begin方法,通知sink链数据已准备好
- 依次调用sink的accept方法,处理数据
- 依次调用sink的end方法,通知数据处理完毕
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}

5.6 如何收集结果
对于forEach是不需要收集结果的,对于collect结果保存在最后一个sink中,这样的操作都会提供一个get方法取出数据。终止操作都会实现Supplier的get方法
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
interface TerminalSink<T, R> extends Sink<T>, Supplier<R> { }
java stream 原理的更多相关文章
- [JavaEE]Java NIO原理图文分析及代码实现
转http://weixiaolu.iteye.com/blog/1479656 目录: 一.java NIO 和阻塞I/O的区别 1. 阻塞I/O通信模型 2. java NIO ...
- Java NIO原理分析
Java IO 在Client/Server模型中,Server往往需要同时处理大量来自Client的访问请求,因此Server端需采用支持高并发访问的架构.一种简单而又直接的解决方案是“one-th ...
- Java NIO原理图文分析及代码实现
原文: http://weixiaolu.iteye.com/blog/1479656 目录: 一.java NIO 和阻塞I/O的区别 1. 阻塞I/O通信模型 2. java ...
- Java NIO原理 图文分析及代码实现
Java NIO原理图文分析及代码实现 前言: 最近在分析hadoop的RPC(Remote Procedure Call Protocol ,远程过程调用协议,它是一种通过网络从远程计算机程序上请 ...
- [源码解析] 当 Java Stream 遇见 Flink
[源码解析] 当 Java Stream 遇见 Flink 目录 [源码解析] 当 Java Stream 遇见 Flink 0x00 摘要 0x01 领域 1.1 Flink 1.2 Java St ...
- Java Stream 源码分析
前言 Java 8 的 Stream 使得代码更加简洁易懂,本篇文章深入分析 Java Stream 的工作原理,并探讨 Steam 的性能问题. Java 8 集合中的 Stream 相当于高级版的 ...
- Java Stream 自定义Collector
Collector的使用 使用Java Stream流操作数据时,经常会用到各种Collector收集器来进行数据收集. 这里便深入了解一点去了解Collector的工作原理和如何自定义Collect ...
- JAVA监听器原理
http://blog.csdn.net/longyulu/article/details/25054697 JAVA监听器原理 标签: 监听器 2014-05-05 15:40 9070人阅读 评论 ...
- Java跨平台原理
此篇博文主要源自网络xiaozhen的天空的博客:http://xiaozhen1900.blog.163.com/blog/static/1741732572011325111945246/ 1.是 ...
随机推荐
- 听说你买了 EOS ,连代码什么样都不知道?
最近发现很多人投资了 EOS,却并不关心 EOS 目前的开发进度和技术细节,如果你投资了 EOS, 还有一定的技术基础,那就更应该关心 EOS 的开发情况了,下面我们就从 EOS 的源代码说起: ...
- Idea中开启assert断言
先打开相应的配置面板,有以下两种方式. 然后在VM栏里输入 -enableassertions 或者 -ea 就好了 然后编写程序试试 我的目录结构如下:(因为Main class那里要写类的全限 ...
- eclipse报错排解
一.解决eclipse中git插件中的cannot open git-upload-pack问题 有时候在eclipse上使用插件egit向github或者osc上同步代码时,有时候会发现出现cann ...
- 设计模式之观察者(OBSERVER)模式
定义 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新. Observer模式描述了如何建立这种关系.这一模式中的关键对象是目标(subject ...
- 【Bootstrap】 bootstrap-table表格组件
[Bootstrap-table] 顾名思义,这个组件专注于bootstrap风格的表格的设计,并且提供了很多表格的基础和进阶的功能,给我们开发前端的表格省下很多力气. 本文主要参考这位博主的系列文章 ...
- C++ STL 容器之栈的使用
Stack 栈是种先进后出的容器,C++中使用STL容器Stack<T> 完美封装了栈的常用功能. 下面来个demo 学习下使用栈的使用. //引入IO流头文件 #include<i ...
- mysql新手入门随笔2
17.创建表 CREATE TABLE tbname(columnname1 类型 约束条件, columnname2 类型 约束条件,-); 三大类型:数值型,时间日期型,字符串类型 六大约束条件: ...
- Pla
Pla(jdoj1006) 题目大意:给你n个矩形,并排放在一起,你的目的是将所有的矩形全部染色.你每次染的形状为一个矩形,问:最少需要染多少次? 注释:n<=10^6,wi , hi<= ...
- java基础笔记(3)----函数
前言引入函数前,所有的代码都写在main主函数中,代码过多,代码冗余,可读性差. 引入函数后,函数是实现某一特定功能的代码块.一个类中可以定义多个函数,每个函数和main主函数都是并列关系. 函数: ...
- SuperMap iClient 查询成功后如何传递参数?
一.iClient API文档中的接口描述 二.范例 //定义一个this对象 this.param = new SuperMap.LonLat(point.x, point.y); querySer ...