浅析fork()和底层实现
记得以前初次接触fork()函数的时候,一直被“printf”输出多少次的问题弄得比较晕乎。不过,“黄天不负留心人"。哈~ 终于在学习进程和进程创建fork相关知识后,总算是大致摸清了其中的来龙去脉。废话不多讲,下面来谈谈本人的一点小小积累
- #include<unistd.h>
- pid_t fork(void);
- 返回值:自进程中返回0,父进程返回进程id,出错返回-1
fork()系统调用会通过复制一个现有进程来创建一个全新的进程. 进程被存放在一个叫做任务队列的双向循环链表当中.链表当中的每一项都是类型为task_struct成为进程描述符的结构.也就是我们写过的进程PCB.
fork()运行时做的事情
/*************************************************************************
2 > File Name: 1.c
3 > Author: tp
4 > Mail:
5 > Created Time: Mon 07 May 2018 07:57:28 PM CST
6 ************************************************************************/ #include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main( void)
{
printf("change world!\n");
pid_t pid = fork();
if( pid == -) {perror("fork"),exit(); } printf( "pid=%d, returnVal=%d\n", getpid(), pid);
sleep( );
exit();
}
~
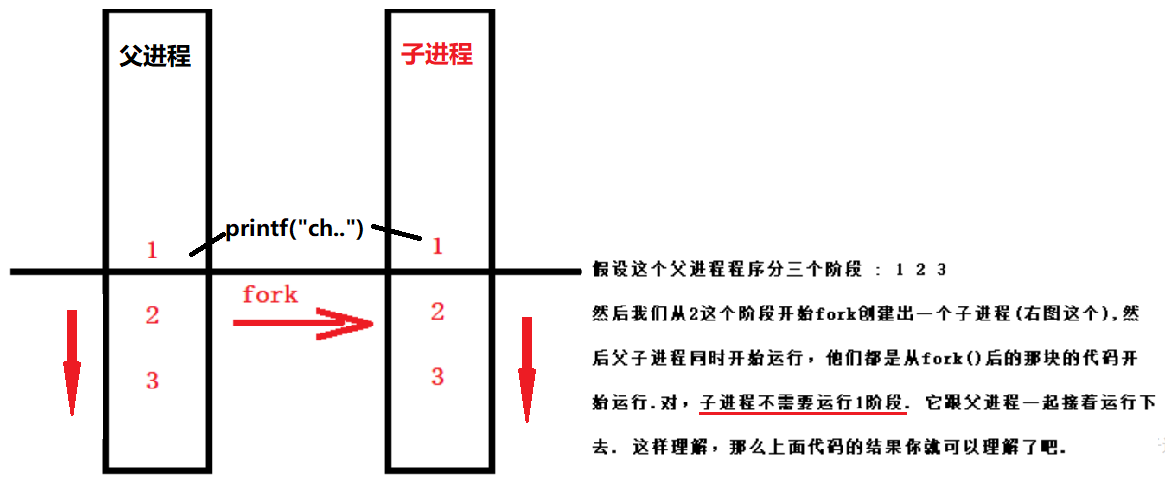
这段代码的运行结果,大家如果像我当时不了解fork的时候,一定会以为输出结果是两个"change world!",然后2个printf里面的内容. 因为

父子进程文件共享问题
/*************************************************************************
2 > File Name: 2.c
3 > Author: tp
4 > Mail:
5 > Created Time: Mon 07 May 2018 12:40:39 PM CST
6 ************************************************************************/ #include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h> int set = ;
int main( void)
{
printf( "before fork\n");
pid_t pid = fork( );
if( pid < ){ perror(" fork"),exit( );} if( pid == )
{
++set;
printf( "son pid=%d, %d\n", getpid(), set);
}
else
{
sleep( );
printf( "parent pid=%d , %d\n", getpid( ), set);
}
exit( );
}
看一下结果:
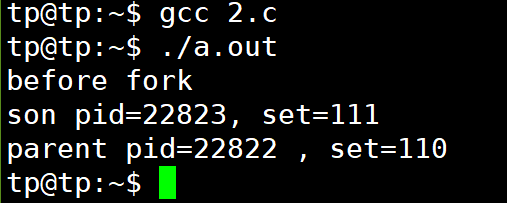
不难注意到 “before fork”这句话只是被打印了一次,这个从上面的例子,这不难理解;与此同时子进程中的set的值被改变了。此时再进行一个重定向操作会发生什么
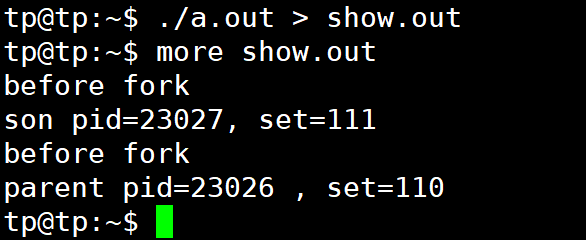
出现很神奇的现象! 这个时候打印了出了两次“before fork”,不仅仅是如此,上述针对父进程的标准输出执行重定向操作还导致了子进程也执行重定向操作。
透过现象看本质,来细细分析一下。针对打印两次“before fork”,首先,先要知道标准IO库是是带缓冲的,而像printf这种直接输出到标准输出时,这个缓冲区是由换行符刷新的;而当执行了重定向操作,这里就是将标准输出重定向到文件,文件就不会立即去刷新缓冲区(全缓冲的方式);好,由于在fork之前调用了一次printf,但fork之后,该行数据仍存留在缓冲区中,然后父进程数据空间被复制到子进程中,该行数据去也被复制了过去,这样父子进程都各自带有该行内容的缓冲区了,相当于子进程缓冲区添加了一行“before fork”,然后在每个进程exit之后,每个缓冲区的内容就被写到了相应的文件中。
再一个就是,在重定向父进程的标准输出时,子进程标准输出也被重定向。这就源于父子进程会共享所有的打开文件。 因为fork的特性就是将父进程所有打开文件描述符复制到子进程中。当父进程的标准输出被重定向,子进程本是写到标准输出的时候,此时自然也改写到那个对应的地方;与此同时,在父进程等待子进程执行时,子进程被改写到文件show.out中,然后又更新了与父进程共享的该文件的偏移量;那么在子进程终止后,父进程也写到show.out中,同时其输出还会追加在子进程所写数据之后,这也就解释了上面为什么“before fork”会在一个文件中打印两次。
在fork之后处理文件描述符一般又以下两种情况:
1.父进程等待子进程完成。此种情况,父进程无需对其描述符作任何处理。当子进程终止后,它曾进行过读,写操作的任一共享描述符的文件偏移已发生改变。
2.父子进程各自执行不同的程序段。这样fork之后,父进程和子进程各自关闭它们不再使用的文件描述符,这样就避免干扰对方使用的文件描述符了。这类似于网络服务进程。
同时父子进程也是有区别的:它们不仅仅是两个返回值不同;它们各自的父进程也不同,父进程的父进程是ID不变的;还有子进程不继承父进程设置的文件锁,子进程未处理的信号集会设置为空集等不同
fork()函数在底层中做了什么?


vfork和fork的之间的比较:
vfork()的诞生是在fork()还没有写时拷贝的时候,因为那个时候创建一个子进程的成本太大了,如果一下子创建好多了那么程序的效率一定会下降. 然后就有人提出了vfork(). vfork的实现原理非常简单,就是子进程,父进程完全公用一个资源. 就是是有人修改了内容,甚至main()函数退出了也不会新开辟一个空间. 所以这里里会有问题的,如果你的一个子进程没有使用exit()退出,那么程序就会出现段错误. 不相信可以去试一试~
vfork和fork之间的区别:
浅析fork()和底层实现的更多相关文章
- Linux中fork()函数的底层实现【转】
转自:http://blog.csdn.net/duoru_xiong/article/details/76358812 1. fork(),vfork(),clone()的区别 这三个系统调用的底层 ...
- const浅析
前言 c++中使用到const的地方有很多, 而且const 本身也针对不同的类型可能有不同的含义, 比如对指针就有顶层和底层. 本节就是探讨关于C++中const的在不同的地方不同表现或含义. co ...
- Java基础教程——List(列表)
集合概述 Java中的集合,指一系列存储数据的接口和类,可以解决复杂的数据存储问题. 导包:import java.util.*; 简化的集合框架图如下: List·列表 ArrayList List ...
- windows消息钩子注册底层机制浅析
标 题: [原创]消息钩子注册浅析 作 者: RootSuLe 时 间: 2011-06-18,23:10:34 链 接: http://bbs.pediy.com/showthread.php?t= ...
- 从底层源码浅析Mybatis的SqlSessionFactory初始化过程
目录 搭建源码环境 POM依赖 测试SQL Mybatis全局配置文件 UserMapper接口 UserMapper配置 User实体 Main方法 快速进入Debug跟踪 源码分析准备 源码分析 ...
- 关于 ReentrantLock 中锁 lock() 和解锁 unlock() 的底层原理浅析
关于 ReentrantLock 中锁 lock() 和解锁 unlock() 的底层原理浅析 如下代码,当我们在使用 ReentrantLock 进行加锁和解锁时,底层到底是如何帮助我们进行控制的啦 ...
- iOS 底层框架的浅析
1.简介 IOS是由苹果公司为iPhone.iPod touch和iPad等设备开发的操作系统. 2.知识点 iPhone OS(现在叫iOS)是iPhone, iPod touch 和 iPad 设 ...
- linux fork函数浅析
#include <sys/types.h> #include <unistd.h> /* 功能:复制进程 參数:无 返回值: 成功: 父进程:返回子进程id 子进程:返回0 ...
- 浅析linux中的fork、vfork和clone
各种大神的混合,做个笔记. http://blog.sina.com.cn/s/blog_7598036901019fcg.html http://blog.csdn.net/kennyrose/ar ...
随机推荐
- ffmpeg.c函数结构简单分析(画图)
前一阵子研究转码的时候看了FFmpeg的源代码.由于ffmpeg.c的代码相对比较长,而且其中有相当一部分是AVFilter有关的代码(这一部分一直不太熟),因此之前学习FFmpeg的时候一直也没有好 ...
- mysql中 REPLACE INTO 和 INSERT INTO 的区别
mysql中 REPLACE INTO 和 INSERT INTO 的区别 REPLACE INTO 和 INSERT INTO 功能类似,都是像表中插入数据,不同点在于:REPLACE INTO 首 ...
- 单元测试junit框架详解
首先在给出一个类Operator,加入如下代码: public class Operator { // 加法 运算 public int add(int i,int j){ return i+j; } ...
- React Native之AppRegistry模块
我们在写react native的js的时候,在最后总会加上一段代码: AppRegistry.registerComponent('ReactDemo', () => ReactDemo); ...
- MinerUrl.java 解析页面后存储URL类
MinerUrl.java 解析页面后存储URL类 package com.iteye.injavawetrust.miner; /** * 解析页面后存储URL类 * @author InJavaW ...
- 取消选中单选框radio的三种方式
作者: 铁锚 日期: 2013年12月21日 本文提供了三种取消选中radio的方式,代码示例如下: 本文依赖于jQuery,其中第一种,第二种方式是使用jQuery实现的,第三种方式是基于JS和DO ...
- (二十一)即时通信的聊天气泡的实现II
一些优化: 禁止TableView的点击: self.tableView.allowsSelection = NO; 合并相同的时间: 不需要显示的时间,只要不设置尺寸就行了. 一个if判断的技巧,为 ...
- Leetcode_75_Sort Colors
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/43302343 Given an array with n ...
- ITU-T Technical Paper: 测量QoS的基本网络模型
本文翻译自ITU-T的Technical Paper:<How to increase QoS/QoE of IP-based platform(s) to regionally agreed ...
- OpenCV——PS 滤镜, 曝光过度
算法原理可以参考: PS 滤镜,曝光过度 #ifndef PS_ALGORITHM_H_INCLUDED #define PS_ALGORITHM_H_INCLUDED #include <io ...