《高性能MySQL》读书笔记(上)
- SELECT ... LOCK IN SHARE MODE
- SELECT ... FOR UPDATE
- LOCK/UNLOCK TABLES
“理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
- Smaller is usually better(越小通常越好):因为占用更少磁盘空间,内存以及CPU缓存,所以越小通常代表越快。
- Simple is good(简单的就是好的):因为字符集和排序规则(Collation)使得字符串的比较很复杂,所以我们应当用Integer等内建类型而非字符串来保存日期时间或IP地址。
- Avoid NULL if possible(尽可能避免NULL):MySQL对NULL有特殊的处理逻辑,所以NULL会使索引、索引统计、值比较都变得更加复杂。
- 倒序走published索引扫描message表,每行都去user表检查是否type为'premium',直到找到10行。
- 走account_type索引扫描user表找到所有type为'premium'的行,进行filesort后返回10行。
- CDC(Change Data Capture)工具能够读取日志(Binary Logs),并提取对应的行变化。
- 一组帮助定义和管理视图的存储过程
- 将改变反应到物化视图数据上的工具
一般我们讨论数据库索引时,其实指的都是B树索引,MySQL的CREATE TABLE及其他语句中也的确使用这种说法。然而实际上,存储引擎内部可能会使用不同的存储结构。例如NDB使用T树(关于不同的索引类型,在我的另一篇介绍内存数据库中也有所提及。T树就非常适合内存存储),而InnoDB使用B+树。
- 因为内部结点不存data了,所以在一个磁盘页上能存更多的key了,树的高度进一步降低,从而加快key的查找命中。
- 需要全树遍历时(如某字段的范围查询甚至full scan,这都是很常见而频繁的查询操作),只需要对B+树的叶子结点进行线性遍历即可,而B树则需要树遍历。而线性遍历比树遍历命中率更高(因为相邻数据都很近,不会分散在结点的左右子树中,跨页的概率能低一些吧)
- 在B树中查找可能在内部结点结束,而B+树则必须在叶子结点结束。

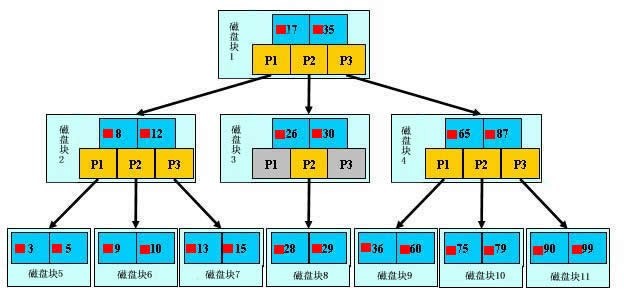
- 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作 1次】
- 此时内存中有两个文件名17、35和三个存储其他磁盘页面地址的数据。根据算法我们发现:17<29<35,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作 2次】
- 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现:26<29<30,因此我们找到指针p2。
- 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作 3次】
- 此时内存中有两个文件名28,29。根据算法我们查找到文件名29,并定位了该文件内存的磁盘地址。
分析上面的过程,发现需要3次磁盘IO操作和3次内存查找操作。关于内存中的文件名查找,由于是一个有序表结构,可以利用折半查找提高效率。至于IO操作是影响整个B树查找效率的决定因素。当然,如果我们使用平衡二叉树的磁盘存储结构来进行查找,磁盘4次,最多5次,而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,效率也越高。
《高性能MySQL》读书笔记(上)的更多相关文章
- 编写可维护的Javascript读书笔记
写在前面:之前硬着头皮参加了java方面的编程规范培训,收货良多,工作半年有余的时候,总算感觉到一丝丝Coding之美,以及造轮子的乐趣,以至于后面开发新功能的时候,在Coding style方面花了 ...
- 《编写可维护的JavaScript》 笔记
<编写可维护的JavaScript> 笔记 我的github iSAM2016 概述 本书的一开始介绍了大量的编码规范,并且给出了最佳和错误的范例,大部分在网上的编码规范看过,就不在赘述 ...
- 编写可维护的javascript阅读笔记
格式 变量 变量命名, 采取小驼峰大小写 变量使用名词, 函数前缀为动词 局部变量应统一定义在函数的最上面, 而不是散落在函数的任意角落. 赋初始值的定义在未赋初始值的变量的上面. 我个人建议不使用单 ...
- 读《编写可维护的javascript》笔记
第一章 基本的格式化 缩进层级:推荐 tab:4; 换行:在运算符后面换行,第二行追加两个缩进: // Good: Break after operator, following line inden ...
- 《编写可维护的javascript》读书笔记(上)
最近在读<编写可维护的javascript>这本书,为了加深记忆,简单做个笔记,同时也让没有读过的同学有一个大概的了解. 一.编程风格 程序是写给人读的,所以一个团队的编程风格要保持一致. ...
- 《编写可维护的javascript》读书笔记(中)——编程实践
上篇读书笔记系列之:<编写可维护的javascript>读书笔记(上) 上篇说的是编程风格,记录的都是最重要的点,不讲废话,写的比较简洁,而本篇将加入一些实例,因为那样比较容易说明问题. ...
- 【读书笔记】读《编写可维护的JavaScript》 - 编程实践(第二部分)
本书的第二个部分总结了有关编程实践相关的内容,每一个章节都非常不错,捡取了其中5个章节的内容.对大家组织高维护性的代码具有辅导作用. 5个章节如下—— 一.UI层的松耦合 二.避免使用全局变量 三.事 ...
- 编写可维护的JavaScript代码(部分)
平时使用的时VS来进行代码的书写,VS会自动的将代码格式化,所有写了这么久的JS代码,也没有注意到这些点.看了<编写可维护的javascript代码>之后,做了些笔记. var resul ...
- 推荐一本好书:编写可维护的JavaScript(可下载)
目录 推荐一本好书:编写可维护的JavaScript(可下载) 书摘: 下载: 有些建议: 推荐一本好书:编写可维护的JavaScript(可下载) 书摘: 很多设计模式就是为了解决紧耦合的问题.如果 ...
- 拯救一切强迫症 - 读《编写可维护的 JavaScript》(一)
拯救一切强迫症 - 读<编写可维护的 JavaScript>(一) 本文写于 2020 年 4 月 24 日 我在小学的时候就有接触过编程,所以读大一的时候 C 语言还算是轻车熟路.自然会 ...
随机推荐
- [SDOI2011]消耗战
题目描述 在一场战争中,战场由n个岛屿和n-1个桥梁组成,保证每两个岛屿间有且仅有一条路径可达.现在,我军已经侦查到敌军的总部在编号为1的岛屿,而且他们已经没有足够多的能源维系战斗,我军胜利在望.已知 ...
- BZOJ 1510: Kra-The Disks
Johnny 在生日时收到了一件特殊的礼物,这件礼物由一个奇形怪状的管子和一些盘子组成. 这个管子是由许多不同直径的圆筒(直径也可以相同) 同轴连接而成. 这个管子的底部是封闭的,顶部是打开的. 下图 ...
- NOIP2014-3-15模拟赛
Problem 1 高级打字机(type.cpp/c/pas) [题目描述] 早苗入手了最新的高级打字机.最新款自然有着与以往不同的功能,那就是它具备撤销功能,厉害吧. 请为这种高级打字机设计一个程序 ...
- hdu 5458 Stability(树链剖分+并查集)
Stability Time Limit: 3000/2000 MS (Java/Others) Memory Limit: 65535/102400 K (Java/Others)Total ...
- hdu 5317 合数分解+预处理
RGCDQ Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submi ...
- [Noi2016]国王饮水记
来自FallDream的博客,未经允许,请勿转载,谢谢. 跳蚤国有 n 个城市,伟大的跳蚤国王居住在跳蚤国首都中,即 1 号城市中.跳蚤国最大的问题就是饮水问题,由于首都中居住的跳蚤实在太多,跳蚤国王 ...
- Mac Webview OC与JS交互实现
1.首先,需要定义一个JS可识别的变量(如external)用于OC与JS交互 - (void)webView:(WebView *)sender didClearWindowObject:(WebS ...
- c# 操作数据库
查询 string strConnection = "Data Source=(local);Initial Catalog=zpractice;Integrated Security=SS ...
- 关于thymeleaf th:replace th:include th:insert 的区别
关于thymeleaf th:replace th:include th:insert 的区别 th:insert :保留自己的主标签,保留th:fragment的主标签. th:re ...
- Mybatis自动生成实体类和实体映射工具
Mybatis Mysql生成实体类 用到的Lib包: mybatis-generator-core-1.3.2.jarmysql-connector-java-5.1.30.jar 1. 创建一个文 ...