HBase 中加盐之后的表如何读取:Spark 篇
在 《HBase 中加盐之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。
我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:
This module contains implementations of InputFormat, OutputFormat, Mapper, Reducer, etc which are needed for running MR jobs on tables, WALs, HFiles and other HBase specific constructs. It also contains a bunch of tools: RowCounter, ImportTsv, Import, Export, CompactionTool, ExportSnapshot, WALPlayer, etc.
我们也知道,虽然上面描述的是 MR jobs,但是 Spark 也是可以使用这些 InputFormat、OutputFormat 来读写 HBase 表的,如下:

上面程序使用 TableInputFormat 计算了 iteblog 表的总行数。如果我们想查询某个 UID 的所有历史记录如何实现呢?如果你查看 TableInputFormat 代码,你会发现其包含了很大参数设置:
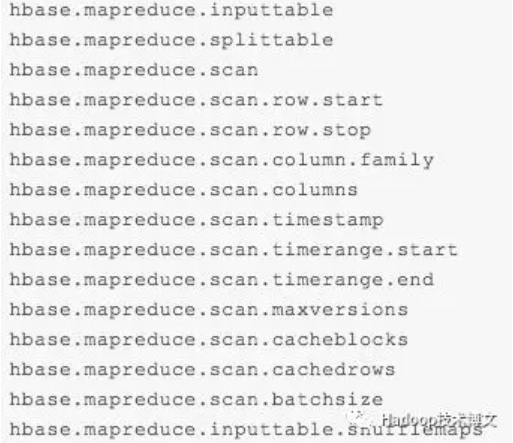
其中 hbase.mapreduce.inputtable 就是需要查询的表,也就是上面 Spark 程序里面的 TableInputFormat.INPUT_TABLE。而 hbase.mapreduce.scan.row.start 和 hbase.mapreduce.scan.row.stop 分别对应的是需要查询的起止 Rowkey,所以我们可以利用这个信息来实现某个范围的数据查询。但是要注意的是,iteblog 这张表是加盐了,所以我们需要在 UID 之前加上一些前缀,否则是查询不到数据的。不过 TableInputFormat 并不能实现这个功能。那如何处理呢?答案是重写 TableInputFormat 的 getSplits 方法。
从名字也可以看出 getSplits 是计算有多少个 Splits。在 HBase 中,一个 Region 对应一个 Split,对应于 TableSplit 实现类。TableSplit 的构造是需要传入 startRow 和 endRow。startRow 和 endRow 对应的就是上面 hbase.mapreduce.scan.row.start 和 hbase.mapreduce.scan.row.stop 参数传进来的值,所以如果我们需要处理加盐表,就需要在这里实现。
另一方面,我们可以通过 RegionLocator 的 getStartEndKeys() 拿到某张表所有 Region 的 StartKeys 和 EndKeys 的。然后将拿到的 StartKey 和用户传进来的 hbase.mapreduce.scan.row.start 和 hbase.mapreduce.scan.row.stop 值进行拼接即可实现我们要的需求。根据这个思路,我们的代码就可以按照如下实现:

然后我们同样查询 UID = 1000 的用户所有历史记录,那么我们的程序可以如下实现:
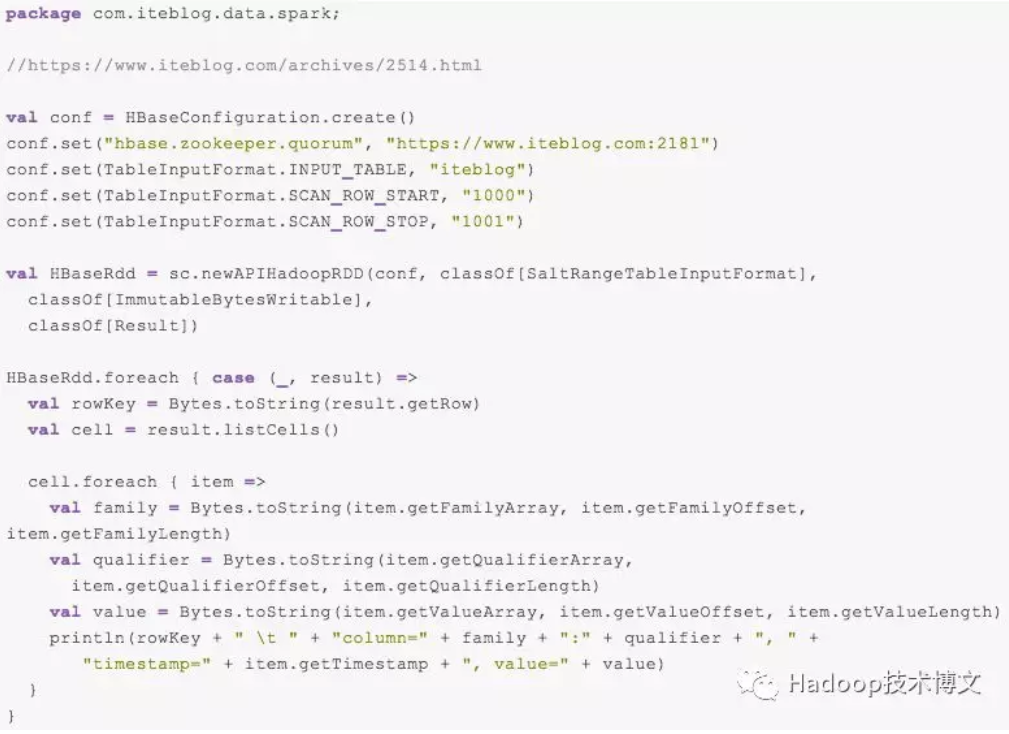
我们编译打包上面的程序,然后使用下面命令运行上述程序:

得到的结果如下:

和前面文章使用 HBase Shell 输出结果一致。好了,到这里就介绍完如何在 Spark 中查询 HBase 加盐之后的表了,明天我会介绍如何在 MapReduce 中查询 HBase 加盐之后的表,敬请关注。
HBase 中加盐之后的表如何读取:Spark 篇的更多相关文章
- HBase中加盐(Salting)之后的表如何读取:协处理器文章
我们介绍了避免数据斑点的三种比较常见方法: 加盐-盐腌 哈希-散列 反转-反转 其中在加盐(Salting)的方法里面是这么描述的:给Rowkey分配一个随机指针以使其和之前排序不同.但是在Rowke ...
- HBase 中加盐(Salting)之后的表如何读取:Spark 篇
我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat.OutputFormat 等类.这个工程的描述如下:This module ...
- hbase数据加盐(Salting)存储与协处理器查询数据的方法
转自: https://blog.csdn.net/finad01/article/details/45952781 ----------------------------------------- ...
- kylin的clube合并后清理hbase中产生的相关历史表
kylin的clube合并后清理hbase中产生的相关历史表 kylin 的clube 历史的每次构建,都会产生一个hbase的表:虽然可以设置按照一定策略合并,但是合并后hbase 历史表不会被自动 ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- Ecplise 中 加载JDBC 连接 Mysql 数据库读取数据
准备工作 首先下载 JDBC 驱动,下载地址https://www.mysql.com/products/connector/ 将压缩包解压得到文件 mysql-connector-java-5.1. ...
- [Phoenix] 四、加盐表
摘要: 在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串.这个在散列中加入字符串的方式称为“加盐”.其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
随机推荐
- mybatis入门总结一
1.parameterType 表示输入参数的类型 2.resultType 表示输出结果的类型 不管输出的是一条还是多条,都只代表单条记录所映射的java对象类 3.#{} 表示sql语句中的占位 ...
- Java 遍历某个目录
import java.io.File; import java.io.IOException; public class DirErgodic { public static void find(S ...
- 2018CCPC吉林赛区(重现赛)
http://acm.hdu.edu.cn/contests/contest_show.php?cid=867 A题,直接分块,不知道正解是什么. #include<bits/stdc++.h& ...
- Codeforces 1012B Chemical table (思维+二分图)
<题目链接> 题目大意:给定一个n*m的矩阵网格,向其中加点,对于一个组成矩形的四个点中如果有三个点中有元素,那么第四个点中会自动产生新的元素.问你最少再加多少个点能够填满这个网格.解题分 ...
- linq函数All,Any,Aggregate说明
int[] arrInt; arrInt = ,,,,,,}; );// 所有元素都满足条件,false );// 有任一元素满足条件,true , , , , , , , , }; var quer ...
- django框架常用的数据库迁移命令
python manage.py makemigrations 默认所有修改过的model层转为迁移文件 python manage.py migrate 默认将所有的迁移文件都执行,更新数据库 ...
- django学习笔记--数据库中的多表操作
1.Django数据库----多表的新增操作 1.一对一模式下新增 创建一个详情对象,把这个对象赋值给创建的新的user对象 author_detail = models.AuthorDetail.o ...
- 数据库与缓存:3.mongodb的基本知识
1. mongodb是什么? NoSQL 非关系型数据库,主要用于数据的海量存储.分为server数据存储端和client数据操作端. 1.1 关系型与非关系型数据库的区别? 1.sql:数据库--表 ...
- GET和POST是HTTP请求的两种基本方法,区别是什么!?
GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二. 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数. 你可能自己 ...
- c++使用boost库遍历文件夹
1.只在当前目录下遍历 #include <boost/filesystem.hpp> string targetPath="/home/test/target"; b ...