JVM(10)之 年老代收集器

在上一篇博文我们介绍了JAVA新生代收集器,本篇博文我们要讲的就是关于老年代的一些收集器。老年代存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域的特性,所以老年代采用的是“标记-清除-整理”算法(以前的博文有详细讨论过)。
- Serila Old收集器:该收集器是Serial收集器的老年代版,同样是一个单线程的收集器,优劣势和Serial收集器一样,这里就不多说了。
- Parallel Old收集器:在我们之前文章的代码例子中默认的年老代收集器,也是Parallel Scavenge收集器的老年代版本。关注点也和Parallel Scavenge收集器一样,注重系统的吞吐量,适合于CPU资源敏感的场合。
- CMS(Concurrent Mark Sweep)收集器:是一种以最短停顿时间为目标的收集器。当应用尤其重视服务的响应速度,希望系统能有最短的停顿时间,该收集器非常适合。
CMS收集器的收集过程比以往的收集器都要复杂,收集过程分为四个步骤:初始标记、并发标记、重新标记、并发清除。
先介绍下每个过程,再来说他是怎么达到最短停顿时间这个目标的。初始标记是需要进行STW的,但仅仅只是标记GC Roots能够直接关联的对象(并不是死掉的对象哦~),由于有OopMap的存在,因此该步骤速度非常快。如图,其中蓝色底纹的便是能够直接关联的对象。 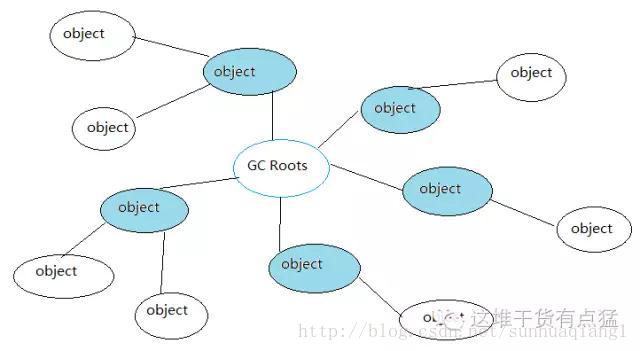
接着就进入了第二步,并发标记。这步是不需要STW的,不需要!他和我们的主程序线程共同执行,从上一步被标记的对象开始,进行可达性分析组成“关系网”。由于不需要进行SWT,所以该步骤不会影响用户体验。既然不暂停线程,小伙伴是不是又怕回收了不该回收的对象?为了避免这个问题,因此就有了第三步。
重新标记是需要STW的,但这又有什么关系呢?重新标记只是为了修改在上一步标记中有了变动的对象。有了这一步,就不怕回收掉不该回收的对象了。而且,由于这一步只是对上一步的结果进行修改,所以STW的时间相当短,对用户的影响不大。
最后一步就是并发清除了,这一步也不需要进行STW,只是清除一些不在“关系网”上的对象而已。
讲到这里,大家应该知道了该收集器如何做到最短停顿时间了吧。通过一次短STW时间的标记和一次不需要STW的标记,大大缩下来第三步标记的范围(只需要修改就好了),第四步不需要STW。
看上去很完美,但还是有他的缺陷:大量使用了并发操作,因此会占用一部分CPU的资源,导致吞吐量下降;当在并发清除垃圾的时候,也就是第四步的时候,他是与当前主线程并发执行的,因此他在回收的时候,我们的主线程又会产生新的垃圾,而这些垃圾在这次回收过程已经回收不了了,只能等待下一次回收了。这些垃圾又叫做“浮动垃圾”。
到这里我们就把老年代的收集器也讲完啦,不知道小伙伴们吸收消化的怎样。学习更重要的还是靠自己的努力与勤奋,别人能给点毕竟有限,自己挖掘才能发现无尽!
JVM(10)之 年老代收集器的更多相关文章
- JAVA 年老代收集器 第10节
JAVA 年老代收集器 第10节 上一章我们讲了新生代的收集器,那么这一章我们要讲的就是关于老年代的一些收集器.老年代的存活的一般是大对象以及生命很顽强的对象,因此新生代的复制算法很明显不能适应该区域 ...
- JVM(9)之 年轻代收集器
开发十年,就只剩下这套架构体系了! >>> 继续上一篇博文所讲的,STW即GC时候的停顿时间,他会暂停我们程序中的所有线程.如果STW所用的时间长而且次数多的话,那么我们整个系统 ...
- JAVA 年轻代收集器 第九节
JAVA 年轻代收集器 第九节 继续上一章所讲的,STW即GC时候的停顿时间,他会暂停我们程序中的所有线程.如果STW所用的时间长而且次数多的话,那么我们整个系统稳定性以及可用性将大大降低. 因此我 ...
- JVM学习记录3--垃圾收集器
贴个图 Serial收集器 最简单的收集器,单线程,收集器会暂停用户线程,称为"stop the world". ParNew收集器 Serial收集器的多线程版本,其它类似.默认 ...
- JVM垃圾回收之CMS收集器
从前文JVM垃圾回收几种常见算法和常见收集器我们知道,CMS是老年代垃圾收集器.CMS 收集器主要关注系统停顿时间.CMS 是 Concurrent Mark Sweep 的缩写,意为并发标记清除,从 ...
- JVM垃圾收集算法——分代收集算法
分代收集算法(Generational Collection): 当前商业虚拟机的垃圾收集都采用"分代收集算法". 这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分 ...
- JVM的stack和heap,JVM内存模型,垃圾回收策略,分代收集,增量收集
(转自:http://my.oschina.net/u/436879/blog/85478) 在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认 ...
- 《深入理解java虚拟机》笔记(7)JVM调优(分代垃圾收集器)
以下配置主要针对分代垃圾回收算法而言. 一.堆大小设置 年轻代的设置很关键 JVM中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用 ...
- Java GC收集器配置说明
根据Java GC收集器具体分类,我们可以看出JVM根据需求不同提供了三种选择:串行收集器.并行收集器.并发收集器. 串行收集器只适用于小数据量的情况,我们主要了解一下并行收集器和并发收集器.默认情况 ...
随机推荐
- 1145. Hashing - Average Search Time (25)
The task of this problem is simple: insert a sequence of distinct positive integers into a hash tabl ...
- 怎样group by一列 select多列
之前sql用的少 竟然不知道这个小技巧 1 将要查询的列 添加到group by后面(会影响查询结果) 2 使用聚合函数如 max select a.accounttitlecode, max(b.c ...
- Linux学习-DNS服务相关
一.DNS服务简介 1.基本概念 (1) DNS( Domain Name System )域名系统,是一种组织成域层次结构的计算机和网络服务命名系统,是一个应用层协议,使用TCP与UDP的53端口, ...
- ModelViewSet的用法
- sql-hive笔试题整理 1 (学生表-成绩表-课程表-教师表)
题记:一直在写各种sql查询语句,最长的有一百多行,自信什么需求都可以接,可......,想了想,可能一直在固定的场景下写,平时也是以满足实际需求为目的,竟不知道应试的题都是怎么出的,又应该怎么做.遂 ...
- 前端面试之路之HTML面试真题
1.doctype的意义是什么 让浏览器以标准模式渲染 让浏览器知道元素的合法性 2.HTML XHTML HTML5的关系 HTML属于SGML XHTML属于XML,是HTML进行XML严格化的结 ...
- 【面经分享】前端小白半年准备,成功进入bat
先介绍下背景 非211,985本科毕业.一年半PHP经验,一年半前端经验,前端一直在做React开发. 半年之前,我是一个前端小小小白.多么小白呢? css调样式全靠试. 盒模型,好像知道是啥?好像又 ...
- BaseActivity 基类
public abstract class BaseActivity extends AppCompatActivity implements IBaseView { private ProxyAct ...
- JDBC链接Mysql失败
错误信息:Error querying database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionExc ...
- 判断文件是否存在的shell脚本代码!
实现代码一 #shell判断文件夹是否存在 #如果文件夹不存在,创建文件夹 if [ ! -d "/Top" ]; then mkdir -p /Topfi #shell判断文件, ...