LDD3 第11章 内核的数据类型
考虑到可移植性的问题,现代版本的Linux内核的可移植性是非常好的。
在把x86上的代码移植到新的体系架构上时,内核开发人员遇到的若干问题都和不正确的数据类型有关。坚持使用严格的数据类型,并且使用-Wall -Wstrict -prototypes选项编译可以防止大多数的代码缺陷。
内核使用的数据类型分成三大类:
- 类似int这样的标准C语言类型
- 类似u32这样的有确定大小的类型
- 像pid_t这样的用于特定内核对象的类型
一、使用标准C语言类型
尽管多数程序员习惯于使用像int和long这样的标准类型,编写涉笔驱动程序时需要小心,以避免缺陷。
普通C语言的数据类型所占空间的大小并不相同。
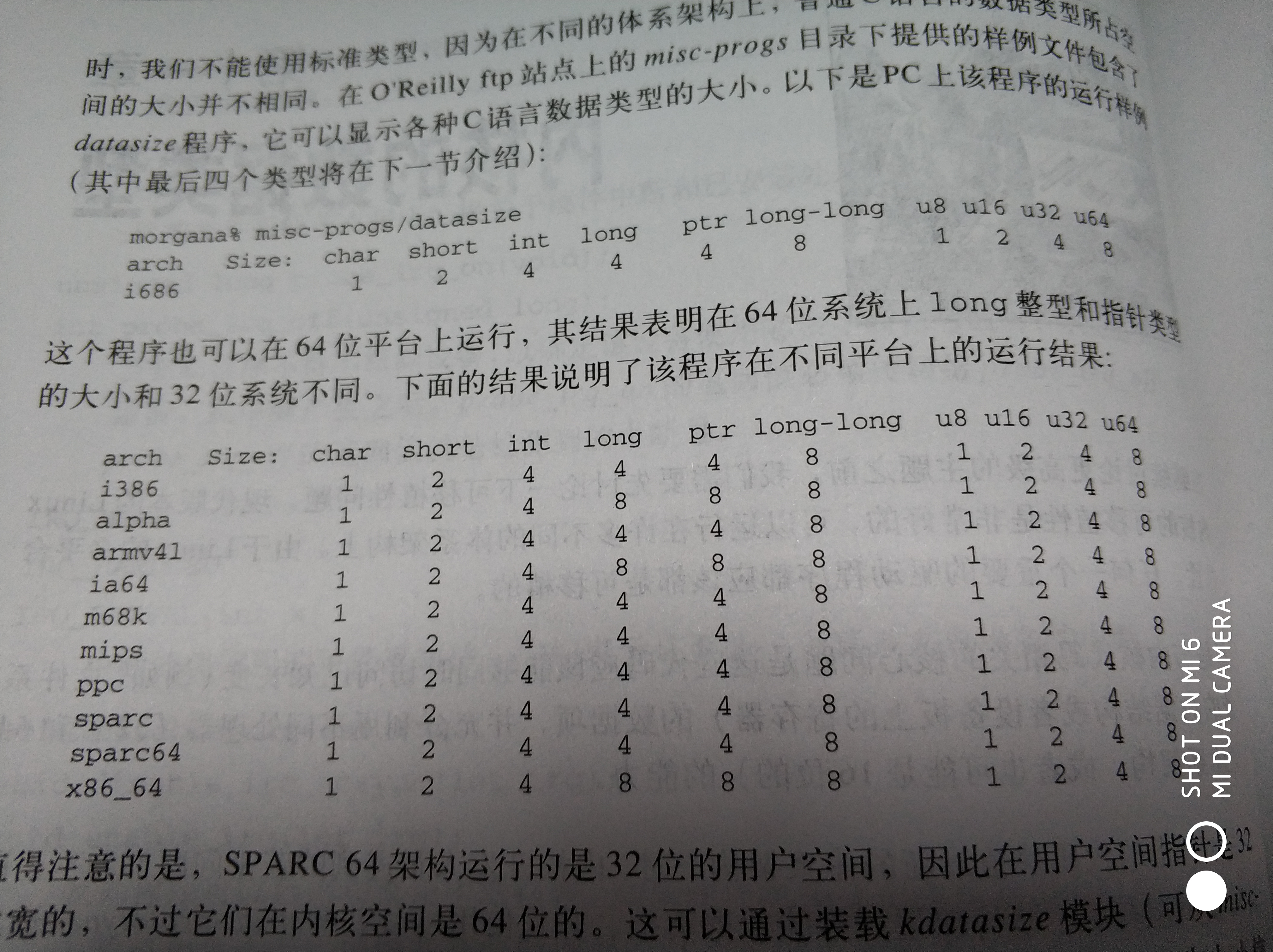
二、为数据项分配确定的空间大小
当我们需要知道自己的数据大小时,内核提供了下列数据结构。
#include <asm/types.h>
u8; /* 无符号字节(8位) */
u16; /* 无符号字(16位) */
u32; /* 无符号32位值 */
u64; /* 无符号64位值 */
数据类型
如果用户空间需要使用,需要在名字前面加两个下划线作为前缀,如__u8。
在C99标准中,有例如uint8_t和uint32_t,如果考虑到可移植性,可以使用这些而不是linux特有的变种。
接口特定的类型
内核汇总最常用的数据类型由他们自己的typedef声明,这样可以防止出现任何移植性问题。
其他有关移植性的问题
一个通用的原则是要避免使用显示的常量值。
时间间隔
不要假定每秒一定有100个jiffies,需要用HZ进行转化。
页大小
内存页的大小为PAGE_SIZE,而不是4KB。
#include <asm/page.h>
int order = get_order(*);
buf = get_free_pages(GFP_KERNEL, order);
get_order
字节序
尽管PC是按照小端存储的,但某些高端平台是大端存储的。
#include <asm/byteorder.h>
u32 cpu_tole32(u32);
u32 le32_to_cpu(u32);
字节序列转换
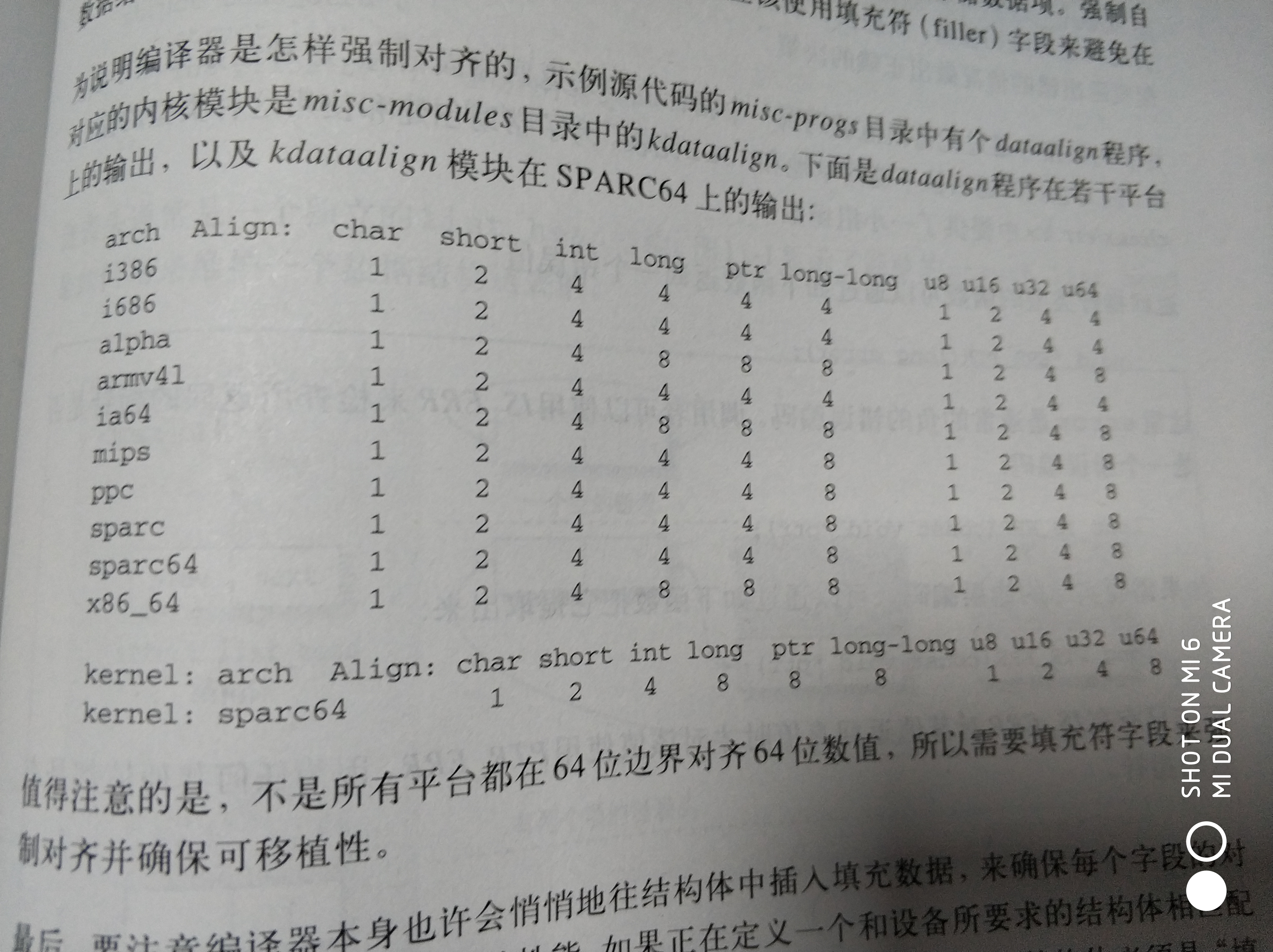
数据对齐
大部分现代体系架构在每次程序试图传输未对齐的数据时都会产生一个异常。数据传输会被异常处理程序处理,这样会带来大量的性能损失。访问未对齐的数据,应该使用下面的宏
#include <asm/unaligned.h>
get_unaligned(ptr);
put_unaligned(va, ptr);
get_unaligned
为了编写可以在不同平台之间可移植的数据项的数据结构,除了规定特定的字节序以外,还应该时钟强制数据项的自然对齐。
自然对齐是指数据项大小的整数倍的地址处存储数据项。强制自然对齐可以防止编译器移动数据结构的字段,应该填充符字段来避免在数据结构中留下空洞。
指针和错误值
大部分情况,失败是通过返回一个NULL指针值来表示的。这样尽管有用,但不能传递问题的确切性质。某些接口确实需要返回一个实际的错误编码。
#include <linux/err.h>
void *ERR_PTR(long error);
error:是通常的负的错误编码
long IS_ERR(const void *ptr);
检查所返回的指针是否是一个错误编码
long PTR_ERR(const void *ptr);
只有IS_ERR为真时,才对该指针使用PTR_ERR
指针和错误
链表
内核开发者建立了一套标准的循环、双向链表的实现。
如果驱动程序试图对同一个链表执行并发操作,有责任实现一个锁。否则,崩溃的链表结构体、数据丢失、内核混乱等问题是很难诊断的。
#include <linux/list.h>
struct list_head {
struct list_head *next, *prev;
}; /* 使用方法 */
struct todo_struct {
struct list_head list;
int priority; /* 驱动程序特定的 */
/* ... 增加其他驱动程序特定的字段 */
};
在使用之前必须用INIT_LIST_HEAD宏来初始化链表头,使用方法:
struct list_head todo_list;
INIT_LIST_HEAD(&todo_list);
/* 另外可在编译时想这样初始化链表 */
LIST_HEAD(todo_list);
然后是操作函数:
#include <linux/list.h>
list_add(struct list_head *new, struct list_head *head);
/* 在链表头后面添加新项,通常是链表头部,可以用来建立栈 */
list_add_tail(struct list_head *new, struct list_head *head);
在给定链表表头的前面添加一个新的项,即在链表的末尾处添加 */
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
/* 删除链表中的给定项 */
list_move(struct list_head *entry, struct list_head *head);
list_move_tail(struct list_head *entry, struct list_head *head);
/* 把给定项移动带链表开始处 */
list_empty(struct list_head *head);
/* 如果给定的链表为空,返回非0值 */
list_splice(struct list_head *list, struct list_head *head);
/* 通过head之后插入list来合并两个链表 */
可利用list_entry宏将要给list_head结构指针映射会指向包含它的大结构的指针
list_entry(struct list_head *ptr, type_of_struct, field_name);
类似下面的代码行,将一个链表项转换成包含它的结构:
struct todo_struct *todo_ptr = list_entry(listptr, struct todo_struct, list);
假设我们想让todo_struct链表中的项按照优先级降序排列,则增加新项的函数如下:
void todo_add_entry(struct todo_struct *new)
{
struct list_head *ptr;
struct todo_struct *entry; for(ptr = todo_list.next; ptr != &todo_list; ptr = ptr->next) {
entry = list_entry(ptr, struct todo_struct, list);
if(entry->priority < new->priority) {
list_add_tail(&new->list, ptr);
return;
}
}
list_add_tail(&new->list, &todo_struct);
}
todo_add_entry
作为一个惯例,最好使用一组预定义的宏来创建可以遍历链表的循环。
void todo_add_entry(struct todo_struct *new)
{
struct list_head *ptr;
struct todo_struct *entry; list_for_each(ptr, &todo_list) {
entry = list_entry(ptr, struct todo_struct, list);
if(entry->priority < new->priority) {
list_add_tail(&new->list, ptr);
return;
}
}
list_add_tail(&new->list, &todo_struct);
}
todo_add_entry
有一些函数变体,如下:
list_for_each(struct list_head *cursor, struct list_head *list)
宏创建一个for循环,每当游标指向链表中的下一项时执行一次
list_for_each_prev(struct list_head *cursor, struct list_head *list)
向后遍历链表
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct list_head *list)
如果循环可能会删除链表汇总的项,就应该使用该版本
list_for_each_entry(type *cursor, struct list_head *list, member)
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list, member)
这些宏使处理一个包含给定类型结构体的链表时更加容易
LDD3 第11章 内核的数据类型的更多相关文章
- 第11章 Windows线程池(1)_传统的Windows线程池
第11章 Windows线程池 11.1 传统的Windows线程池及API (1)线程池中的几种底层线程 ①可变数量的长任务线程:WT_EXECUTELONGFUNCTION ②Timer线程:调用 ...
- 《TCP/IP详解卷1:协议》第11章 UDP:用户数据报协议-读书笔记
章节回顾: <TCP/IP详解卷1:协议>第1章 概述-读书笔记 <TCP/IP详解卷1:协议>第2章 链路层-读书笔记 <TCP/IP详解卷1:协议>第3章 IP ...
- 高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群
高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群 libnet软件包<-依赖-heartbeat(包含ldirectord插件(需要perl-MailTools的rpm包)) l ...
- Linux就这个范儿 第11章 独霸网络的蜘蛛神功
Linux就这个范儿 第11章 独霸网络的蜘蛛神功 第11章 应用层 (Application):网络服务与最终用户的一个接口.协议有:HTTP FTP TFTP SMTP SNMP DNS表示层 ...
- 【机器学习实战】第11章 使用 Apriori 算法进行关联分析
第 11 章 使用 Apriori 算法进行关联分析 关联分析 关联分析是一种在大规模数据集中寻找有趣关系的任务. 这些关系可以有两种形式: 频繁项集(frequent item sets): 经常出 ...
- 【安富莱】【RL-TCPnet网络教程】第11章 RL-TCPnet调试方法
第11章 RL-TCPnet调试方法 本章节为大家讲解RL-TCPnet的调试方法,RL-TCPnet的调试功能其实就是通过串口打印实时监控运行状态.而且RL-TCPnet的调试设置比较简单 ...
- Windows核心编程:第11章 Windows线程池
Github https://github.com/gongluck/Windows-Core-Program.git //第11章 Windows线程池.cpp: 定义应用程序的入口点. // #i ...
- 程序员教程-11章-Java程序设计
自己是学java的,先看第十一章java吧. 列出章节目录,便于自己回忆内容. 11.1 Java语言概述 1 Java语言的特点 2 Java开发环境 11.2 Java语言基础 11.2.1 基本 ...
- <摘录>Linux 环境下编译 0.11版本内核 kernel
系统环境:Fedora 13 + gcc-4.4.5 最近在看<linux内核0.11完全注释>一书,由于书中涉及汇编语言的地方众多,本人在大学时汇编语言学得一塌糊涂,所以实在看不下去了, ...
随机推荐
- python+selenium 滑动滚动条的操作
工作中碰到一种情况就是,要定位的元素需要滚动条滑到下方后才可以显示出来. 这种情况下,就要先滑动滚动条,再定位元素. 那么滑动滚动条我以前记录了appium中的操作,那么,selenium中该如何操作 ...
- UVA 111 历史考试
题目描述:最长公共子序列的变形 题目序列中第i项是学生给第i号历史事件排出的序号,另外还给出了第i号历史事件的正确序号 求按照学生给出的序号排好历史事件后,所得的事件排序与历史事件实际发生的序列的最长 ...
- nginx配置-Rewrite
rewrite功能就是,使用nginx提供的全局变量或自己设置的变量,结合正则表达式和标志位实现url重写以及重定向.rewrite只能放在server{},location{},if{}中,并且只能 ...
- 133、TensorFlow加载模型(二)
# 选择哪个变量来保存和恢复 # 如果你没有传递任何的参数到tf.train.Saver() # 这个saver会处理计算图中所有的变量 # 每一个变量都被保存,保存的名字就是当初创建他们时候的名字 ...
- sticky用法
可以用于滚动到一定距离以后让他实现定位效果. 比如滚动到50px的时候让导航栏固定定位. 用法:给最外层的div设置绝对定位 然后要固定的div设置position:sticky; top:0: 这样 ...
- IAR MSP430怎么破解?IAR for MSP430安装注册破解激活图文详细教程
IAR for MSP430全称IAR Embedded Workbench for MSP430,是一款功能强大的专业集成开发环境,软件包括项目管理.配置开发环境.创建编译器.定制具体编程方案等 ...
- github信息安全开源课
尽可能的减少信息差:兄弟们,该知足了,这些资源非常的宝贵了. ### github探索-主题-令人敬畏的名单 令人敬畏的名单: https://github.com/topics/awesome 进入 ...
- Git007--删除文件
Git--删除文件 本文来自于:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/ ...
- < python PIL - 批量图像处理 - 生成自定义大小图像 >
< python PIL - 批量图像处理 - 生成自定义大小图像 > 直接用python自带的PIL图像库,对一个文件夹下所有jpg/png的图像进行自定义像素变换 from PIL i ...
- centOS7挂在windows移动硬盘方法
1,http://www.tuxera.com/community/open-source-ntfs-3g/ 下载ntfs-3g_ntfsprogs-2016.2.22这个压缩包,可用wget和浏览器 ...