论文阅读:Camdoop: Exploiting In-network Aggregation for Big Data Applications
摘要:
大公司与中小型企业每天都在批处理作业和实时应用程序中处理大量数据,这会产生大量的网络流量,而使用传统的的网络基础架构则很难支持。为了解决这个问题已经提出了几种新颖的网络拓扑,旨在增加企业集群中可用的带宽。
我们观察到,在许多常用的工作负载中,数据是在流程中聚合的,输出大小是输入大小的一小部分。这促使我们改变了思路,与其增加带宽,不如将重点放在通过将聚合从边缘推入网络来减少流量。
我们构建了Camdoop,这是一个在CamCube上运行的类似MapReduce的系统,该集群设计使用直接连接网络拓扑以及直接链接到其他服务器的服务器。 Camdoop利用了CamCube服务器转发流量以在随机播放阶段执行数据的网络内聚合的属性, 支持MapReduce中使用的相同功能,并且与现有MapReduce应用程序兼容。
我们证明,在通常情况下,Camdoop大大降低了网络流量,并且相对于在交换机上运行并针对两个生产系统Hadoop和Dryad / DryadLINQ的Camdoop版本提供了更高的性能提升。
背景/问题:
“大数据”通常是指处理大量数据的异构业务应用程序类别,包括传统的面向批处理的工作,例如数据挖掘、构建搜索索引,以及实时流处理、Web搜索和广告选择。为了实现高可扩展性,这些应用通常采用分区-聚合模型。
在支持MapReduce和Dryad / DryadLINQ 等系统的模型中,存在分布在许多服务器上的大型输入数据集,每个服务器处理其数据共享,并生成本地中间结果,然后汇总所有服务器上包含的一组中间结果,以生成最终结果。通常中间数据很大,因此中间数据被划分到多个服务器上,这些服务器对数据的子集执行聚合以生成最终结果。如果群集中有N个服务器,则使用所有N个服务器执行聚合将提供最高的并行度,并且通常是默认选择,在一些情况下选择较少,只能在单个服务器上聚合。
聚合包括混洗阶段(中间阶段数据在服务器之间传输)和精简阶段,然后数据在服务器之间本地聚合。在所有服务器都参与精简阶段的通用配置中,混洗阶段具有O(N 2 )流的所有流量模式。
对于当前超额订购的数据中心集群而言,这具有挑战性——1:x的带宽超额订购意味着数据中心的对等带宽减少了x倍,因此在混洗阶段期间的数据传输速率受到限制。如果只有一台参与缩减阶段,则服务器的网络链接将成为瓶颈。此外,商品架顶式交换机上的小缓冲区与大量相关流结合在一起,会导致TCP吞吐量崩溃,因为缓冲区超限(内插问题)。
虽然有针对数据中心集群的新网络拓扑的提议,希望通过消除网络超额预订来增加可用带宽,但是这些方法只能部分缓解该问题,因为链路的命运共享意味着无法轻易实现整个二等分带宽。如果参与减少阶段的服务器数量很少,由于服务器链接瓶颈,在网络核心中拥有更多带宽将无济于事,同时,非超额订购的设计会大大增加了布线复杂性和总体成本。
解决办法:
我们一直在探索将聚合推入核心网络而不是仅在边缘执行聚合的好处。
在本文中,我们采用了不同的方法来提高网络性能——我们减少了洗牌阶段的业务量
于是我们使用一个称为CamCube 的平台,该平台没有使用专用的交换机,而是在服务器之间分配了交换机的功能。它使用直接连接拓扑,其中服务器直接连接到其他服务器,在每一跳处的数据包都可以被截取和修改,从而使其成为尝试将功能移入网络的理想平台。
我们已经实现了Camdoop,这是一个在CamCube上运行的类似MapReduce的系统,它支持数据流的完整按路径聚合。 Camdoop以中间数据的源作为执行最终约简的服务器的子节点和根来构建聚合树,Camdoop执行了一个收敛广播,其中所有在路径上的服务器在将数据转发到根目录时聚合数据,这只取决于服务器中间数据集中共有多少密钥,减少了网络通信量,因为在每次跳时只转发一小部分接收到的数据。
CamCube是一个使用商品硬件设计的原型集群,用来试验实现在数据中心中运行的服务的替代方法。CamCube使用直接连接拓扑,其中服务器使用1 Gbps以太网交叉电缆直接相互连接,从而创建了3D环面,如下图所示:

在任何源和目标之间都提供了多条路径,使其能够灵活应对链路和服务器故障。
图2显示了一个带有27个服务器的CamCube示例,服务器负责通过直接连接网络路由所有CamCube内部通信。交换机只用于连接CamCube服务器到外部网络,但不用于路由内部通信量,因此并非所有服务器都需要连接到基于交换机的网络。
CamCube使用了一种新的网络堆栈,它支持基于密钥的路由功能,这是受结构化覆盖中使用的功能的启发。Camcube的主要优点是通过使用直接连接的拓扑并让服务器处理数据包转发,它完全消除了逻辑与物理网络之间的区别。
Camdoop是一个CamCube服务,用于运行类似MapReduce的作业,利用自定义转发和路径数据包处理的能力,将聚合推到网络中,并并行处理洗牌和缩减阶段,提高了系统的性能。
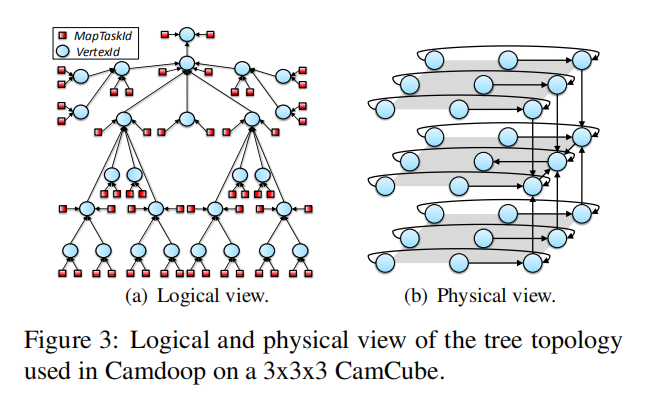
这种树状拓扑可以最大限度地提高网络吞吐量和负载分布。
论文阅读:Camdoop: Exploiting In-network Aggregation for Big Data Applications的更多相关文章
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- 论文阅读-(ECCV 2018) Second-order Democratic Aggregation
本文是Tsung-Yu Lin大神所作(B-CNN一作),主要是探究了一种无序的池化方法\(\gamma\) -democratic aggregators,可以最小化干扰信息或者对二阶特征的内容均等 ...
- 论文阅读:An End-to-End Network for Generating Social Relationship Graphs
论文链接:https://arxiv.org/abs/1903.09784v1 Abstract 社交关系智能代理在人工智能领域中越来越引人关注.为此,我们需要一个可以在不同社会关系上下文中理解社交关 ...
- 【论文阅读】Second-order Attention Network for Single Image Super-Resolution
概要 近年来,深度卷积神经网络(CNNs)在单一图像超分辨率(SISR)中进行了广泛的探索,并获得了卓越的性能.但是,大多数现有的基于CNN的SISR方法主要聚焦于更宽或更深的体系结构设计上,而忽略了 ...
- [论文阅读] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (MobileNet)
论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications 本文提出的模型叫Mobi ...
- 论文阅读:Blink-Fast Connectivity Recovery Entirely in the Data Plane
1.背景 在网络中,链路故障的发生在所难免,为了降低故障带来的影响,就需要重新路由,将数据传输到合适的链路上.当因为链路故障发生处的不同,也有不同的解决方法. AS(Autonomous System ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
随机推荐
- 厉害了,ES 如何做到几十亿数据检索 3 秒返回!
一.前言 数据平台已迭代三个版本,从头开始遇到很多常见的难题,终于有片段时间整理一些已完善的文档,在此分享以供所需朋友的 实现参考,少走些弯路,在此篇幅中偏重于ES的优化,关于HBase,Hadoop ...
- ASCII、Unicode、UTF-8、UTF-16、GBK、GB2312、ANSI等编码方式简析
ASCII.Unicode.UTF-8.UTF-16.GBK.GB2312.ANSI等编码方式简析 序言 从各种字节编码方法中,能看到那个计算机发展的洪荒时期的影子. ASCII ASCII码有标准A ...
- laravel 5.7 引入Illuminate\Http\Request 在类内调用 Request 提示不存在的问题
laravel报错: ReflectionException Class App\Http\Controllers\Request does not exist 解决办法: namespace App ...
- katalon设置Android SDK路径
本文链接:https://blog.csdn.net/feiniao8651/article/details/82809147文章允许转载,请注明来源:https://blog.csdn.net/fe ...
- js之运算符(算术运算符)
Javascript中的运算符大多是由标点符号少数由关键字表示.可以根据其操作数的个数进行分类.大多数运算符是一个二元运算符,将两个表达式合成一个比较复杂的表达式.还有需要注意的一点是运算符的优先级, ...
- 使用HBuilder创建图表
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 深入理解python元类
类也是对象 在理解元类之前,你需要先掌握Python中的类.Python 中的类概念借鉴 Smalltalk,这显得有些奇特.在大多数编程语言中,类就是一组用来描述如何生成一个对象的代码段.当然在 P ...
- Springmvc后台接前台数组,集合,复杂对象
本人转载自: http://blog.csdn.net/feicongcong/article/details/54705933 return "redirect:/icProject/in ...
- 常用的商业级和免费开源Web漏洞扫描工具
Scanv 国内著名的商业级在线漏洞扫描.可以长期关注,经常会有免费活动.SCANV具备自动探测发现无主资产.僵尸资产的功能,并对资产进行全生命周期的管理.主动进行网络主机探测.端口探测扫描,硬件特性 ...
- LVM使用手册简化命令
创建 hot_add --查看新增的lun pvcreate /dev/sdb --创建物理卷 pvcreate /dev/sdc --创建物理卷 pvcreate /dev/sdd ...