机器学习分类算法之K近邻(K-Nearest Neighbor)
一、概念
KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确。而且KNN对资源开销较大。
二、计算
通过K近邻进行计算,需要:
1、加载打标好的数据集,然后设定一个K值;
2、计算预测对象与打标对象的欧式距离,
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式:
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
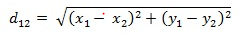
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
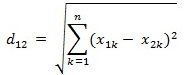
import math
import operator def get_distance(vect_test, vect_train):
distance = 0
for i in range(len(vect_test)):
distance = pow((vect_test[i] - vect_train[i]), 2)
return math.sqrt(distance) def get_neighbor(vect_test, train_vect_set, k):
distance = []
for vect_train in train_vect_set:
dist = get_distance(vect_test, vect_train)
distance.append((dist, vect_train))
distance.sort(key=operator.itemgetter(0))
neighbors = []
for i in range(k):
neighbors.append(distance[i][1])
return neighbors def get_result(neighbors):
votes = {}
for neighbor in neighbors:
vote = neighbor[-1]
if vote in votes:
votes[vote] += 1
else:
votes[vote] = 1
vote_order = sorted(votes.items(), key=operator.itemgetter(1), reverse=True)
return vote_order[0][0] def k_nearest_neighbor(vect_test, vect_train, k):
neighbors = get_neighbor(vect_test, vect_train, k)
result = get_result(neighbors)
print(result) if __name__ == '__main__':
vect_train = [[1, 1, 1, 'a'], [2, 2, 2, 'b'], [1, 1, 3, 'a'], [4, 4, 4, 'b'], [0, 0, 0, 'a'], [4, 5, 4, 'b']]
vect_test = [5, 5, 5]
k_nearest_neighbor(vect_test, vect_train, 3)
机器学习分类算法之K近邻(K-Nearest Neighbor)的更多相关文章
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- 机器学习:分类算法性能指标之ROC曲线
在介绍ROC曲线之前,先说说混淆矩阵及两个公式,因为这是ROC曲线计算的基础. 1.混淆矩阵的例子(是否点击广告): 说明: TP:预测的结果跟实际结果一致,都点击了广告. FP:预测结果点击了,但是 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- DNS通道检测 国外学术界研究情况——研究方法:基于流量,使用机器学习分类算法居多,也有使用聚类算法的;此外使用域名zif low也有
http://www.ijrter.com/papers/volume-2/issue-4/dns-tunneling-detection.pdf <DNS Tunneling Detectio ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- K近邻算法小结
什么是K近邻? K近邻一种非参数学习的算法,可以用在分类问题上,也可以用在回归问题上. 什么是非参数学习? 一般而言,机器学习算法都有相应的参数要学习,比如线性回归模型中的权重参数和偏置参数,SVM的 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
随机推荐
- iOS自动化--Spaceship使用实践
Spaceship ### 脚本操作 证书,app,provision等一些列apple develop后台操作,快速高效. github地址 spaceship开发文档 文档有列出常用的api调用d ...
- inode节点号
查看分区信息命令 df -Th 查看文件inode节点号 ls -i b.txt 查看系统中与b.txt 的inode节点号相同的所有文件,即硬链接 find / -inum xxxx(b.tx ...
- 64位ubuntu下安装ia32-libs
echo "deb http://archive.ubuntu.com/ubuntu/ raring main restricted universe multiverse" &g ...
- SOUI中对象的生命周期管理
C++程序员最难的一环就是处理内存泄漏. 很多情况下,一个对象在一个模块里分配了内存,忘记了释放,或者在另一个模块里释放都会导致内存相关的问题. SOUI中大部分暴露在应用层的对象都使用类似COM的引 ...
- leetcode 12题 数字转罗马数字
leetcode 12题 数字转罗马数字 答案一:我的代码 代码本地运行完全正确,在线运行出错 class Solution { public: string intToRoman(int num) ...
- linux和mac 终端代理
概述 今天发现本地服务不能翻墙,查找了下原因,是因为小飞机在 linux 系统上即使开了全局代理还是不能代理终端的,需要开启终端代理才行.方法我记录下来,供以后开发时参考,相信对其他人也有用. 注意: ...
- 二:flask-debug模式详解
debug模式的情况下可以抛出详细异常信息 新建一个脚本并运行 访问 此时是非debug模式,如果运行的时候代码报错了,是不会提示详细错误的,只会报服务器内部错误 开启debug模式,可以查看到详细错 ...
- 那些堪称神器的 Chrome 插件
Chrome 的简洁快速以及丰富的插件种类使得它在国内日益盛行,帮助了我们很多 Chrome 用户提升了工作效率,而今天要给大家推荐8款实用甚至堪称神器的 Chrome 插件,希望对提升大家的工作效率 ...
- Katalon Studio学习笔记(三)——chromedriver与当前chrome版本不符,如何替换
首先下载chrome版本对应的chromedriver.exe文件,然后找到katalon如下图所示文件夹中,替换chromedriver.exe重新启动katalon即可. 最新适配chrome 7 ...
- win10安装Tensorflow1.9GPU版本
前言 看到DateWhale出了一篇安装教程(微信公众号DateWhale),决定体验一下Tensorflow1.9的GPU版本..其实一开始装的是2.0,但是tf.Session()就报错了,说是2 ...