机器学习分类算法之K近邻(K-Nearest Neighbor)
一、概念
KNN主要用来解决分类问题,是监督分类算法,它通过判断最近K个点的类别来决定自身类别,所以K值对结果影响很大,虽然它实现比较简单,但在目标数据集比例分配不平衡时,会造成结果的不准确。而且KNN对资源开销较大。
二、计算
通过K近邻进行计算,需要:
1、加载打标好的数据集,然后设定一个K值;
2、计算预测对象与打标对象的欧式距离,
欧氏距离是最易于理解的一种距离计算方法,源自欧氏空间中两点间的距离公式:
二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:
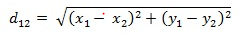
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:
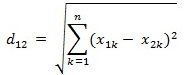
import math
import operator def get_distance(vect_test, vect_train):
distance = 0
for i in range(len(vect_test)):
distance = pow((vect_test[i] - vect_train[i]), 2)
return math.sqrt(distance) def get_neighbor(vect_test, train_vect_set, k):
distance = []
for vect_train in train_vect_set:
dist = get_distance(vect_test, vect_train)
distance.append((dist, vect_train))
distance.sort(key=operator.itemgetter(0))
neighbors = []
for i in range(k):
neighbors.append(distance[i][1])
return neighbors def get_result(neighbors):
votes = {}
for neighbor in neighbors:
vote = neighbor[-1]
if vote in votes:
votes[vote] += 1
else:
votes[vote] = 1
vote_order = sorted(votes.items(), key=operator.itemgetter(1), reverse=True)
return vote_order[0][0] def k_nearest_neighbor(vect_test, vect_train, k):
neighbors = get_neighbor(vect_test, vect_train, k)
result = get_result(neighbors)
print(result) if __name__ == '__main__':
vect_train = [[1, 1, 1, 'a'], [2, 2, 2, 'b'], [1, 1, 3, 'a'], [4, 4, 4, 'b'], [0, 0, 0, 'a'], [4, 5, 4, 'b']]
vect_test = [5, 5, 5]
k_nearest_neighbor(vect_test, vect_train, 3)
机器学习分类算法之K近邻(K-Nearest Neighbor)的更多相关文章
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- k近邻法(k-nearest neighbor, k-NN)
一种基本分类与回归方法 工作原理是:1.训练样本集+对应标签 2.输入没有标签的新数据,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签. 3.一般 ...
- k近邻法( k-nearnest neighbor)
基本思想: 给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类 距离度量: 特征空间中两个实例点的距离是两个实例点相似 ...
- 机器学习:分类算法性能指标之ROC曲线
在介绍ROC曲线之前,先说说混淆矩阵及两个公式,因为这是ROC曲线计算的基础. 1.混淆矩阵的例子(是否点击广告): 说明: TP:预测的结果跟实际结果一致,都点击了广告. FP:预测结果点击了,但是 ...
- 第三章 K近邻法(k-nearest neighbor)
书中存在的一些疑问 kd树的实现过程中,为何选择的切分坐标轴要不断变换?公式如:x(l)=j(modk)+1.有什么好处呢?优点在哪?还有的实现是通过选取方差最大的维度作为划分坐标轴,有何区别? 第一 ...
- DNS通道检测 国外学术界研究情况——研究方法:基于流量,使用机器学习分类算法居多,也有使用聚类算法的;此外使用域名zif low也有
http://www.ijrter.com/papers/volume-2/issue-4/dns-tunneling-detection.pdf <DNS Tunneling Detectio ...
- 机器学习算法之K近邻算法
0x00 概述 K近邻算法是机器学习中非常重要的分类算法.可利用K近邻基于不同的特征提取方式来检测异常操作,比如使用K近邻检测Rootkit,使用K近邻检测webshell等. 0x01 原理 ...
- K近邻算法小结
什么是K近邻? K近邻一种非参数学习的算法,可以用在分类问题上,也可以用在回归问题上. 什么是非参数学习? 一般而言,机器学习算法都有相应的参数要学习,比如线性回归模型中的权重参数和偏置参数,SVM的 ...
- KNN (K近邻算法) - 识别手写数字
KNN项目实战——手写数字识别 1. 介绍 k近邻法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法.它的工作原理是:存在一个 ...
随机推荐
- 第三周课程总结&实验报告(一)
实验报告(一) 1.打印输出所有的"水仙花数",所谓"水仙花数"是指一个3位数,其中各位数字立方和等于该数本身.例如,153是一个"水仙花数" ...
- pycharm2019连接mysql错误08801 ------Connection to django1@localhost failed. [08001] Could not create connection to database server. Attempted reconnect 3 times. Giving up.
Error:Connection to django1@localhost failed. [08001] Could not create connection to database server ...
- BDD Cucumber 实战
cucumber cucumber 是一个用于执行 BDD 的自动化测试工具. 用户指南 创建 Spring Boot 项目并引入依赖 <?xml version="1.0" ...
- Git-Runoob:Git 工作区、暂存区和版本库
ylbtech-Git-Runoob:Git 工作区.暂存区和版本库 1.返回顶部 1. Git 工作区.暂存区和版本库 基本概念 我们先来理解下Git 工作区.暂存区和版本库概念 工作区:就是你在电 ...
- C# 图片文件文本string格式 传输问题
string file = @"E:\test.png"; byte[] bytes = File.ReadAllBytes(file); // 主要代码 string datas ...
- Jmeter之线程组(默认)
Jmeter中的采样器必须要基于线程组. 一.添加线程组 在测试计划上右键,然后选择,如下图: 二.线程组界面 三.线程组界面配置说明 1.名称:线程组自定义名称: 2.注释:添加的一些备注说明信息, ...
- mybatisProxy
config.xml <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configurati ...
- chrome 74 版本的chromedriver下载地址
微信扫二维码关注我的公众号,回复chromedriver 即可获取windows,liunx,mac版本最新selenium-chromedriver
- 【HANA系列】SAP HANA数据处理的理解与分析一
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP HANA数据处理的理解与 ...
- 深入理解java:2.2. 同步锁Synchronized及其实现原理
同步的基本思想 为了保证共享数据在同一时刻只被一个线程使用,我们有一种很简单的实现思想,就是 在共享数据里保存一个锁 ,当没有线程访问时,锁是空的. 当有第一个线程访问时,就 在锁里保存这个线程的标识 ...