Python-使用Magellan进行数据匹配总结
参考:http://www.biggorilla.org/zh-hans/walkt/
使用Magellan进行数据匹配过程如下:
假设有两个数据源为A和B,
A共有四列数据:(A_Column1,A_Column2,A_Column3,A_Column4)
B共有五列数据: (B_Column1,B_Column2,B_Column3,B_Column4,B_Column5)
假设A_Column1和B_Column1是相关的,而A_Column2和B_Column2相关的
1、首先建立合并列表
分别在A和B数据中建立一个混合列mixture
在A中 mixture = A_Column1 + A_Column2 就是把 A_Column1 和 A_Column2两列的数据合并到mixture列里面,
同理,在B中 mixture = B_Column1+ B_Column2

2、寻找一个候选集
这个过程就是使用重叠系数连接两个表,我们可以使用混合列创建所需的候选集(我们称之为C)。

注意:这个过程中threshold这个参数代码这要C这个集合中要创建一列_sim_score ,表示相似度分数,如何经过匹配_sim_score 的数据小于0.65,那么就是不合格的,说白了就是相识度很小,
threshold这个设置的过多大,导致可能C的集合很小,值越大代表数据相识度越大 ,threshold最大值是1,代表匹配数据完全一样,值越小代表数据相识度越小,如果所有数据的匹配结果都小于threshold的值,那么
C就是空集合,因此这个值要根据选择的匹配列数进行设置。
3、指定要素
就是指定在py_entitymatching程序包中哪些列对应于各个数据帧中的要素

4、拦截工具故障排除
确保候选集足够松动,能够容纳并不十分接近的电影配对。如果不是这样,那么可能我们已经清除了可能潜在匹配的配对
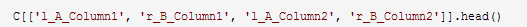
5、从候选集采样
目标是从候选集中获取一个样本,并手动标记抽样候选者;也就是指定候选配对是否是正确的匹配。

要在导出的labeled.csv文件中增加一个label列,根据_sim_score列的数据和实际数据情况,来人为的判断是否是正确的匹配,如果是则在label列中填入数值1,否则,填入数值0
注意:这个label.csv数据集合实际上作为下面机器学习一个训练集,因此这个label列数据之间影响下面机器学习的效果。

6、机器学习算法训练
下面用了几种机器学习算法

在应用任何机器学习方法之前,我们需要抽取一组功能。幸运地是,一旦我们指定两个数据集中的哪些列相互对应,py_entitymatching程序包就可以自动抽取一组功能。指定两个数据集的列之间的对应性,
将启动以下代码片段。然后,它使用py_entitymatching程序包确定各列的类型。通过考虑(变量l_attr_types和r_attr_types中存储的)各个数据集中列的类型,并使用软件包推荐的编译器和类似功能,我们可以抽取一组
用于抽取功能的说明。请注意,变量F并非所抽取功能的集合,相反,它会对说明编码以处理功能。

考虑所需功能的集合F,现在我们可以计算训练数据的功能值,并找出我们数据中丢失数值的原因。在这种情况下,我们选择将丢失值替换为列的平均值。

使用计算的功能,我们可以评估不同机器学习算法的性能,并为我们的匹配任务选择最佳的算法。

7、评估匹配质量
评估匹配质量非常重要。可以针对此目的使用训练集,并衡量随机森林预测匹配的质量。我们可以发现,我们获得最高精确性,并且能够重现测试集。

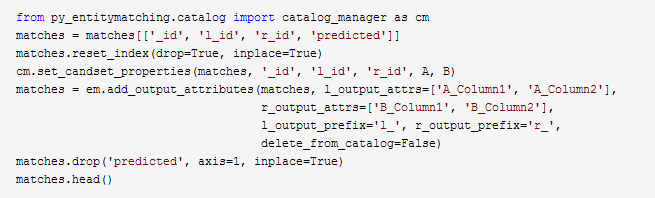
8、使用训练的模型匹配数据集
使用训练的模型对两个标记进行如下匹配

请注意,匹配数据帧包含了很多存储数据集抽取功能的列。以下代码片段移除了所有非必要的列,并创建一个格式良好的拥有最终形成的整合数据集的数据帧。
Python-使用Magellan进行数据匹配总结的更多相关文章
- VLOOKUP函数将一个excel表格的数据匹配到另一个表中
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬虫---爬虫的数据解析的流程和解析数据的几种方式
python爬虫---爬虫的数据解析的流程和解析数据的几种方式 一丶爬虫数据解析 概念:将一整张页面中的局部数据进行提取/解析 作用:用来实现聚焦爬虫的吧 实现方式: 正则 (针对字符串) bs4 x ...
- 分析Python中解析构建数据知识
分析Python中解析构建数据知识 Python 可以通过各种库去解析我们常见的数据.其中 csv 文件以纯文本形式存储表格数据,以某字符作为分隔值,通常为逗号:xml 可拓展标记语言,很像超文本标记 ...
- Python正则表达式处理中的匹配对象是什么?
老猿才开始学习正则表达式处理时,对于搜索返回的匹配对象这个名词不是很理解,因此在前阶段<第11.3节 Python正则表达式搜索支持函数search.match.fullmatch.findal ...
- JavaScript 解析 Django Python 生成的 datetime 数据 时区问题解决
JavaScript 解析 Django/Python 生成的 datetime 数据 当Web后台使用Django时,后台生成的时间数据类型就是Python类型的. 项目需要将几个时间存储到数据库中 ...
- 【转载】使用Pandas进行数据匹配
使用Pandas进行数据匹配 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas进行数据匹配 目录 merge()介绍 inner模式匹配 lefg模式匹配 right模式匹配 outer模式 ...
- Python下载Yahoo!Finance数据
Python下载Yahoo!Finance数据的三种工具: (1)yahoo-finance package. (2)ystockquote. (3)pandas.
随机推荐
- [LOJ #2162]「POI2011」Garbage
题目大意:给一张$n$个点$m$条边的无向图,每条边是黑色的或白色的,要求变成一个目标颜色.可以从任意一个点开始,走一个简单环,回到开始的点,所经过的边颜色翻转.可以走无数次.问是否有一个方案完成目标 ...
- [spoj] FTOUR2 FREE TOUR II || 树分治
原题 给出一颗有n个点的树,其中有M个点是拥挤的,请选出一条最多包含k个拥挤的点的路径使得经过的权值和最大. 正常树分治,每次处理路径,更新答案. 计算每棵子树的deep(本题以经过拥挤节点个数作为d ...
- 关于each()、find()、filter()遍历节点的操作方法
关于each().find().filter()遍历节点的操作方法 each语法: each(fn) ; 返回值:jQuery fn:代表对于每个匹配元素所要执行的函数 each()方法共有三种形式 ...
- vue-cli打包后图片路径取不到的问题
今天准备把vue-cli build 的文件发到服务器上单发现会出现图片找不到的问题 解决办法如下 修改 assetsPublicPath: './' .打开webpack.prod.conf.js, ...
- zmap zgrab 环境搭建
yum install cmake gmp-devel gengetopt libpcap-devel flex byacc json-c-devel libunistring-devel golan ...
- 两步完美解决 androud 模拟器太慢的问题
androud 开发环境默认的 avd 管理器下载并启动的模拟器,运行速度非常慢,有时不可忍受,用下面两步可以解决这个问题: 下载 genymotion-2.3.1 (注意,最好是这个版本,试过2.4 ...
- Linux内核内存管理-内存访问与缺页中断【转】
转自:https://yq.aliyun.com/articles/5865 摘要: 简单描述了x86 32位体系结构下Linux内核的用户进程和内核线程的线性地址空间和物理内存的联系,分析了高端内存 ...
- ectouch 微信支付成功后订单状态未改变的解决办法 (转载)
原文地址: 微信支付支付成功后,返回到mobile/wx_native_callback.php 之前代码 define('IN_ECS', true); require(dirname(__FILE ...
- python+requests接口自动化完整项目设计源码【转载】
本篇转自博客:上海-悠悠 原文地址:http://www.cnblogs.com/yoyoketang/tag/python%E6%8E%A5%E5%8F%A3%E8%87%AA%E5%8A%A8%E ...
- Switch能否用string做参数
在Java5以前,switch(expr)中,exper只能是byte,short,char,int类型(或其包装类)的常量表达式. 从Java5开始,java中引入了枚举类型,即enum类型. 从J ...