利用jTessBoxEditor工具进行Tesseract-OCR样本训练
jTessBoxEditor依赖java虚拟机 , 所以要先安装 java.
jTessBoxEditor下载地址:
解压后跳转到解压目录, 启动 jTessBoxEditor,命令行输入:
java -Xms128m -Xmx1024m -jar jTessBoxEditor.jar
样本训练:
、准备样本图片
手动用画图工具写了一些数字(或者去刷网站的验证码) , 如果是彩色图片首先做灰度化处理以提高识别率 . 全部转换成tif文件, 可以用验证码结果命名方便比对.
、合并图片
打开jTessBoxEditor, 点击Tools > Merge Tiff, 选中所有准备好的tif文件,并把生成的tif文件放到一个新目录下, 命名为num.font.exp0.tif
注意: num是自定义的语言名称, font是自定义的字体名称.
问题: 我在使用jTessBoxEditor合并tif文件是报couldn't seek , 未找到原因, 后来改用TiffToy进行合并成功.
、生成box文件
tesseract num.font.exp0.tif num.font.exp0 [-l eng -psm 7] batch.nochop makebox
以上[]中的内容当返回Empty page的时候可以加上.其中 -psm 7 表示用单行文本识别,-l eng 表示使用英语语言.
、修改box文件
切换到jTessBoxEditor工具的Box Editor页,点击open,打开前面的tiff文件langyp.fontyp.exp0.tif,工具会自动加载对应的box文件。
逐个核对tif文件的box数据, 如果错误就进行修改, 全部检查结束后保存.
注意: box数据有翻页, 之前合并了多少tif文件就有多少页.
、生成font_properties
echo font >font_properties
【语法】:<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
、生成训练文件
tesseract num.font.exp0.tif num.font.exp0 nobatch box.train
、生成字符集文件
unicharset_extractor num.font.exp0.box
、生成shape文件
shapeclustering -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
、生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
、生成字符正常化特征文件
cntraining num.font.exp0.tr
、更名
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename unicharset num.unicharset
rename shapetable num.shapetable
、合并训练文件,生成num.traineddata
combine_tessdata num.
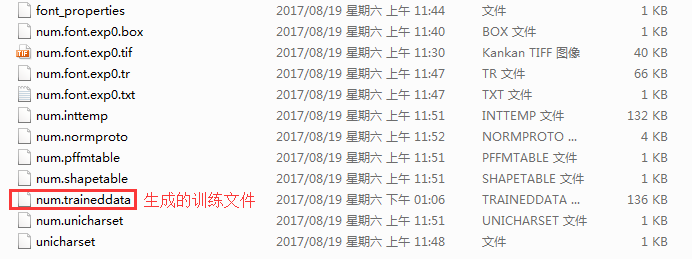
以上是目录中的文件, 将生成的num.traineddata复制到Tesseract-OCR中的tessdata文件夹中即可.
最后进行一下测试:
tesseract test.png output -l num
#我们使用了指令[-l num]而不是[-l eng]。这说明,我们使用的是新生成的num语言的匹配库而不是默认的eng语言匹配库.
参考:
http://www.cnblogs.com/zhongtang/p/5555950.html
http://www.cnblogs.com/cnlian/p/5765871.html
http://vietocr.sourceforge.net/training.html
利用jTessBoxEditor工具进行Tesseract-OCR样本训练的更多相关文章
- 利用jTessBoxEditor工具进行Tesseract3.02.02样本训练,提高验证码识别率
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
- jTessBoxEditor工具进行Tesseract3.02.02样本训练
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- tesseract ocr训练 pt验证码
识别率有问题A大概率识别为n,因此需要训练,这里讲一下 如何训练 参考 java代码里边直接使用tess4j,是对tesseract的封装,但是如果要训练,还是需要在进行安装tesseract-ocr ...
- Tesseract-OCR 字符识别---样本训练 [转]
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文). ...
- Tesseract-OCR 字符识别---样本训练
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文). ...
- 转 Tesseract-OCR 字符识别---样本训练
转自:http://blog.csdn.net/feihu521a/article/details/8433077 Tesseract是一个开源的OCR(Optical Character Recog ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- Python3.x:pytesseract识别率提高(样本训练)
Python3.x:pytesseract识别率提高(样本训练) 1,下载并安装3.05版本的tesseract 地址:https://sourceforge.net/projects/tessera ...
随机推荐
- (Prim算法)codeVs 1078 最小生成树
题目描述 Description 农民约翰被选为他们镇的镇长!他其中一个竞选承诺就是在镇上建立起互联网,并连接到所有的农场.当然,他需要你的帮助. 约翰已经给他的农场安排了一条高速的网络线路,他想把这 ...
- Visual Studio 2015中设计UML类图
1.UML简介 Unified Modeling Language (UML)又称统一建模语言或标准建模语言. 简单说就是以图形方式表现模型,根据不同模型进行分类,在UML 2.0中有13种图,以下是 ...
- opencv: 基本知识;
注: 该篇博文为扩展型,后期将逐步进行扩展: 1. IplImage转Mat IplImage转Mat: IplImage *pImage = cv::loadImage(“”); Mat imgM ...
- Word 测试下发布博客
目录 语法. 3 NULL,TRUE,FALSE 3 大小端存储 4 类型转换 4 转义字符 5 运算符的优先级 5 表达式(a=b=c) 7 *pa++=* ...
- OpenStack的基础原理
OpenStack的基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. OpenStack既是一个社区,也是一个项目和一个开源软件,它提供了一个部署云的操作平台或工具集.其 ...
- Hadoop生态圈-单点登录框架之CAS(Central Authentication Service)部署
Hadoop生态圈-单点登录框架之CAS(Central Authentication Service)部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.CAS简介 CAS( ...
- jvm_tool jconsole/ jprofiler/ JProbe/ VirtualVm/ TPV/ YourKit/ ITCAM/ MAT/ MDD4J
S 学习jvm,关于MAT an internal error occurred during:"Parsing heap dump" from问题 https://www.cnb ...
- I/O模型之四:Java 浅析I/O模型(BIO、NIO、AIO、Reactor、Proactor)
目录: <I/O模型之一:Unix的五种I/O模型> <I/O模型之二:Linux IO模式及 select.poll.epoll详解> <I/O模型之三:两种高性能 I ...
- 基于zookeeper(集群)+LevelDB的ActiveMq高可用集群安装、配置、测试
一. zookeeper安装(集群):http://www.cnblogs.com/wangfajun/p/8692117.html √ 二. ActiveMq配置: 1. ActiveMq集群部署 ...
- Kafka权威指南 读书笔记之(一)初识Kafka
发布与订阅消息系统 数据(消息)的发送者(发布者)不会直接把消息发送给接收者,这是发布与订阅消息系统的一个特点.发布者以某种方式对消息进行分类,接收者(订阅者)订阅它们, 以便接收特定类型的消息.发布 ...