从零搭建 ES 搜索服务(三)同义词搜索
一、前言
上篇介绍了 ES 的基础搜索,能满足我们基本的需求,然而在实际使用中还可能希望搜索「番茄」能将包含「西红柿」的结果也罗列出来,本篇将介绍如何实现同义词之间的搜索。
二、安装 ES 同义词插件
2.1 同义词插件简介
GitHub 地址:https://github.com/ginobefun/elasticsearch-dynamic-synonym
定时从 MySQL 中获取自定义词库,支持「扩展词」及「停用词」
2.2 安装步骤
参考 GitHub 中的项目说明
三、自定义分析器
要使用「同义词插件」需要在创建索引时使用「自定义模板」并在自定义模板中「自定义分析器」。
3.1 相关概念
① 字符过滤器(character filter)
② 分词器(tokenizer)
③ 词过滤器(token filter)
自定义分析器官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/custom-analyzers.html
3.2 具体配置
① 在上篇新建的「 yb_knowledge.json 」模板中修改「 setting 」配置,往其中添加自定义分析器
"analysis": {
"filter": {
"synonym_filter": {
"type": "dynamic-synonym",
"expand": true,
"ignore_case": true,
"interval": 30,
"tokenizer": "ik_max_word",
"db_url": "jdbc:mysql://localhost:3306/elasticsearch?user=es_user&password=es_pwd&useUnicode=true&characterEncoding=UTF8"
}
},
"analyzer": {
"ik_synonym_max": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": [
"synonym_filter"
]
},
"ik_synonym_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": [
"synonym_filter"
]
}
}
}
自定义分析器说明:
- 首先声明一个新「 token filter 」—— 「 synonym_filter 」,其中 type 为 dynamic-synonym 即动态同义词插件, interval 为 定时同步频率(单位为秒), db_url 为词库的数据库地址。
- 其次声明一个新 「analyzer」—— 「ik_synonym_max」,其中 type 为 custom 即自定义类型, tokenizer 为 ik_max_word 即使用 ik 分析器的 ik_max_word 分词模式, filter 为要使用的词过滤器,可以使用多个,这里使用了上述定义的 synonym_filter 。
- 同上继续声明一个以 ik 分析器的 ik_smart 分词模式作为分词器的分析器。
② 与此同时修改「 mappings 」中的 properties 配置,将「 knowledgeTitle 」及「 knowledgeContent 」这两个字段使用的分析器更换为上述自定义的「 ik_synonym_max 」
"mappings": {
"knowledge": {
...省略其余部分...
"properties": {
...省略其余部分...
"knowledgeTitle": {
"type": "text",
"analyzer": "ik_synonym_max"
},
"knowledgeContent": {
"type": "text",
"analyzer": "ik_synonym_max"
}
}
}
}
③ 最后删除先前创建的 yb_knowledge 索引并重启 Logstash
注:重建索引后可以通过「_analyze」测试分词结果
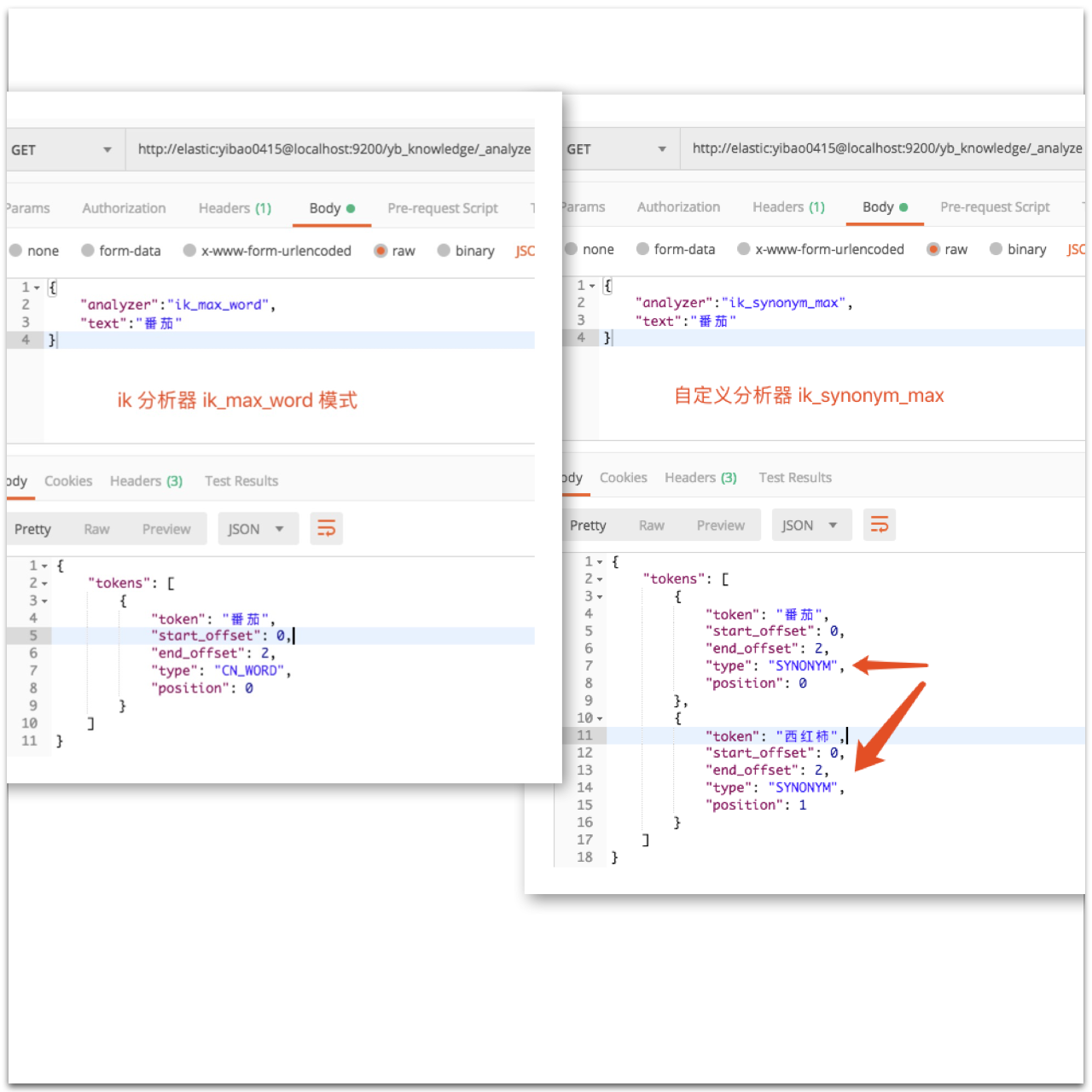
④ 原本在索引中已存在的数据不受同义词动态更新的影响,可以通过以下命令手动更新
curl -XPOST 'http://localhost:9200/yb_knowledge/_update_by_query?conflicts=proceed'
四、结语
至此同义词搜索已经实现完毕,后续将继续介绍其他附加功能,如拼音搜索以及搜索结果高亮等。
从零搭建 ES 搜索服务(三)同义词搜索的更多相关文章
- 从零搭建 ES 搜索服务(二)基础搜索
一.前言 上篇介绍了 ES 的基本概念及环境搭建,本篇将结合实际需求介绍整个实现过程及核心代码. 二.安装 ES ik 分析器插件 2.1 ik 分析器简介 GitHub 地址:https://git ...
- 从零搭建ES搜索服务(一)基本概念及环境搭建
一.前言 本系列文章最终目标是为了快速搭建一个简易可用的搜索服务.方案并不一定是最优,但实现难度较低. 二.背景 近期公司在重构老系统,需求是要求知识库支持全文检索. 我们知道普通的数据库 like ...
- 从零搭建 ES 搜索服务(四)拼音搜索
一.前言 上篇介绍了 ES 的同义词搜索,使我们的搜索更强大了,然而这还远远不够,在实际使用中还可能希望搜索「fanqie」能将包含「番茄」的结果也罗列出来,这就涉及到拼音搜索了,本篇将介绍如何具体实 ...
- 从零搭建 ES 搜索服务(六)相关性排序优化
一.前言 上篇介绍了搜索结果高亮的实现方法,本篇主要介绍搜索结果相关性排序优化. 二.相关概念 2.1 排序 默认情况下,返回结果是按照「相关性」进行排序的--最相关的文档排在最前. 2.1.1 相关 ...
- 从零搭建 ES 搜索服务(五)搜索结果高亮
一.前言 在实际使用中搜索结果中的关键词前端通常会以特殊形式展示,比如标记为红色使人一目了然.我们可以通过 ES 提供的高亮功能实现此效果. 二.代码实现 前文查询是通过一个继承 Elasticsea ...
- 从零搭建一个Redis服务
前言 自己在搭建redis服务的时候碰到一些问题,好多人只告诉你怎么成功搭建,但是并没有整理过程中遇到的问题,所有楼主就花了点时间来整理下. linux环境安装redis 安装中的碰到的问题和解决办法 ...
- 从零搭建SSM框架(三)SSM框架整合
整合思路 1.Dao层: Mybatis的配置文件:SqlMapConfig.xml 不需要配置任何内容,需要有文件头.文件必须存在. applicationContext-dao.xml: myba ...
- 开放搜索服务OpenSearch
开放搜索服务系统架构:从系统.平台到开放服务 搜索是各类网站和数据类APP的标配功能.目前开发者一般基于开源搜索系统,例如ElasticSearch.Solr.Sphinx等自己搭建搜索服务,系统定制 ...
- Sharepoint 2013搜索服务配置总结(实战)
分享人:广州华软 星尘 一. 前言 SharePoint 2013集成了Fast搜索,相对于以前版本搜索的配置有了一些改变,在安装部署Sharepoint 2013时可以选择默认创建搜索服务,但有时候 ...
随机推荐
- 《精通Oracle SQL(第2版)》PDF
一:下载途径 二:图书图样 三:目录 第1章 SQL核心 1.1 SQL语言 1.2 数据库的接口 1.3 SQL*Plus回顾 1.3.1 连接到数据库 1.3.2 配置SQL*Plus环境 1.3 ...
- CentOS6.8安装MySQL5.7.20时报Curses library not found解决
报错如下: CMakeErroratcmake/readline.cmake:83(MESSAGE): Curseslibrarynotfound.Pleaseinstallappropriatepa ...
- centos--git搭建之Gogs安装
1.下载git yum intall -y git 2. 创建git用户(必须新创建git用户, 用root用户会导致无法下载) #创建git用户 sudo adduser git #给git用户设置 ...
- 集腋成裘-01-html -html基础
1 标签 1.1 单标签 注释标签 <!-- 注释标签 --> 换行标签 <br/> 水平线 <hr/> <img src="图片来源" ...
- I: Carryon的字符串排序(字典树/map映射)
2297: Carryon的字符串 Time Limit: C/C++ 1 s Java/Python 3 s Memory Limit: 128 MB Accepted ...
- 静态属性property
静态属性property(是通过对象去使用) property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值 1 . 通过@property修饰过的函数属性,调用的时候无需在加() cla ...
- 【C++ Primer | 10】再探迭代器
插入迭代器 1. 测试代码: #include<iostream> #include<vector> #include<list> #include<iter ...
- Hive启动失败
启动hive报如下错误 [root@node01 conf]# hive19/03/31 09:57:31 WARN conf.HiveConf: HiveConf of name hive.meta ...
- snmp v3的安全配置 snmp认证与加密配置(53)
http://www.ttlsa.com/zabbix/snmp-v3-configuration/
- babelrc
.babelrc文件 // 简单版 { "presets": ["es2015", "stage-2"], // 使用 es2015 npm ...