基于innodb_print_all_deadlocks从errorlog中解析MySQL死锁日志
本文是说明如何获取死锁日志记录的,不是说明如何解决死锁问题的。
MySQL的死锁可以通过show engine innodb status;来查看,
但是show engine innodb status;只能显示最新的一条死锁,该方式无法完全捕获到系统发生的死锁信息。
如果想要记录所有的死锁日志,打开innodb_print_all_deadlocks参数可以将所有的死锁日志记录到errorlog中,
因此问题就变成了如何从errorlog解析死锁日志。
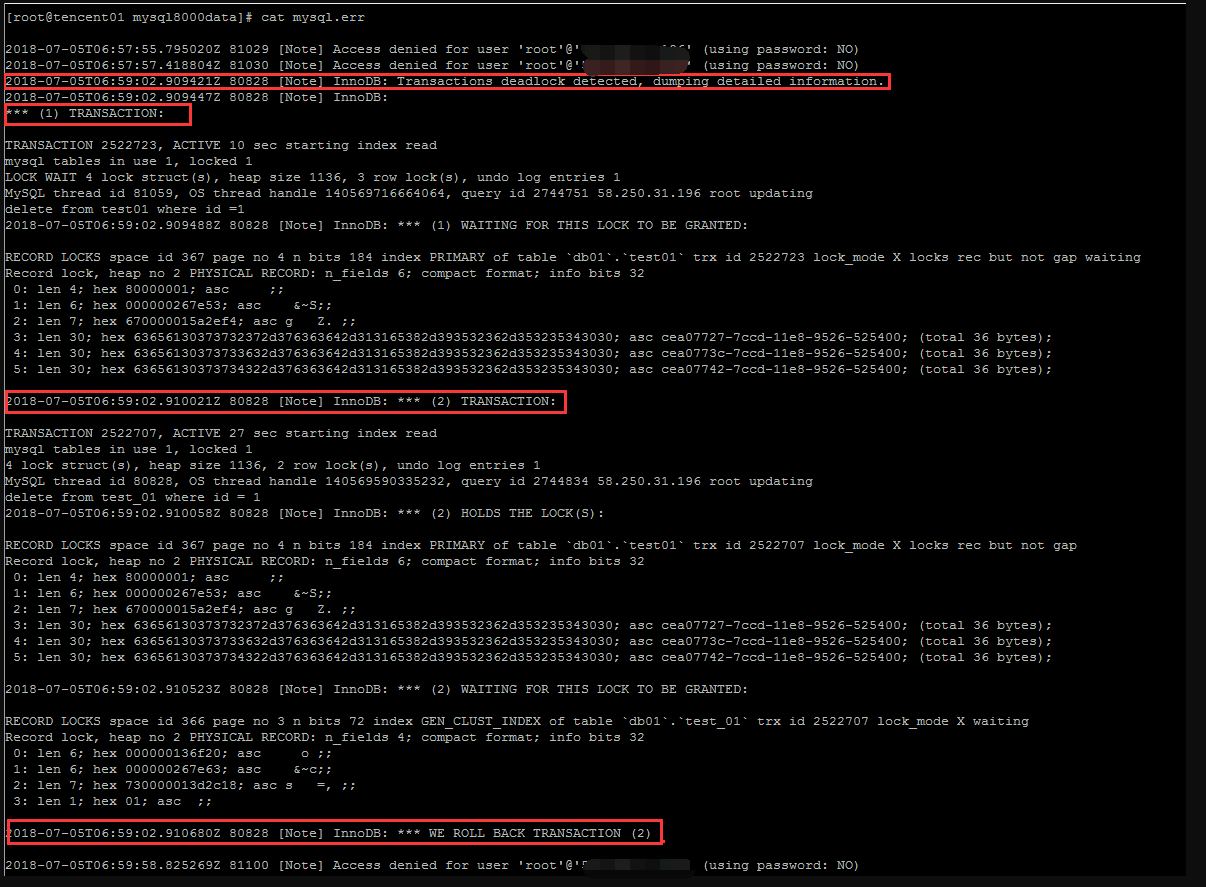
参考如下截图,是errorlog中的一个典型的死锁日志信息,除了死锁日志,可以制造了一些其他的干扰日志(故意不输入密码登陆数据库让它记录一些其他错误日志信息)
如果要解析这个死锁日志(排除其他无关日志),也即解析产生死锁内容,拆分死锁日志内容中的两个(或者)多个事务
1,死锁开始和结束的标记====>截取单个死锁日志内容
2,解析第1步中的死锁日志===>截取各个事务日志
以下解析基于如下规则,基本上都是根据本关键字和正则做匹配
1,死锁日志开始的标记: Transactions deadlock detected, dumping detailed information.
2,死锁日中中事务开始的标记:*** (N) TRANSACTION:
3,死锁结束的标记:WE ROLL BACK TRANSACTION (N)
import os
import time
import datetime
import re
from IO.mysql_operation import mysql_operation class mysql_deadlock_analysis: def __init__(self):
pass def is_valid_date(self,strdate):
try:
if ":" in strdate:
time.strptime(strdate, "%Y-%m-%d %H:%M:%S")
else:
time.strptime(strdate, "%Y-%m-%d")
return True
except:
return False def insert_deadlock_content(self,str_id, str_content):
connstr = {'host': '***,***,***,***',
'port': 3306,
'user': 'username',
'password': 'pwd',
'db': 'db01',
'charset': 'utf8mb4'}
mysqlconn = mysql_operation(host=connstr['host'],
port=connstr['port'],
user=connstr['user'],
password=connstr['password'],
db=connstr['db'],
charset=connstr['charset'])
'''
死锁日志表结构,一个完整的死锁日志按照死锁中第一个事务开始时间为主,deadlock_id一样的话,说明是归属于一个死锁
create table deadlock_log
(
id int auto_increment primary key,
deadlock_id varchar(50),
deadlock_transaction_content text,
create_date datetime
)
'''
str_content = str_content.replace("'","''")
str_sql = "insert into deadlock_log(deadlock_id,deadlock_transaction_content,create_date) " \
"values ('%s','%s',now())" % (str_id, str_content)
try:
mysqlconn.execute_noquery(str_sql, None)
except Exception as err:
raise (Exception, "database operation error") #解析死锁日志内容
def read_mysqlerrorlog(self,file_name):
try:
deadlock_flag = 0
deadlock_set = set()
deadlock_content = ""
with open(file_name,"r") as f:
for line in f:
if(deadlock_flag == 0):
str_datetime = line[0:19].replace("T"," ")
if(self.is_valid_date(str_datetime)):
if(line.find("deadlock")>0):#包含deadlock字符串,表示死锁日志开始
#输出死锁日志,标记死锁日志开始
deadlock_content = deadlock_content+line
deadlock_flag = 1
elif(deadlock_flag == 1):
#输出死锁日志
deadlock_content = deadlock_content + line
#死锁日志结束
if (line.find("ROLL BACK")>0):#包含roll back 字符串,表示死锁日志结束
deadlock_flag = 0
#一个完整死锁日志的解析结束
deadlock_set.add(deadlock_content)
deadlock_content = ""
except IOError as err:
raise (IOError, "read file error")
return deadlock_set #解析死锁日志中的各个事务信息
def analysis_mysqlerrorlog(self,deadlock_set):
#单个事务开始标记
transaction_begin_flag = 0
#死锁中的单个事务信息
transaction_content = ""
# 死锁发生时间
str_datetime = ""
#匹配事务开始标记正则
pattern = re.compile(r'[*]* [(0-9)]* TRANSACTION:')
for str_content in deadlock_set:
arr_content = str_content.split("\n")
for line in arr_content:
if (self.is_valid_date(line[0:19].replace("T", " "))):
#死锁发生时间,在解析死锁日志内容的时候,每组死锁日志只赋值一次,一个死锁中的所有事物都用第一次的时间
str_datetime = line[0:19].replace("T", " ")
#死锁日志中的事务开始标记
if( pattern.search(line)):
transaction_begin_flag = 1
#事务开始,将上一个事务内容写入数据库
if(transaction_content):
self.insert_deadlock_content(str_datetime,transaction_content)
#死锁日志中新开始一个事务,重置transaction_content以及事务开始标记
transaction_content = ""
transaction_begin_flag = 0
else:
#某一个事务产生死锁的具体日志
if(transaction_begin_flag==1):
transaction_content = transaction_content +"\n"+ line
#死锁日志中的最后一个事务信息
if (transaction_content):
self.insert_deadlock_content(str_datetime, transaction_content)
transaction_content = ""
transaction_begin_flag = 0 if __name__ == '__main__':
file_path = "\path\mysql.err"
analysis = mysql_deadlock_analysis()
str_content = analysis.read_mysqlerrorlog(file_path)
analysis.analysis_mysqlerrorlog(str_content)
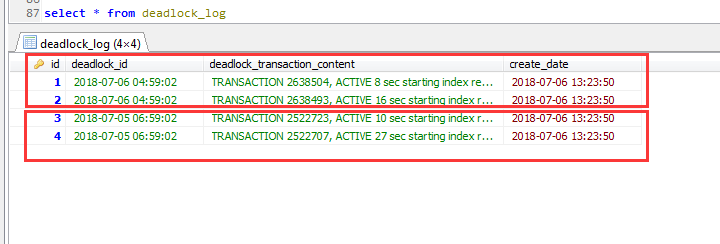
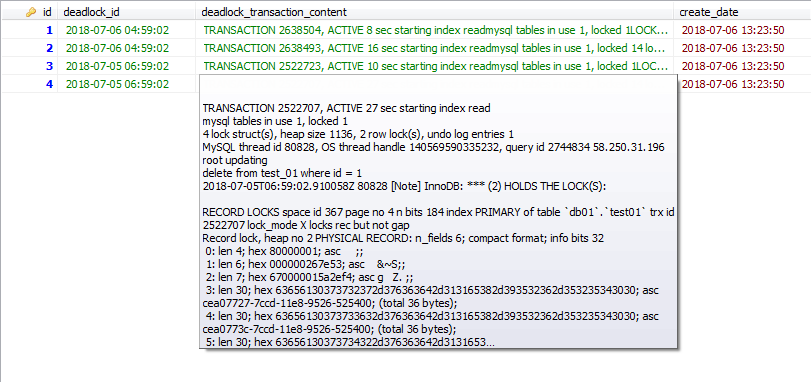
以下是写入到数据库之后的效果id为1,2的对应一组死锁的事务信息,id为3,4的对应一组死锁事务
纯属快速尝试自己的一些个想法,还有很多不足
1,解析后的日志格式很粗
2,解析的都是常规的死锁,不确定能hold所有的死锁日志格式,根据关键字解析的,不知道是不是总是有效
3,如何避免重复解析,也即定时解析MySQL的error的时候,没判断前一次解析过的内容的判断
4,没有做效率测试
基于innodb_print_all_deadlocks从errorlog中解析MySQL死锁日志的更多相关文章
- 解析mysql慢日志
mysql慢日志太多,需要分析下具体有哪些慢日志 mysql可以直接记录所有慢日志,现在的问题是将日志文件sql进行去重 想了老半天该怎样将sql的查询字段去掉进行排序,没有get到重点.后来发现my ...
- MySQL 死锁日志分析
------------------------ LATEST DETECTED DEADLOCK ------------------------ 140824 1:01:24 *** (1) T ...
- [日志分析]Graylog2采集mysql慢日志
之前聊了一下graylog如何采集nginx日志,为此我介绍了两种采集方法(主动和被动),让大家对graylog日志采集有了一个大致的了解. 从日志收集这个角度,graylog提供了多样性和灵活性,大 ...
- 解析MySQL中存储时间日期类型的选择问题
解析MySQL中存储时间日期类型的选择问题_Mysql_脚本之家 https://www.jb51.net/article/125715.htm 一般应用中,我们用timestamp,datetime ...
- mysql 设置 innodb_print_all_deadlocks=ON, 保存死锁日志
Introduced 5.6.2 Command-Line Format --innodb-print-all-deadlocks=# System Variable Name innodb_prin ...
- Mysql binlog日志解析
1. 摘要: Mysql日志抽取与解析正如名字所将的那样,分抽取和解析两个部分.这里Mysql日志主要是指binlog日志.二进制日志由配置文件的log-bin选项负责启用,Mysql服务器将在数据根 ...
- <转>一个最不可思议的MySQL死锁分析
1 死锁问题背景 1 1.1 一个不可思议的死锁 1 1.1.1 初步分析 3 1.2 如何阅读死锁日志 3 2 死锁原因深入剖析 4 2.1 Delete操作的加锁逻辑 4 2.2 死锁预防策略 5 ...
- 一次MySQL死锁问题解决
一次MySQL死锁问题解决 一.环境 CentOS, MySQL 5.6.21-70, JPA 问题场景:系统有定时批量更新数据状态操作,每次更新上千条记录,表中总记录数约为500W左右. 二.错误日 ...
- 腾讯工程师带你深入解析 MySQL binlog
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 本文由 腾讯云数据库内核团队 发布在云+社区 1.概述 binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的red ...
随机推荐
- python之 自动补全 tab
1.在python中运行命令sys.path查看python路径 >>> import sys>>> import tabTraceback (most recen ...
- taro 报错及解决
1.解决:taro 升级到最新版(npm install -g @tarojs/cli) 错误 组件编译 组件src/pages/xxx/xxx.tsx编译失败! TypeError: callee. ...
- JVM-crash查看hs_err_pid.log日志
参考链接: https://www.cnblogs.com/shiyangxt/archive/2009/01/06/1370627.html https://blog.csdn.net/chenss ...
- [转]OpenShift 集群搭建指南
转自:http://www.cnblogs.com/zhangning/p/7251810.html OpenShift 集群搭建指南 v1.0 搭建Hyper-v虚拟机或物理机 配置物理机静态IP, ...
- winform 打印时的默认单位
通过设置Graphics.PageUnit,是枚举类型GraphicsUnit,默认是display(指定显示设备的度量单位. 通常,视频显示使用的单位是像素:打印机使用的单位是 1/100 英寸.)
- linux 管道通信
下面举linux下有名管道通信的代码. ----------------------------------------- fifo_read.c =========== #include<er ...
- xirr函数
内部收益计算函数 曾经看过一个帖子:有一个理财产品,每年年初存入10000元,每年年底得到利息1000元.持续5年,5年后返还本金50000元:问:利率是多少?下面有个回复:每年存10000,利息10 ...
- SpringCloud项目启动报错:NoClassDefFoundError: org/springframework/core/env/EnvironmentCapable
报错表象: 当启动SpringClud项目报错: Exception in thread "main" java.lang.NoClassDefFoundError: org/sp ...
- 前端使用nginx 达到前后分离的开发目的
前言: 由于现在要开发一套基于python 的日志分析系统,设计到日志收集,分析,可视化输出,所以我使用前后端分离的做法.记录学习的过程: 00x1: 下载配置nginx:在E盘创建Service 目 ...
- text_CNN笔记
Text-CNN模型作为文本分类模型,通过验证实验以及业界的共识,在文本分类任务中,CNN模型已经能够取到比较好的结果,虽然在某些数据集上效果可能会比RNN稍差一点,但是CNN模型训练的效率更高.所以 ...