数据结构篇——字典树(trie树)
引入
现在有这样一个问题, 给出\(n\)个单词和\(m\)个询问,每次询问一个单词,回答这个单词是否在单词表中出现过。
好像还行,用 map<string,bool> ,几行就完事了。
那如果n的范围是 \(10^5\) 呢?再用 \(map\) 妥妥的超时,说不定还会超内存。
这时候就需要一种强大的数据结构——字典树
基本性质
字典树,又叫Trie树、前缀树,用于统计,排序和保存大量的字符串,经常被搜索引擎系统用于文本词频统计。
基本思想: 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
假设所有单词都只由小写字母构成,由(abd,abcd,b,bcd,efg,hil)构成的字典树如下。(百科的图最后少了一个字母,姑且认为它是'l'吧)
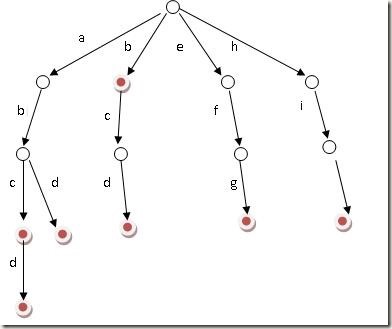
可以看出字典树具有以下特点:
用边表示字母
具有相同前缀的单词共用前缀节点
每个节点最多有26个子节点(在单词只包含小写字母的情况下)
树的根节点是空的
基本操作
数据结构定义
用pass记录有多少字符串经过该节点,就是多少单词以根结点到该结点的边组成的字符串为前缀。
用end记录有多少字符串以该节点结尾,就是多少单词是以根结点到该结点的边组成的字符串。
typedef struct node{
int pass;//有多少单词经过该结点
int end;//有多少单词以该结点结尾
struct node* next[26];
}*trieTree;
插入
向字典树中插入字符串 \(S\)
void insert(trieTree T,string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
node *t = new node();
T->next[index] = t;
}
T = T->next[index];
T->pass++;
}
T->end++;
}
查找
查找文章中有多少单词以字符串 \(S\) 为前缀。
如果要查找字符串 \(s\) 在文章中出现了多少次,则返回值改成 T->end 。
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
return NULL;
}
T = T->next[index];
}
return T->pass;
}
完整实现
#include <iostream>
#include <string>
using namespace std;
typedef struct node{
int pass;
int end;
struct node* next[26];
}*trieTree;
void insert(trieTree T,string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
node *t = new node();
T->next[index] = t;
}
T = T->next[index];
T->pass++;
}
T->end++;
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
return NULL;
}
T = T->next[index];
}
return T->pass;
}
map实现
用 node* next[26] 会浪费很多空间,因为不可能每个结点都用掉 26 个 next
#include <iostream>
#include <map>
#include <string>
using namespace std;
typedef struct node{
public:
int pass;
int end;
map<char,struct node *>m;
}* trieTree;
void insert(trieTree T,string s) {
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
node *t = new node();
T->m.insert(make_pair(s[i], t));
}
T = T->m[s[i]];
T->pass++;
}
T->end++;
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
return NULL;
}
T = T->m[s[i]];
}
return T->pass;
}
适用例题
前缀匹配、 字符串检索 、词频统计,这些差不多都是一类题目,具体实现有一点点不同。
比如前缀匹配,我们只需要pass就行了,用不到end;词频统计的话,我们又只用得到end了;如果只是字符串检索的话,那更方便了,end定义成bool变量就行了。具体用啥,怎么用要变通。
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1251
这题有点小坑,用 node* next[26] 交G++会超内存,交C++就不会。但确实用数组会浪费很多空间,推荐使用map实现。
#include <iostream>
#include <map>
#include <string>
using namespace std;
typedef struct node{
int pass;
map<char,struct node *>m;
}*trieTree;
void insert(trieTree T,string s) {
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
node *t = new node();
T->m.insert(make_pair(s[i], t));
}
T = T->m[s[i]];
T->pass++;
}
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
return NULL;
}
T = T->m[s[i]];
}
return T->pass;
}
int main() {
trieTree T = new node();
string s;
while (getline(cin,s)) {
if (s.empty()) break;
insert(T, s);
}
while (getline(cin,s)) {
cout << find(T, s) << endl;
}
return 0;
}
此外,还适用于字符串排序,字典树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。
数据结构篇——字典树(trie树)的更多相关文章
- 字典树(Trie树)的实现及应用
>>字典树的概念 Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树.与二叉查找树不同,Trie树的 ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结
Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结 1.1. 树形结构-- 一对多的关系1 1.2. 树的相关术语: 1 1.3. 常见的树形结构 ...
- 洛谷$P4585\ [FJOI2015]$火星商店问题 线段树+$trie$树
正解:线段树+$trie$树 解题报告: 传送门$QwQ$ $umm$题目有点儿长我先写下题目大意趴$QwQ$,就说有$n$个初始均为空的集合和$m$次操作,每次操作为向某个集合内加入一个数$x$,或 ...
- luoguP6623 [省选联考 2020 A 卷] 树(trie树)
luoguP6623 [省选联考 2020 A 卷] 树(trie树) Luogu 题外话: ...想不出来啥好说的了. 我认识的人基本都切这道题了. 就我只会10分暴力. 我是傻逼. 题解时间 先不 ...
- 字典树 trie树 学习
一字典树 字典树,又称单词查找树,Trie树,是一种树形结构,哈希表的一个变种 二.性质 根节点不包含字符,除根节点以外的每一个节点都只包含一个字符: 从根节点到某一节点,路径上经过的字符串连接起 ...
- [转载]字典树(trie树)、后缀树
(1)字典树(Trie树) Trie是个简单但实用的数据结构,通常用于实现字典查询.我们做即时响应用户输入的AJAX搜索框时,就是Trie开始.本质上,Trie是一颗存储多个字符串的树.相邻节点间的边 ...
- Luogu P2922 [USACO08DEC]秘密消息Secret Message 字典树 Trie树
本来想找\(01Trie\)的结果找到了一堆字典树水题...算了算了当水个提交量好了. 直接插入模式串,维护一个\(Trie\)树的子树\(sum\)大小,求解每一个文本串匹配时走过的链上匹配数和终点 ...
- 【字符串算法】字典树(Trie树)
什么是字典树 基本概念 字典树,又称为单词查找树或Tire树,是一种树形结构,它是一种哈希树的变种,用于存储字符串及其相关信息. 基本性质 1.根节点不包含字符,除根节点外的每一个子节点都包含一个字符 ...
随机推荐
- vscode用服务打开html
①安装插件 此时右击会有: ②anywhere
- 洛谷 题解 P4198 【楼房重建】
首先明确问题,对于每栋楼房的斜率K=H/X,问题就是问有多少个楼房的K比前面所有楼房的K都要大. 这题树套树当然可以,但是挺麻烦的,本渣觉得最简单就是分块…… 将N个楼房分成T块,不断维护每个块内楼房 ...
- Salesforce 开发整理(七)配置审批流
salesforce提供了比较强大的可配置审批流功能,在系统中翻译为“批准过程”.所以需要配置审批时,选择创建 ——> 工作流和批准 ——> 批准过程,然后选择管理批准过程,选择需要配置 ...
- java线程池模拟并发
public class CountDownLatchTest1 implements Runnable{ final AtomicInteger number = new AtomicInteger ...
- 实战django(二)--登录实现记住我
上节初步实现了登录和注册模块,这节我们进一步实现“记住我”功能. 大体功能分为以下模块: 1.在登录时如果勾选记住我,那么就将用户username存进cookie中,跳转到index页面: 2.此时, ...
- SpringBoot第二篇:配置文件详解一
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/10837594.html 版权声明:本文为博主原创文章,转载请附上博文链接! 前言 Sprin ...
- 解决SpringDataJpa实体类中属性顺序与数据库中生成字段顺序不一致的问题
一.在application.yml配置中添加数据库根据实体类自动创建数据库表的配置(这里数据库采用MySQL数据库) jpa: database: MYSQL show-sql: true #Hib ...
- Beta冲刺(8/7)——2019.5.30
作业描述 课程 软件工程1916|W(福州大学) 团队名称 修!咻咻! 作业要求 项目Beta冲刺(团队) 团队目标 切实可行的计算机协会维修预约平台 开发工具 Eclipse 团队信息 队员学号 队 ...
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- springboot+RabbitMQ 问题 RabbitListener 动态队列名称:Attribute value must be constant
因为多机环境fanout广播模式,每台机器需要使用自己的队列接受消息 所以尝试使用以下的方案 private static final String QUEUE_NAME="foo.&quo ...