Hadoop版本升级(2.7.6 => 3.1.2)
自己的主机上的Hadoop版本是2.7.6,是测试用的伪分布式Hadoop,在前段时间部署了Hive on Spark,但由于没有做好功课,导致了Hive无法正常启动,原因在于Hive 3.x版本不适配Hadoop 2.x版本。之前我在学校服务器上部署的Hadoop版本是3.1.2,现打算将自己的从2.7.6升级到3.1.2版本,同时也当作练练手并记录以便以后参考。这是一个大版本跨度的升级操作,所以先参考Hadoop权威指南上的方案以及官方文档,然后拟定了升级和回滚方案。
根据官方文档所说:
”For non-HA clusters, it is impossible to upgrade HDFS without downtime since it requires restarting the namenodes. However, datanodes can still be upgraded in a rolling manner.“
也就是说对于非HA群集,由于需要重新启动名称节点,因此无法在没有停机的情况下升级HDFS。但是,仍可以回滚方式升级datanode。
注意:仅从Hadoop-2.4.0开始支持滚动升级。
Hadoop升级最主要是HDFS的升级,HDFS的升级是否成功,才是升级的关键,如果升级出现数据丢失,则其他升级就变得毫无意义。
解决方法:
- 备份HDFS的NameNode元数据,升级后,对比升级前后的文件信息。
- 单台升级DataNode,观察升级前后的Block数(有较小浮动范围,v2与v3的计数方式不一样)。
第一阶段 停机以及备份NameNode目录
通过命令stop-yarn.sh和stop-dfs.sh关闭HDFS集群:
# stop-yarn.sh
# stop-dfs.sh
然后备份NameNode目录到NFS或者其他文件系统中,如果不记得NameNode目录存储的地址可以通过查看hdfs-site.xml文件的:
# vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml

第二阶段 在集群上安装新版本的Hadoop
下载Hadoop 3.1.2后解压,最好移除PATH环境变量下的Hadoop脚本,这样的话,就不会混淆针对不同版本的脚本。将HADOOP_HOME指向新的Hadoop:

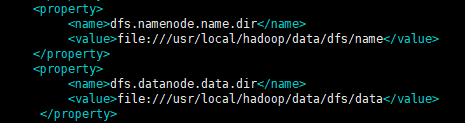
接下来将${HADOOP_HOME}/etc/hadoop/hdfs-site.xml中的dfs.namenode.name.dir和dfs.datanode.data.dir属性的值分别指向Hadoop 2.7.6的hdfs-site.xml的dfs.namenode.name.dir和dfs.datanode.data.dir属性的值。
第三阶段 准备滚动升级
在hdfs-site.xml增加属性:
<property>
<name>dfs.namenode.duringRollingUpgrade.enable</name>
<value>true</value>
</property>
先启动旧版本的Hadoop:
# /usr/local/hadoop/sbin/start-dfs.sh
进入安全模式:
# hdfs dfsadmin -safemode enter

准备滚动升级:
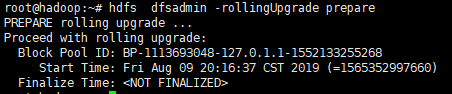
1. 运行“hdfs dfsadmin -rollingUpgrade prepare”以创建用于回滚的fsimage。
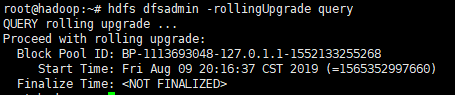
2. 运行"hdfs dfsadmin -rollingUpgrade query"以检查回滚映像的状态。等待并重新运行该命令,直到显示“继续滚动升级”消息。
第四阶段 升级NN与SNN
1. 关闭SNN:
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop secondarynamenode
2. 关闭NameNode和DataNode:
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
# /usr/local/hadoop/sbin/hadoop-daemon.sh stop datanode
3. 在新版本的Hadoop使用“-rollingUpgrade started”选项启动NN:
进入新版本的Hadoop目录,然后以升级的方式启动NameNode:
# $HADOOP_HOME/bin/hdfs --daemon start namenode -rollingUpgrade started
升级hdfs花费的时间不长,升级丢失数据的风险几乎没有。
接下来升级并重启SNN:
# $HADOOP_HOME/bin/hdfs --daemon start secondarynamenode
第五阶段 升级DN
由于我升级的Hadoop是伪分布式的,NameNode和DataNode是在同一节点上,按集群升级分类来说,属于非HA集群升级。在这里,升级DataNode是比较简单的,在新版本的Hadoop上重新启动DataNode即可,等待一会,DataNode自动升级成功。
# $HADOOP_HOME/bin/hdfs --daemon start datanode
无论Hadoop是非HA还是HA,且是完全分布式的话,DataNode节点较多的情况下,可以参考官方文档的思路(写脚本实现):
- 选择一小部分数据节点(例如特定机架下的所有数据节点)
- 运行“hdfs dfsadmin -shutdownDatanode <DATANODE_HOST:IPC_PORT> upgrade”以关闭其中一个选定的数据节点。
- 运行"hdfs dfsadmin -getDatanodeInfo <DATANODE_HOST:IPC_PORT>"以检查并等待datanode关闭。
- 升级并重新启动datanode
- 对子集中所有选定的数据节点并行执行上述步骤。
2. 重复上述步骤,直到升级群集中的所有数据节点。
等待升级完成后,可以查看Web页面,NameNode和DataNode版本已经升级为3.1.2版本:


此时可以已完成滚动升级:
# $HADOOP_HOME/bin/hdfs dfsadmin -rollingUpgrade finalize

如果升级失败,可以随时回滚,回滚,数据会回滚到升级前那一刻的数据,升级后的数据修改,全部失效,回滚启动步骤如下:
# /usr/local/hadoop/bin/hadoop-daemon.sh start namenode –rollback
# /usr/local/hadoop/bin/hadoop-daemon.sh start datanode –rollback
遇到的问题:
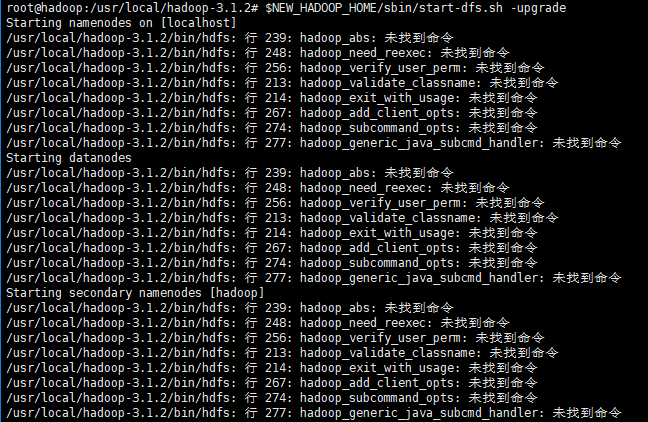
参考网址: https://stackoverflow.com/questions/21369102/hadoop-command-not-found
解决方法:查找配置环境变量的文件,/etc/profile、~/.bashrc、hadoop-env.sh,发现在~/.bashrc文件中配置了HADOOP_HOME,用了旧版本的路径,删除或者更新为新的环境变量即可。
参考资料: 《Hadoop权威指南(第四版)》
Hadoop版本升级(2.7.6 => 3.1.2)的更多相关文章
- Hadoop基本知识,(以及MR编程原理)
hadoop核心是:MapReduce和HDFS (对应着job执行(程序)和文件存储系统(数据的输入和输出)) CRC32作数据交验:在文件Block写入的时候除了写入数据还会写入交验信息,在读取 ...
- Hadoop-调优剖析
1.概述 其实,在从事过调优相关的工作后,会发现其实调优是一项较为复杂的工作.而对于Hadoop这样复杂且庞大的系统来说,调优更是一项巨大的工作,由于Hadoop包含Common.HDFS.MapRe ...
- Apach Hadoop 与 CDH 区别
1.Apache Hadoop 不足之处 • 版本管理混乱 • 部署过程繁琐.升级过程复杂 • 兼容性差 • 安全性低 2.Hadoop 发行版 • Apache Hadoop • Cloudera’ ...
- CDH 1、CDH简介
1.Apache Hadoop 不足之处 • 版本管理混乱 • 部署过程繁琐.升级过程复杂 • 兼容性差 • 安全性低 2.Hadoop 发行版 • Apache Hadoop • Cloudera’ ...
- Docker中Spring boot+VueJS+MongoDB的前后端分离哲学摔跤
此文献给对数据有热情,想长期从事此行业的年轻人,希望对你们有所启发,并快速调整思路和方向,让自己的职业生涯有更好的发展. 根据数据应用的不同阶段,本文将从数据底层到最后应用,来谈谈那些数据人的必备技能 ...
- 淘宝主搜索离线集群完成Hadoop 2
淘宝搜索离线dump集群(hadoop&hbase)2013进行了几次重大升级,本文中将这些升级的详细过程.升级中所遇到的问题以及这些问题的解决方案分享给大家.至此,淘宝主搜索离线集群完全进入 ...
- Hadoop源代码分析
http://wenku.baidu.com/link?url=R-QoZXhc918qoO0BX6eXI9_uPU75whF62vFFUBIR-7c5XAYUVxDRX5Rs6QZR9hrBnUdM ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop 3.x 新特性剖析系列1
1.概述 目前从Hadoop官网的Wiki来看,稳定版本已经发行到Hadoop2.9.0,最新版本为Hadoop3.1.0,查阅JIRA,社区已经着手迭代Hadoop3.2.0.那么,今天笔者就带着大 ...
随机推荐
- React Native 开发豆瓣评分(七)首页组件开发
首页内容拆分 看效果图,首页由热门影院.豆瓣热门.热门影视等列表组成,每个列表又由头加横向滑动的 电影海报列表构成. 所以可以先把页面的电影海报.评分.列表头做成组件,然后在使用 ScrollView ...
- Java 之 Response 发送验证码案例
定义一个 Servlet 用来在内存中生成 二维码图片,并向浏览器页面输出. import javax.imageio.ImageIO; import javax.servlet.ServletExc ...
- k8s基础操作命令
K8s重新加入节点 1.重置node节点环境在slave节点上执行 [root@node2 ~]# kubeadm reset [reset] WARNING: changes made to thi ...
- 《我是一只IT小小鸟》(续)读书笔记——第八周
第三位作者强调了大学阶段规划的重要性,作者初入大学,一切都很新鲜想尝试,却缺乏对学习生活的规划.最终导致的是学习成绩的下降.其实编程也是一样,我们常常感到自己和那些大神的差距,感慨过后,往往也就罢了. ...
- 数据分析之sklearn
一,介绍 Python 中的机器学习库 简单高效的数据挖掘和数据分析工具 可供大家使用,可在各种环境中重复使用 建立在 NumPy,SciPy 和 matplotlib 上 开放源码,可商业使用 - ...
- IT黑马-面向对象
先说面向过程 面向过程主要考虑的是怎么做 把完成摸个需求的 所有步骤 从头到尾 逐步实现 根据开发需求,将某些功能独立的代码封装成一个又一个的函数 最后完成的代码就是顺序的调用不同的函数. 特点是: ...
- Python数据结构汇总
Python数据结构汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.线性数据结构 1>.列表(List) 在内存空间中是连续地址,查询速度快,修改也快,但不利于频繁新 ...
- Jenkins服务器的安装
Jenkins服务器的安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装jdk 详情请参考:https://www.cnblogs.com/yinzhengjie/p/1 ...
- Python基础->for循环、字符串以及元组
python流程控制>for循环.字符串以及元组 学习有关序列的思想.序列:一组有顺序的东西.所有的序列都是由元素组成的,序列中的元素位置是从0开始编号的,最后一个元素的位置是它长度减一. fo ...
- 使用flask搭建微信公众号:接收与回复消息
token验证的意义 在看了别人的代码之后对token加密有了些理解了.但又觉得很鸡肋.第一次验证服务器的时候我在那弄了半天的验证其实不写也可以验证成功,只要直接返回echostr这个字段就行了.微信 ...