浅谈sharding jdbc
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。

配置说明
#### 常用配置
spring.shardingsphere.datasource.names= #数据源名称,多数据源以逗号分隔
spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点。用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
##### 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
##### 用于单分片键的标准分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器
##### 用于多分片键的复合分片场景
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器
##### 行表达式分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法
##### Hint分片策略
spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器
##### 分表策略,同分库策略
spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= #自增列名称,缺省表示不使用自增主键生成器
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID/LEAF_SEGMENT
spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性
spring.shardingsphere.sharding.binding-tables[0]= #绑定表规则列表
spring.shardingsphere.sharding.broadcast-tables[0]= #广播表规则列表
spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位
spring.shardingsphere.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略
spring.shardingsphere.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略
spring.shardingsphere.sharding.default-key-generator.type= #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID/LEAF_SEGMENT
spring.shardingsphere.sharding.default-key-generator.props.<property-name>= #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #详见读写分离部分
spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #详见读写分离部分
spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false
分片实现原理
SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并
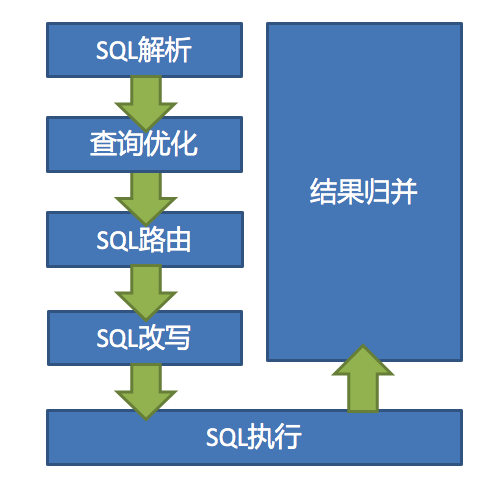

ShardingDataSourceFactory用于创建分库分表或分库分表+读写分离的JDBC驱动
MasterSlaveDataSourceFactory用于创建独立使用读写分离的JDBC驱动。
ShardingRuleConfiguration是分库分表配置的核心和入口,它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。
每一组相同规则分片的表配置一个TableRuleConfiguration。如果需要分库分表和读写分离共同使用,每一个读写分离的逻辑库配置一个MasterSlaveRuleConfiguration。
每个TableRuleConfiguration对应一个ShardingStrategyConfiguration
分库分表标准

这里要说的是数据库切分确实可以解决数据库的单点问题,但是它也会带来整体服务切分后的数据库操作的复杂度.
- 参考资料:
浅谈sharding jdbc的更多相关文章
- 浅谈了解JDBC
目录 前言 作用 JDBC的架构 步骤 JDBC常见的关键字解释 前言 Java数据库连接,是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法.J ...
- 【架构】浅谈web网站架构演变过程
浅谈web网站架构演变过程 前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系统可以如何一步步演变. 该系统具备的功能: 用户模块:用户注册和管理 商品模块:商品展示和管 ...
- !! 浅谈Java学习方法和后期面试技巧
浅谈Java学习方法和后期面试技巧 昨天查看3303回复33 部落用户大酋长 下面简单列举一下大家学习java的一个系统知识点的一些介绍 一.java基础部分:java基础的时候,有些知识点是非常重要 ...
- Hibernate更新部分字段浅谈
update语句是在Hibernate的Configuration的时候生成的,不能动态改变.为什么update的时候所有的属性都一起update,而不是只更新改变字段,其实这是一个比较值得探讨的问题 ...
- [转]浅谈Hive vs. HBase 区别在哪里
浅谈Hive vs. HBase 区别在哪里 导读:Apache Hive是一个构建于Hadoop(分布式系统基础架构)顶层的数据仓库,Apache HBase是运行于HDFS顶层的NoSQL(=No ...
- mongo 3.4分片集群系列之一:浅谈分片集群
这篇为理论篇,稍后会有实践篇. 这个系列大致想跟大家分享以下篇章: 1.mongo 3.4分片集群系列之一:浅谈分片集群 2.mongo 3.4分片集群系列之二:搭建分片集群--哈希分片 3.mong ...
- 朱晔的互联网架构实践心得S2E6:浅谈高并发架构设计的16招
朱晔的互联网架构实践心得S2E6:浅谈高并发架构设计的16招 概览 标题中的高并发架构设计是指设计一套比较合适的架构来应对请求.并发量很大的系统,使系统的稳定性.响应时间符合预期并且能在极端的情况下自 ...
- [转帖]浅谈分布式一致性与CAP/BASE/ACID理论
浅谈分布式一致性与CAP/BASE/ACID理论 https://www.cnblogs.com/zhang-qc/p/6783657.html ##转载请注明 CAP理论(98年秋提出,99年正式发 ...
- 阿里P7浅谈SpringMVC
一.前言 既然是浅谈 SpringMVC,那么我们就先从基础说起,本章节主要讲解以下内容: 1.三层结构介绍 2.MVC 设计模式介绍 3.SpringMVC 介绍 4.入门程序的实现 注:介绍方面的 ...
随机推荐
- Golang-使用md5对字符串进行加密
方式一: func md5Test1(str string) string { m5 := md5.New() _,err := m5.Write([]byte(str)) if err != nil ...
- Java中使用HttpPost上传文件以及HttpGet进行API请求(包含HttpPost上传文件)
Java中使用HttpPost上传文件以及HttpGet进行API请求(包含HttpPost上传文件) 一.HttpPost上传文件 public static String getSuffix(fi ...
- rabbitMq 学习笔记(二) 备份交换器,过期时间,死信队列,死信队列
备份交换器 备份交换器,英文名称为 Altemate Exchange,简称庙,或者更直白地称之为"备胎交换器". 生产者在发送消息的时候如果不设置 mandatory 参数, 那 ...
- SAP开源的持续集成-持续交付的解决方案
SAP开源的持续集成/持续交付的解决方案: (1) 一个叫做piper的github项目,包含一个针对Jenkins的共享库和一个方便大家快速搭建CI/CD环境的Docker镜像: (2) 一套SAP ...
- [JAVASCRIPT][EXTJS]直接用JSON创建树形控件(Ext.tree.TreePanel )(转)
直接用JSON创建树形控件(Ext.tree.TreePanel ) 1.创建多个根节点的树形 2.直接使用JsonList创建树形 <!DOCTYPE HTML PUBLIC "-/ ...
- 小程序canvas绘制倒计时
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. 效果展示: //广告倒计时 advTimeCountDown:function(advTime ...
- [ipsec][strongswan] strongswan源码分析--(五)plugin的配置文件的添加方法与管理架构解析
前言 我们知道,strongswan是基于插件式管理的.不同的插件有不同的配置文件,在这下面, 我们以netlink的插件为例:etc/strongswan.d/charon/kernel-netli ...
- amazeui datepicker日历控件 设置默认当日
amazeui datepicker日历控件 设置默认当日 背景: 最近在做一个系统的时候,前台需要选择日期,传给后台进行处理,每次都需要通过手动点击组件,选择日期,这样子很不好,所以我想通过程序自动 ...
- react native jpush
原文链接:https://blog.csdn.net/qq_38719039/article/details/80684144 1 npm install jpush-react-native --s ...
- java 实现 单链表
class Node{ public int val; public Node next; public Node(int val){ this.val=val; } } class LinkList ...