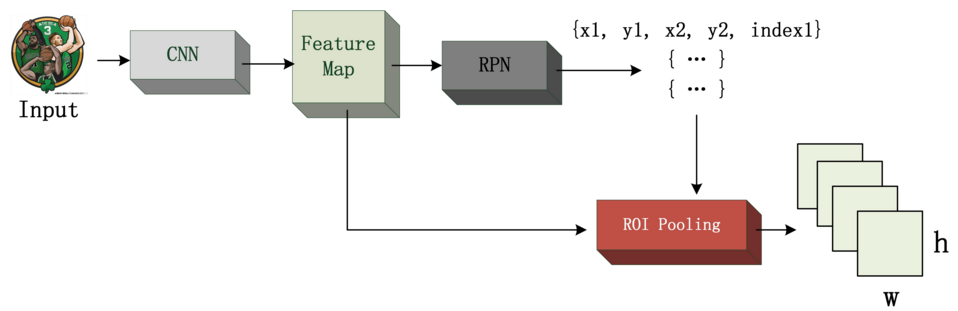
关于RoI pooling 层
ROIs Pooling顾名思义,是pooling层的一种,而且是针对ROIs的pooling;
整个 ROI 的过程,就是将这些 proposal 抠出来的过程,得到大小统一的 feature map。
什么是ROI呢?(https://www.sogou.com/link?url=DOb0bgH2eKh1ibpaMGjuyy_CKu9VidU_Nm_z987mVIMm3Pojx-sH_PfgfR9iaaFcn666hxi--_g.)
ROI是Region of interest的简写,指的是faster rcnn结构中,经过rpn层后,产生的proposal对应的box框。
ROI Pooling的输入
输入有两部分组成:
1. data:指的是进入RPN层之前的那个Conv层的Feature Map,通常我们称之为“share_conv”;
2. rois:指的是RPN层的输出,一堆矩形框,形状为1x5x1x1(4个坐标+索引index),其中值得注意的是:坐标的参考系不是针对feature map这张图的,而是针对原图的(神经网络最开始的输入)
ROI Pooling的输出
输出是batch个vector,其中batch的值等于roi的个数,vector的大小为channelxwxh;ROI Pooling的过程就是将一个个大小不同的box矩形框,都映射成大小为wxh的矩形框;
如图所示,我们先把roi中的坐标映射到feature map上,映射规则比较简单,就是把各个坐标除以输入图片与feature map的大小的比值,得到了feature map上的box坐标后,我们使用pooling得到输出;由于输入的图片大小不一,所以这里我们使用的spp pooling,spp pooling在pooling的过程中需要计算pooling后的结果对应的两个像素点反映社到feature map上所占的范围,然后在那个范围中进行取max或者取average。
---------------------
(https://www.sogou.com/link?url=44aejrzSKwWwrNJcKKLVtEK1rJUb32uHp37TwbVHvja5OaZX_AHBzQ..)
TensorFlow的pool layer是固定大小的
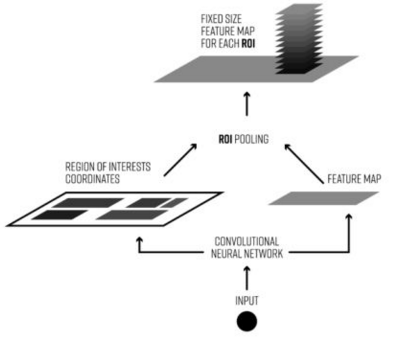
(https://www.sogou.com/link?url=DSOYnZeCC_rR_TP93bdO6GxT14t4sbuOSwJr4L_oLI5lf9NGYfOU6pULrym3hTBVtsCnpVGpPpA.)
RoI Pooling就是实现从原图区域映射到conv5区域最后pooling到固定大小的功能。
输入,b0 为卷积的feature map,b1 为rois。
Reshape
Forward(向前传播)
backward(反向传播)
(https://www.sogou.com/link?url=DSOYnZeCC_rR_TP93bdO6GxT14t4sbuOSwJr4L_oLI5lf9NGYfOU6pULrym3hTBVtsCnpVGpPpA.)
我们知道在Faster R-CNN中,对于每个ROI(文中叫candidate object)主要有两个输出,一个输出是分类结果,也就是预测框的标签;另一个输出是回归结果,也就是预测框的坐标offset。而Mask R-CNN则是添加了第三个输出:object mask,也就说对每个ROI都输出一个mask,该支路是通过FCN网络(如Figure1中的两个卷积层)来实现的。以上这三个输出支路相互之间都是平行关系,相比其他先分割再分类的实例分割算法相比,这种平行设计不仅简单而且高效。
---------------------
作者:AI之路
来源:CSDN
原文:https://blog.csdn.net/u014380165/article/details/81878644
大致回顾下ROI Pool层的操作:
ROI Pool的输入是ROI的坐标和某一层的输出特征,不管是ROI Pool还是ROIAlign,目的都是提取输出特征图上该ROI坐标所对应的特征。RPN网络得到的ROI坐标是针对输入图像大小的,所以首先需要将ROI坐标缩小到输出特征对应的大小,假设输出特征尺寸是输入图像的1/16,那么先将ROI坐标除以16并取整(第一次量化),然后将取整后的ROI划分成H*W个bin(论文中是 7*7,有时候也用14*14),因为划分过程得到的bin的坐标是浮点值,所以这里还要将bin的坐标也做一个量化,具体而言对于左上角坐标采用向下取整,对于右下角坐标采用向上取整,最后采用最大池化操作处理每个bin,也就是用每个bin中的最大值作为该bin的值,每个bin都通过这样的方式得到值,最终输出的H*W大小的ROI特征。从这里的介绍可以看出ROI Pool有两次量化操作,这两步量化操作会引入误差。
---------------------
作者:AI之路
来源:CSDN
原文:https://blog.csdn.net/u014380165/article/details/81878644
关于RoI pooling 层的更多相关文章
- ROI Pooling层详解
目标检测typical architecture 通常可以分为两个阶段: (1)region proposal:给定一张输入image找出objects可能存在的所有位置.这一阶段的输出应该是一系列o ...
- 【ROI Pooling】ROI Pooling层详解(转)
原文链接:https://blog.deepsense.ai/region-of-interest-pooling-explained/ 目标检测typical architecture 通常可以分为 ...
- roi pooling层
roi pooling是先进行roi projection(即映射)然后再池化 映射是把用来训练的图片的roi映射到最后一层特征层(即卷积层).方法其实很简单,图片经过特征提取后,到最后一层卷积层时, ...
- Pytorch中RoI pooling layer的几种实现
Faster-RCNN论文中在RoI-Head网络中,将128个RoI区域对应的feature map进行截取,而后利用RoI pooling层输出7*7大小的feature map.在pytorch ...
- ROI POOLING 介绍
转自 https://blog.csdn.net/gbyy42299/article/details/80352418 Faster rcnn的整体构架: 训练的大致过程: 1.图片先缩放到MxN的尺 ...
- 【转】ROI Pooling
Faster rcnn的整体构架: 训练的大致过程: 1.图片先缩放到MxN的尺寸,之后进入vgg16后得到(W/16,H/16)大小的feature map: 2.对于得到的大小为(W/16,H/1 ...
- ROI pooling
R-CNN需要大量的候选框,对每个候选框都提取特征,速度很慢,无法做到实时检测,无法做到端到端.ROI pooling层实现training和testing的显著加速,并提高检测accuracy. R ...
- TensorFlow中max pooling层各参数的意义
官方教程中没有解释pooling层各参数的意义,找了很久终于找到,在tensorflow/python/ops/gen_nn_ops.py中有写: def _max_pool(input, ksize ...
- caffe之(二)pooling层
在caffe中,网络的结构由prototxt文件中给出,由一些列的Layer(层)组成,常用的层如:数据加载层.卷积操作层.pooling层.非线性变换层.内积运算层.归一化层.损失计算层等:本篇主要 ...
随机推荐
- C++小程序(1)——文件整理工具
网上下载的漫画是jpg或png之类的图片文件,用系统自带的图片管理器看不方便,想要能把图片想网页一样浏览的功能,找了很多图片管理器也没有带这个功能,于是就自己编写了一个小程序实现. 思想就是在图片目录 ...
- Python2以及Python3中的除法
前言 在讨论话题之前,我们先说下程序中除法的三种情况: 1. 传统的除法,我称之为整型地板除.在C.C++.Java中常见,特点是整数相除舍弃小数取整,浮点数相除则保留小数(如果有). >> ...
- java开发移动端之spring的restful风格定义
https://www.ibm.com/developerworks/cn/web/wa-spring3webserv/index.html
- Java上传且后台解析XML文件
后台代码: import java.io.BufferedReader; import java.io.ByteArrayInputStream; import java.io.InputStream ...
- 使用layer.tips实现鼠标悬浮时触发事件提示消息实现
代码: <body> <label id="test" onmouseover="show('test')"> 你瞅啥!?过来试试! & ...
- 9、Collaborative Metric Learning Recommendation System: Application to Theatrical Movie Releases------CML推荐系统(电影院放映的应用)
一.摘要: 主要是做一个基于协作(深度)度量学习(CML)的系统来预测新剧场版本的购买概率.即测量产品的空间距离来预测购买概率. 二.模型 该图分为两部分,先计算右边,右边通过深度度量学习(DDML) ...
- Node_进阶_2
第二天 一.复习: Node.js开发服务器.数据.路由.本地关心效果,交互. Node.js实际上是极客开发出的一个小玩具,不是银弹.有着别人不具备的怪异特点: 单线程.非阻塞I/O.事件驱动. 实 ...
- 搭建hadoop java开发环境
package hadoopDemo; import java.io.IOException; import java.net.URI; import java.net.URISyntaxExcept ...
- SQL的运算符优先级
注: 1.乘除的优先级高于加减: 2.同一优先级运算符从左向右执行: 3.括号内的运算先执行.
- [luogu] P3202 [HNOI2009]通往城堡之路(贪心)
P3202 [HNOI2009]通往城堡之路 题目描述 听说公主被关押在城堡里,彭大侠下定决心:不管一路上有多少坎坷,不管城堡中的看守有多少厉害,不管救了公主之后公主会不会再被抓走,不管公主是否漂亮. ...