spark load data from mysql
spark load data from mysql
code first
本机通过spark-shell.cmd启动一个spark进程
SparkSession spark = SparkSession.builder().appName("Simple Application").master("local[2]").getOrCreate();
Map<String, String> map = new HashMap<>();
map.put("url","jdbc:mysql:xxx");
map.put("user", "user");
map.put("password", "pass");
String tableName = "table";
map.put("dbtable", tableName);
map.put("driver", "com.mysql.jdbc.Driver");
String lowerBound = 1 + ""; //低界限
String upperBound = 10000 + ""; //高界限
map.put("fetchsize", "100000"); //实例和mysql服务端单次拉取行数,拉取后才能执行rs.next()
map.put("numPartitions", "50"); //50个分区区间,将以范围[lowerBound,upperBound]划分成50个分区,每个分区执行一次查询
map.put("partitionColumn", "id"); //分区条件列
System.out.println("tableName:" + tableName + ", lowerBound:"+lowerBound+", upperBound:"+upperBound);
map.put("lowerBound", lowerBound);
map.put("upperBound", upperBound);
Dataset dataset = spark.read().format("jdbc").options(map).load(); //transform操作
dataset.registerTempTable("tmp__");
Dataset<Row> ds = spark.sql("select * from tmp__"); //transform操作
ds.cache().show(); //action,触发sql真正执行
执行到show时,任务开始真正执行,此时,我们单机debug,来跟踪partitionColumn的最终实现方式
debug类
org.apache.spark.sql.execution.datasources.jdbc.JDBCRelation.buildScan
此时parts为size=50的分区列表
override def buildScan(requiredColumns: Array[String], filters: Array[Filter]): RDD[Row] = {
// Rely on a type erasure hack to pass RDD[InternalRow] back as RDD[Row]
JDBCRDD.scanTable(
sparkSession.sparkContext,
schema,
requiredColumns,
filters,
parts,
jdbcOptions).asInstanceOf[RDD[Row]]
}
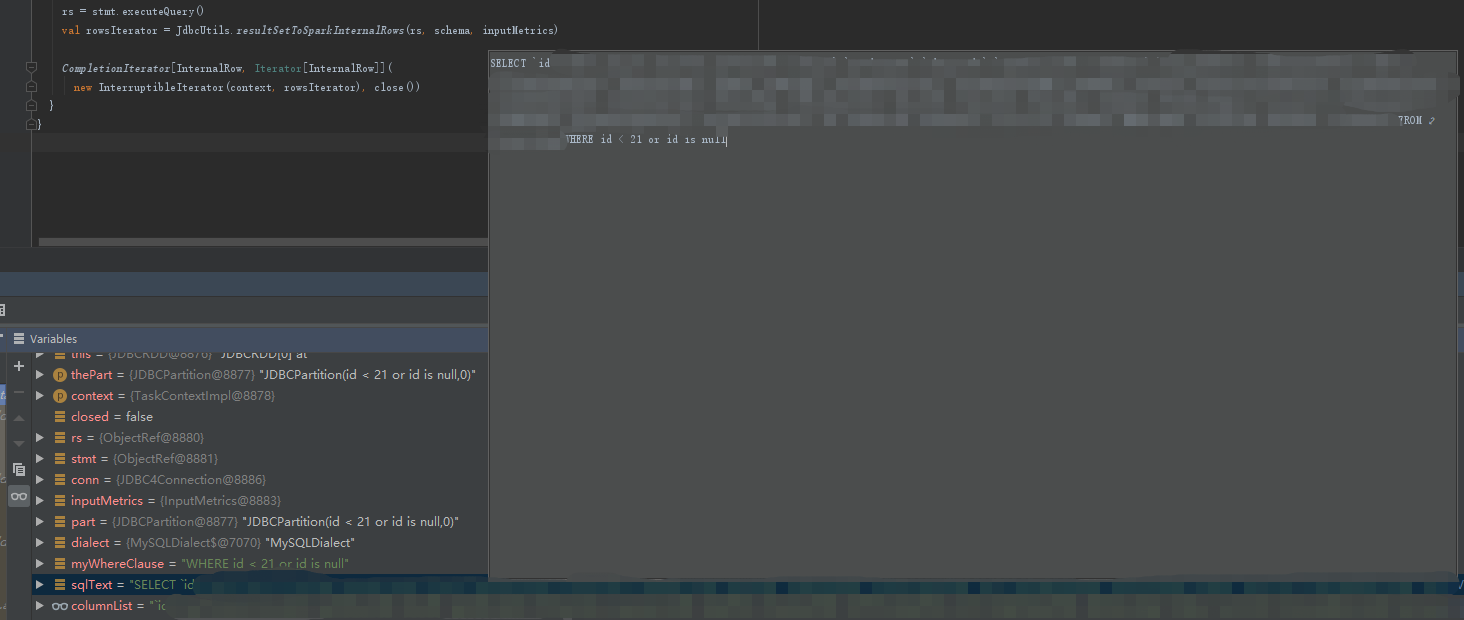
单个分区内的whereClause值
whereCluase="id < 21 or id is null"

继续往下断点,到单个part的执行逻辑,此时代码应该是在Executor中的某个task线程中
org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute
val myWhereClause = getWhereClause(part)
val sqlText = s"SELECT $columnList FROM ${options.table} $myWhereClause"
stmt = conn.prepareStatement(sqlText,
ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY)
stmt.setFetchSize(options.fetchSize)
rs = stmt.executeQuery()
val rowsIterator = JdbcUtils.resultSetToSparkInternalRows(rs, schema, inputMetrics)
CompletionIterator[InternalRow, Iterator[InternalRow]](
new InterruptibleIterator(context, rowsIterator), close())
此时
myWhereClause=WHERE id < 21 or id is null
最终的sql语句
sqlText=SELECT id,xx FROM tablea WHERE id < 21 or id is null
所有part都会经过compute
Executor执行完任务后,将信息发送回Driver
Executor: Finished task 7.0 in stage 2.0 (TID 12). 1836 bytes result sent to driver
总结
- numPartitions、partitionColumn、lowerBound、upperBound结合后,spark将生成很多个parts,每个part对应一个查询whereClause,最终查询数据将分成numPartitions个任务来拉取数据,因此,partitionColumn必须是索引列,否则,效率将大大降低
- 自动获取table schema,程序会执行类型select * from tablea where 1=0 来获取字段及类型
- lowerBound,upperBound仅用来生成parts区间,最终生成的sql中,不会使用它们来作为数据范围的最小或最大值
spark load data from mysql的更多相关文章
- 使用MySQL的SELECT INTO OUTFILE ,Load data file,Mysql 大量数据快速导入导出
使用MySQL的SELECT INTO OUTFILE .Load data file LOAD DATA INFILE语句从一个文本文件中以很高的速度读入一个表中.当用户一前一后地使用SELECT ...
- mysql导入数据load data infile用法整理
有时候我们需要将大量数据批量写入数据库,直接使用程序语言和Sql写入往往很耗时间,其中有一种方案就是使用MySql Load data infile导入文件的形式导入数据,这样可大大缩短数据导入时间. ...
- MySQL 之 LOAD DATA INFILE 快速导入数据
SELECT INTO OUTFILE > help select; Name: 'SELECT' Description: Syntax: SELECT [ALL | DISTINCT | D ...
- Mybatis拦截器 mysql load data local 内存流处理
Mybatis 拦截器不做解释了,用过的基本都知道,这里用load data local主要是应对大批量数据的处理,提高性能,也支持事务回滚,且不影响其他的DML操作,当然这个操作不要涉及到当前所lo ...
- mysql load data 乱码的问题
新学mysql在用load data导入txt文档时发现导入的内容,select 之后是乱码,先后把表,数据库的字符集类型修改为utf8,但还是一样,最后在 http://bbs.chinaunix. ...
- mysql load data infile的使用 和 SELECT into outfile备份数据库数据
LOAD DATA [LOW_PRIORITY | CONCURRENT] [LOCAL] INFILE 'file_name.txt' [REPLACE | IGNORE] INTO TABLE t ...
- 快速的mysql导入导出数据(load data和outfile)
1.load data: ***实际应用:把日志生成的xls文件load到MySQL中: mysql_cmd = "iconv -c -f utf-8 -t gbk ./data/al_ve ...
- [MySQL]load data local infile向MySQL数据库中导入数据时,无法导入和字段不分离问题。
利用load data将文件中的数据导入数据库表中的时候,遇到了两个问题. 首先是load data命令无法执行的问题: 命令行下输入load data local infile "path ...
- mysql导入数据load data infile用法
mysql导入数据load data infile用法 基本语法: load data [low_priority] [local] infile 'file_name txt' [replace | ...
随机推荐
- Prometheus-Alertmanager告警对接到企业微信
之前写过将Prometheus的监控告警信息通过Alertmanager推送到钉钉群. 最近转移了阵地,需要将Prometheus监控告警信息推送到企业微信群,经过两天的摸索,以及查了网上的一些资料, ...
- dubbo学习(三)配置dubbo API方式配置
provider(生产者) import com.alibaba.dubbo.config.ApplicationConfig; import com.alibaba.dubbo.config.Pro ...
- Spring Boot学习(一)初识Spring Boot
Spring Boot 概述 Spring Boot 是所有基于 Spring 开发的项目的起点.Spring Boot 的设计是为了让你尽可能快的跑起来 Spring 应用程序并且尽可能减少你的配置 ...
- 命令执行漏洞攻击&修复建议
应用程序有时需要调用一些执行系统命令的函数,如在PHP中,使用system.exec.shell_exec.passthru.popen.proc_popen等函数可以执行系统命令.当黑客能控制这些函 ...
- Spring学习(九)--Spring的AOP
1.配置ProxyFactoryBean Spring IOC容器中创建Spring AOP的方法. (1)配置ProxyFactoryBean的Advisor通知器 通知器实现定义了对目标对象进行增 ...
- Spring系列之事务的控制 注解实现+xml实现+事务的隔离等级
Spring系列之事务的控制 注解实现+xml实现 在前面我写过一篇关于事务的文章,大家可以先去看看那一篇再看这一篇,学习起来会更加得心应手 链接:https://blog.csdn.net/pjh8 ...
- 读书笔记——Effective C++
1.让自己习惯C++ 条款01:视C++为一个语言联邦 C++高效编程守则视状况而变化,取决于你使用C++的哪一部分. 条款02:尽量以const.enum.inline替换 #define 对于单纯 ...
- 02 ArcPython的使用大纲
一.什么情况下使用ArcPython? 1.现有工具实现不了,可以用python 2.流程化需要时,可以使用python 3.没有AE等二次开发环境 4.其他特殊场景 二.ArcPython在ArcG ...
- sublime text3配置Python2、Python3的编译环境
由于Python2.Python3使用量都很高,Python3虽然是未来趋势,但是目前个别库还是只支持Python2.所以,很多人会选择在电脑上安装两个版本的Python,那么使用sublime执行代 ...
- MySQL 修改表中的字段,使其自增
例如,我想使字段 id 自增. 1.查看表定义 mysql> DESC user; +----------+-------------+------+-----+---------+------ ...