【MySQL 高级】索引优化分析
MySQL高级 索引优化分析
SQL 的效率问题
出现性能下降,SQL 执行慢,执行时间长,等待时间长等情况,可能的原因有:
- 查询语句写的不好
- 索引失效
- 单值索引:在 user 表中给 name 属性建索引
create index idx_user_name on user(name); - 复合索引:在 user 表中给 name、email 属性索引
- 单值索引:在 user 表中给 name 属性建索引
- 由于设计缺陷或业务需求,导致关联查询太多表连接
- 配置文件参数设置以及调优影响
常见的连接查询
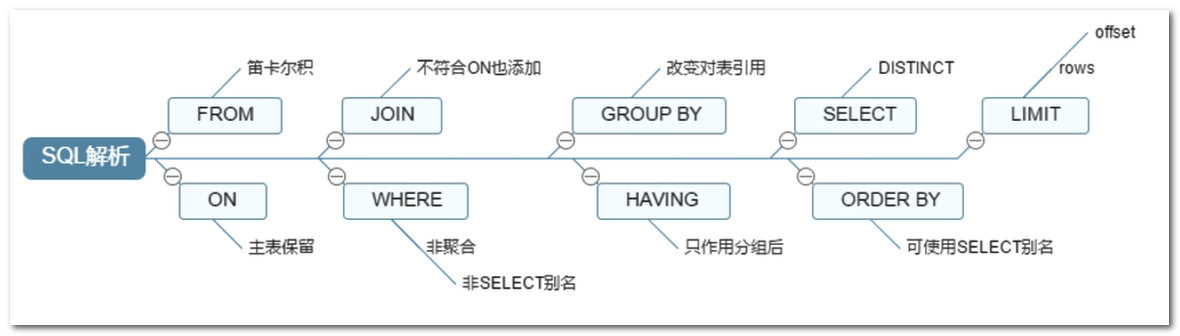
SQL 执行顺序
书写的 SQL 语句顺序:
select distinct <select_list>
from <left_table> <join_type>
join <right_table>
on <join_condition>
where <where_condition>
group by <group_by_list>
having <having_condition>
order by <order_by_condition>
limit <limit_number>
实际的 SQL 执行顺序(常见的):
from <left_table>
on <join_condition>
<join_type> join <right_table>
where <where_condition>
group by <group_by_list>
having <having_condition>
select distinct <select_list>
order by <order_by_condition>
limit <limit_number>
总结可知,实际的执行顺序是从 form 开始执行的。可以有下图形象表示:
连接查询
对于多表连接的问题,一张图就够了。left join 意思是左边的全保留,如果左边的和右边的不符合 on 的条件,那么左边对应右边的列自动为 null。right join 同理。

建表测试
create database MySQLTest;
use MySQLTest;
drop table if exists tbl_dept;
CREATE TABLE tbl_dept(
id INT(11) NOT NULL AUTO_INCREMENT,
deptName VARCHAR(30) DEFAULT NULL,
locAdd VARCHAR(40) DEFAULT NULL,
PRIMARY KEY(id)
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
drop table if exists tbl_emp;
CREATE TABLE tbl_emp (
id INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20) DEFAULT NULL,
deptId INT(11) DEFAULT NULL,
PRIMARY KEY (id),
KEY fk_dept_Id (deptId)
#CONSTRAINT 'fk_dept_Id' foreign key ('deptId') references 'tbl_dept'('Id')
)ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('FD',15);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z3',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z4',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z5',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w5',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w6',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s7',3);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s8',4);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s9',51);
笛卡尔积
tbl_emp 表和 tbl_dept 表的笛卡尔乘积:
select * from tbl_emp, tbl_dept;
可以得知结果集个数为 5 * 8 = 40
inner join
tbl_emp 表 和 tbl_dept 表的公共部分(交集):
select * from tbl_emp e inner join tbl_dept d on e.deptId = d.id;
left join
tbl_emp 表和 tbl_dept 表的 公共部分 加上 tbl_emp 表的独有部分:
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id;
left join without common part
tbl_emp 表的独有部分:
select * from tbl_emp e left join tbl_dept d on d.deptId = d.id where d.id is null;
right join
tbl_emp 表和 tbl_dept 表的 公共部分 加上 tbl_dept 表的独有部分:
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id;
right join without common part
tbl_dept 表的独有部分:
select * from tbl_emp e right join tbl_dept d on d.deptId = d.id where e.id is null;
full join
遗憾的是,MySQL 不支持 full join ,但是可以通过 left join union 联合 right join 实现。
union 用于连接结果集,并且自动去重。
tbl_emp 表和 tbl_dept 表的 公共部分 加上 tbl_emp 表的独有部分 加上 tbl_dept 表的独有部分:
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id
union
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id;
full join without common part
tbl_emp 表的独有部分 加上 tbl_dept 表的独有部分:
select * from tbl_emp e left join tbl_dept d on e.deptId = d.id where d.id is null
union
select * from tbl_emp e right join tbl_dept d on e.deptId = d.id; where e.od id null;
索引简介
索引概念
- 索引是一种用于快速查询和检索数据的数据结构,需要占据物理空间,它们包含着对数据表所有记录的引用指针。常见的索引结构有: B树、B+树 和 Hash。
- 平时所说的索引,如果没有特别指明,都是指 B树 结构的索引。
- 聚集索引、次要索引、覆盖索引、复合索引、前缀索引、唯一索引默认都是使用 B+树 结构的索引,统称索引。
- 通俗的讲,索引就相当于书的目录,为了方便查找书中的内容,可以通过对内容建立索引形成目录。
索引原理
除了数据之外,数据库还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用或者指向数据,这样就可以在这些数据结构上实现高级查找算法,加快执行速度。这里的数据结构就是我们常说的索引。
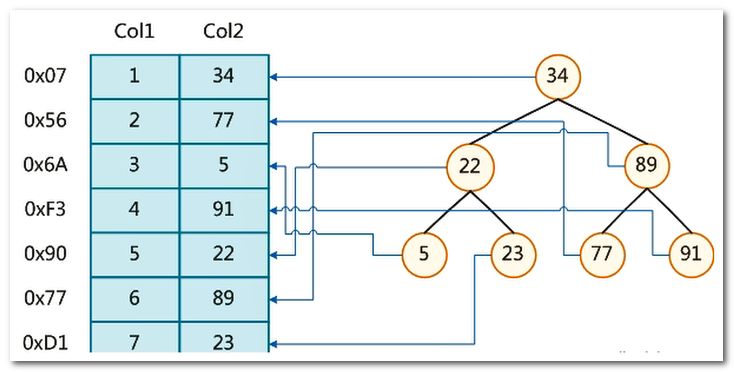
一种可能的索引形式,如下图:
左边是数据表,表的最左边的十六进制数字是数据记录的物理位置。
为了加快 Col2 的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含着索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用 二叉查找 在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
索引优缺点
- 优点:
- 可以提高数据检索效率,降低数据库的 IO 成本。
- 可以降低数据排序成本,降低 CPU 的消耗。
- 缺点:
- 索引实际上是一张表,它保存了主键和索引字段,并指向实体表。它也是需要占据物理空间的。
- 会降低更新表的速度,对表进行增删改操作,MySQL 不仅要保存数据,而且还有更新索引。
- 对于大数据量的表,建立良好的索引是比较困难的。
索引分类
- 普通索引:最基本的索引类型,没有什么特别的限制。
ALTER TABLE table_name ADD INDEX index_name (column(length));创建普通索引ALTER TABLE table_name ADD INDEX index_name (column1(length), colimn2(length));创建普通组合索引
- 唯一索引:数据列不能重复,能为 NULL,一个表可以有多个唯一索引。
ALTER TABLE table_name ADD UNIQUE (column(length));创建唯一索引ALTER TABLE table_name ADD UNIQUE (column1(length), column2(length));创建唯一组合索引
- 主键索引:数据列不能重复,不能为 NULL,一个表只能有一个主键索引。
ALTER TABLE table_name ADD PRIMARY KEY (column(length));创建主键索引
- 组合索引:
ALTER TABLE table_name ADD INDEX index_title_time (title(length), time(length));创建组合索引- 这个组合索引,相当于
title, time和title两种索引。 - 为什么没有
time这个索引呢?这是因为 MySQL 组合索引 最左前缀的规则 ,即 只从最左面的开始组合,并不是只要包含这两列的查询都会用到该组合索引。
- 全文索引:目前搜索引擎关键的技术,MyISAM 支持,InnoDB 不支持。
ALTER TABLE table_name ADD FULLTEXT (column(length));创建全文索引
索引使用
- 创建索引:
- 如果是 CHAR 和 VARCHAR 类型,length 可以小于字段实际长度。
- 如果是 BLOB 和 TEXT 类型,必须指定 length。
- 直接创建
create index_type [index_name] on table(column_name(length)) - 修改表结构创建
alter table table_name add index_type [index_name] (column_name) - 创建表时同时创建
create table xx (index_type [index_name] (column_name(length)))
- 删除索引:
- 直接删除 drop index 索引名 on 表名
- 改表结构删除 alter table 表名 drop index 索引名
- 查看索引:
EXPLAIN select * fromindex_demod where d.e_name = 'Jane';查看 SQL 语句对索引的使用情况show index from 表名;查看已创建的索引
索引结构
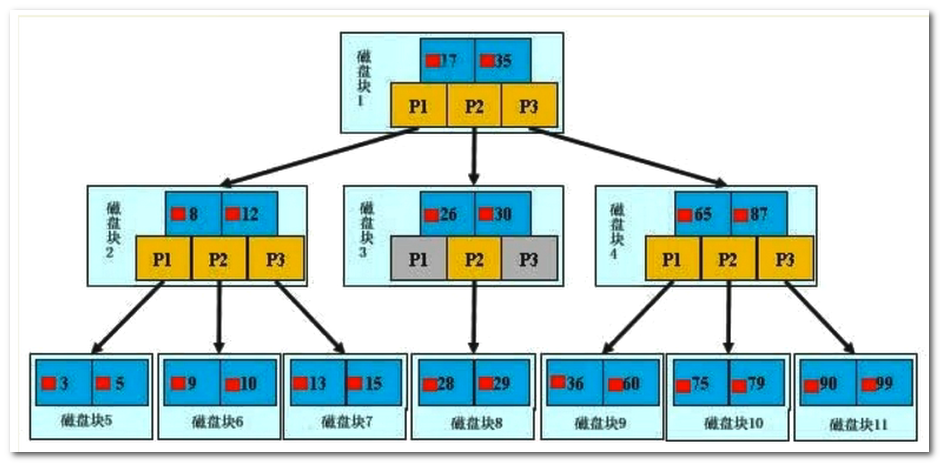
B 树
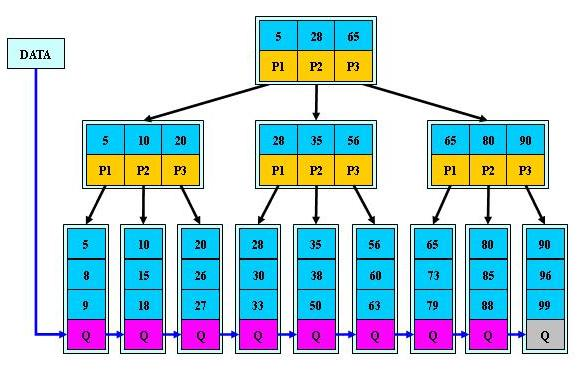
B+ 树
索引使用时机
性能分析
索引优化
总结和练习
【MySQL 高级】索引优化分析的更多相关文章
- MySQL的索引优化分析(一)
一.SQL分析 性能下降.SQL慢.执行时间长.等待时间长 查询语句写的差 索引失效关联查询太多join(设计缺陷) 单值索引:在user表中给name属性创建索引,create index idx_ ...
- MySQL的索引优化分析(二)
一.索引优化 1,单表索引优化 建表 CREATE TABLE IF NOT EXISTS article( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO ...
- MySQL高级-索引优化
索引失效 1. 2.最佳左前缀法则 4. 8. 使用覆盖索引解决这个问题. 二.索引优化 1.ORDER BY 子句,尽量使用Index方式排序,避免使用FileSort方式排序 MySQL支持两种方 ...
- 【mysql】索引优化分析
1. 索引的概念 1.1 索引是什么 MySQL 官方对索引的定义为:索引(Index)是帮助MySQL 高效获取数据的数据结构.可以得到索引的本质:索引是数据结构.可以简单理解为排好序的快速查找数据 ...
- Mysql 索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- mySql索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- 知识点:Mysql 数据库索引优化实战(4)
知识点:Mysql 索引原理完全手册(1) 知识点:Mysql 索引原理完全手册(2) 知识点:Mysql 索引优化实战(3) 知识点:Mysql 数据库索引优化实战(4) 一:插入订单 业务逻辑:插 ...
- MySQL高级学习笔记(四):索引优化分析
文章目录 性能下降 SQL慢 执行时间长 等待时间长 查询语句写的烂 查询数据过多 关联了太多的表,太多join 没有利用到索引 单值 复合 服务器调优及各个参数设置(缓冲.线程数等)(不重要DBA的 ...
- MySQL高级第二章——索引优化分析
一.SQL性能下降原因 1.等待时间长?执行时间长? 可能原因: 查询语句写的不行 索引失效(单值索引.复合索引) CREATE INDEX index_user_name ON user(name) ...
随机推荐
- GYM100526I Interesting Integers
题目大意 定义一种 \(Gabonacci\) 数列: \[\begin{array}{c} G_1=a\\ G_2=b\\ G_i=G_{i-1}+G_{i-2} \end{array} \] 给定 ...
- 在Qt中配置海康工业相机SDK及遇到的问题(报错)
1.在项目的.pro文件里导入海康工业相机的SDK路径 INCLUDEPATH += \ D:\HKVersion\MVS_3.1.0\MVS\Development\Includes #这时到入Op ...
- django APIview使用
1.APIview使用 ModelVIewSet 是对 APIView 封装 ModelSerializer 是对 Serializer 1.1 在 user/urls.py 中添加路由 urlpat ...
- pip下载超时问题详解
前言 pip下载的安装包都是在国外的pipy服务器上面,又因国内某种墙的策略,导致速度非常的慢,甚至无法访问. 于是国内很多的企业和爱好者纷纷搭建自己的服务器,定时从pypi上拉起所有的镜像文件.然后 ...
- Unity 黑暗之光 笔记 第一章
第一章 设计游戏开始进入场景 1.设置相机视野同步 选中要调整的相机 GameObject - Align With View(快捷键 Ctrl + Shift + F)
- Greenplum 性能优化之路 --(一)分区表
一.什么是分区表 分区表就是将一个大表在物理上分割成若干小表,并且整个过程对用户是透明的,也就是用户的所有操作仍然是作用在大表上,不需要关心数据实际上落在哪张小表里面.Greenplum 中分区表的原 ...
- Feign String 参数 传递null 以及 空字符串问题
笔记链接:https://app.yinxiang.com/fx/c82f6d74-3432-4703-83c8-5175f5986f97 备注 因为笔记在印象笔记上进行编辑,而且为Markdown格 ...
- npm的下载与安装
1.Node (1)什么是Node.js Node.js 就是运行在服务端的 JavaScript.Node.js 是一个基于Chrome JavaScript 运行时建立的一个平台. (2)Node ...
- 多任务-python实现-多线程共享全局变量(2.1.3)
@ 目录 1.全局变量的修改 2.全局变量在多线程中的共享 3.多线程可能遇到的问题 1.全局变量的修改 代码实现 num = 100 nums = [11,22] def test(): globa ...
- 在python中元组与列表的区别及序列解包
一. 元组与列表的区别 元组中的数据一旦定义就不允许更改. 元组没有append().extend()和insert()等方法,无法向元组中添加元素. 元组没有remove()或pop()方法,也无法 ...