Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题。这个时候数据库的优化就显得尤为重要,在说优化方案前,先分析下数据库性能瓶颈的原因有哪些;
1.1数据库性能瓶颈的分析
比如说在高并发的情况下连接数不够了。或者数据量太大,查询效率变得越来越低。或者是因为存储的问题,数据库所在的机器性能下降了。这些问题,归根结底都是受到了硬件的限制,比如 CPU,内存,磁盘,网络等等。在集中式的架构里面,我们一般是增加硬件设施来解决这些问题的,比喻换CPU,升级内存,扩展磁盘,升级带宽等等。但我们本次要说的不是硬件的优化,作为一个程序员,如果只会增加硬件那也没有啥优越感;言归正传,下面来说下数据库的软优化方案;
1.2数据库优化方案对比
1.2.1、重启
可能有很多朋友觉得这有点搞笑,但重启真是释放资源的最好方法;对于很久都没关闭的数据库服务器,重启会使其释放资源,导致反应 速度会很多;所以对于夜间服务器空隙时间长的公司,可以写一个脚本,让数据库在夜间空隙时进行自动重启;
1.2.1 SQL 与索引
当 SQL 语句写得非常复杂,比如关联的表非常多,条件非常多,查询所消耗的时间非常长,这样的一个 SQL 就叫慢 SQL,关于慢SQL我 在去年的文章中有讲解,有兴趣可以自己去看下。因为 SQL 语句是我们自己编写的,可控性是最高的,所以第一步就是检查 SQL。在很多情 况下我们优化的目标是为了用到索引。
1.2.2 表与存储引擎
如果 SQL 本身没有什么大问题,我们接着就要检查我们查询的目标,也就是表结构的设计有没有问题。比如你对于字段类型和长度的选 择,或者表结构是不是需要拆分或者合并,不同的表应该选择什么存储引擎,是不是要分区等等。
1.2.3 架构
表结构如果也没有问题,那就要上升到数据库服务的层面,从架构层面进行优化。因为数据都是在磁盘上存储,如果加了索引还是很慢,干脆可以把数据在内存里面缓存起来,这个时候可以部署缓存服务器。查询数据先查缓存,没有再查数据库,例如(布隆过滤器)。这样既可以减少数据库的压力,又可以提升查询速度。如果一台数据库服务器承受不了访问压力,可以部署集群做负载均衡。当然这些数据库节点应该有自动同步的机制。有了主从同步之后,就可以主从复制实现读写分离,让写的服务都访问 master 服务器,读的请求都访问从服务器。有了读写分离之后,问题并没有完全解决:1、只有一个 master,写的压力没有得到分摊;2、所有的节点都存储相同的数据,在一个节点出现存储瓶颈的时候,磁盘不够用了其他的节点也一样会遇到这个问题。所以这个时候我们要用到分布式环境中一个非常重要的手段:分片,每个节点都只存储总体数据的一部分,那这个就是我们今天要说分库分表。分片以后,为了提升可用性,可以再对分片做冗余。
1.2.4 数据库配置
如果通过架构层面没有解决问题,或者机器虽然配置很高但是性能没有发挥到极致,还可以优化数据库的配置,比如连接数,缓冲区大小等等。
二、 分库分表的类型和特点
拆分一共就两种,一种叫垂直拆分,一种叫水平拆分。
垂直切分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。
水平切分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的切分。
2.1垂直切分
垂直分表有两种,一种是单库的,一种是多库的。字段太多了,就要拆表,表太多了,就要拆库。
2.1.1 单库垂直分表
单库分表,比如:用户信息表,拆分成基本信息表,联系方式表等等。
2.1.2 多库垂直分表
多库垂直分表就是把原来存储在一个库的不同的表,拆分到不同的数据库。比喻说当如果数据库中有一个表的增长速度非常快,当垂直切 分并没有从根本上解决单库单表数据量过大的问题。在这个时候,我们还需要对我们的数据做一个水平的切分。这个时候,一个应用需要多个数据库。
2.2水平切分
水平切分就是按照数据的维度分布不同的表中,可以是单库的,也可以是多库的。
2.2.1 单库水平分表
这个拿银行的交易系统讲解最容易,银行的每天交易流水非常大,但是大部分客户只会查近一年或近一个月的流水单,对于历史非常长的流水访问量会少很多,这时就可以对流水表进行水平拆分了。
2.2.2 多库水平分表
另一种是多库的水平分表。比如客户表,我们拆分到多个库存储,表结构是完全一样的。
2.3分库分表带来的问题
前面说了很多分库分表的场景及好处,但世间万物都是有利就有弊;下面就来说下他的弊端。
2.3.1 跨库关联查询
比如在跨库关联时,由于要关联的表是在不同的数据库,那么我们肯定不能直接使用 join 的这种方式去做关联查询。但我们有几个解决方案,例如字段冗余、mycat等。
2.3.2 分布式事务
如果是在一个数据库里面,我们可以用本地事务来控制,但是在不同的数据库里面就不行了。这里必须要出现一个协调者的角色,让大家统一行动,而且要分成多个阶段,一般是先确定都能成功才成功,只要有一个人不能成功,就要全部失败。
三、 Mycat 概念与配置
3.1 Mycat 介绍与核心概念
Mycat的官网网址:http://www.mycat.org.cn/;mycat运行在应用和数据库之间,可以当做一个 MySQL 服务器使用(不论是在工具还是在代码或者命令行中都可以直接连接)。实现对 MySQL 数据库的分库分表,也可以通过 JDBC 支持其他的数据库。
Mycat 的关键特性:
- 可以当做一个 MySQL 数据库来使用
- 支持 MySQL 之外的数据库,通过 JDBC 实现
- 解决了我们提到的所有问题,多表 join、分布式事务、全局序列号、翻页排序
- 支持 ZK 配置,带监控 mycat-web(已经停止维护)
- 2.0 已经发布;文档许久没有更新

3.2 Mycat 配置详解
我们先从官网下载Mycat包,有各种版本,我为了方便下了win

Mycat 解压以后有 5 个目录:
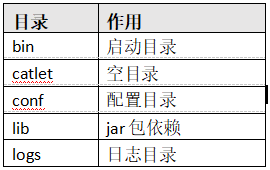
主要的配置文件 server.xml、schema.xml、rule.xml 和具体的分片配置文件。
3.2.1 server.xml
包含系统配置信息。
system 标签:例如字符集、线程数、心跳、分布式事务开关等等。
user 标签:配置登录用户和权限。
<user name="root" defaultAccount="true">
<property name="password">root</property>
<property name="schemas">ghymycat,ljxmycat</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
3.2.2 schema.xml
schema 在 MySQL 里面跟数据库是等价的。schema.xml 包括逻辑库、表、分片规则、分片节点和数据源,可以定义多个 schema。
这里面有三个主要的标签(table、dataNode、dataHost):
<table/>
表名和库名最好都用小写
定义了逻辑表,以及逻辑表分布的节点和分片规则:
<schema name="ghymycat" checkSQLschema="false" sqlMaxLimit="100">
<!--范围分片表-->
<table name="customer" primaryKey="id" dataNode="103-ghymycat,104-ghymycat,105-ghymycat" rule="auto-sharding-long" />
<!--ER分片表-->
<table name="er_scope" dataNode="103-ghymycat,104-ghymycat,105-ghymycat" rule="mod-long-order" >
<childTable name="er_detail" primaryKey="id" joinKey="er_id" parentKey="er_id"/>
</table>
<table name="mycat_sequence" dataNode="103-ghymycat" autoIncrement="true" primaryKey="id"></table>
</schema> <schema name="ljxmycat" checkSQLschema="false" sqlMaxLimit="100">
<!--取模分片表-->
<table name="student" primaryKey="sid" dataNode="103-ljxmycat,104-ljxmycat,105-ljxmycat" rule="mod-long" />
<!--非分片表-->
<table name="noshard" primaryKey="id" autoIncrement="true" dataNode="103-ljxmycat" />
<!--全局表-->
<table name="dict" primaryKey="id" type="global" dataNode="103-ljxmycat,104-ljxmycat,105-ljxmycat" />
<!--单库分片表-->
<table name="fee" primaryKey="id" subTables="fee2025$1-3" dataNode="103-ljxmycat" rule="sharding-by-month" />
</schema>
|
配置 |
作用 |
|
checkSQLschema |
在查询 SQL 中去掉逻辑库名 |
| sqlMaxLimit |
自动加上 limit 控制数据的返回 |
|
primaryKey |
指定该逻辑表对应真实表的主键。MyCat 会缓存主键(通过 primaryKey 属性配置)与具体 dataNode 的信息。 primaryKey 当分片规则(rule)使用非主键进行分片时,那么在使用主键进行查询时,MyCat 就会通过缓存先确定记录在哪个 dataNode 上,然后再在该 dataNode 上执行查询。 如果没有缓存/缓存并没有命中的话,还是会发送语句给所有的 dataNode。 |
|
dataNode |
数据分片的节点 |
|
autoIncrement |
自增长(全局序列),true 代表主键使用自增长策略 |
|
type |
全局表:global。其他:不配置 |
<!--数据节点与物理数据库的对应关系-->
<dataNode name="103-ghymycat" dataHost="host103" database="ghymycat" />
<dataNode name="104-ghymycat" dataHost="host104" database="ghymycat" />
<dataNode name="105-ghymycat" dataHost="host105" database="ghymycat" /> <dataNode name="103-ljxmycat" dataHost="host103" database="ljxmycat" />
<dataNode name="104-ljxmycat" dataHost="host104" database="ljxmycat" />
<dataNode name="105-ljxmycat" dataHost="host105" database="ljxmycat" />
配置物理主机的信息,readhost 是从属于 writehost 的。
<dataHost name="host103" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.2.103:3306" user="root"
password="root">
</writeHost>
</dataHost> <dataHost name="host104" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.2.104:3306" user="root"
password="root">
<!-- <readHost host="hostS1"></readHost> -->
</writeHost>
</dataHost> <dataHost name="host105" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.2.105:3306" user="root"
password="root">
</writeHost>
</dataHost>
balance:负载的配置,决定 select 语句的负载

writeType:读写分离的配置,决定 update、delete、insert 语句的负载

switchType:主从切换配置

3.2.3 rule.xml
定义了分片规则和算法分片规则:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
分片算法:
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
分片配置:
autopartition-long.txt
10001-20000=1 0-10000=0 20001-100000=2
3.3 Mycat 分片验证
先准备三个数据库,我是在建了三个虚拟机,分别在每台上装了mysql

--在所有数据库节点上创建数据库ghymycat,创建3张表
-- 范围分片表
CREATE TABLE `scope` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- ER分片表
CREATE TABLE `er_scope` (
`er_id` int(11) NOT NULL ,
`uid` int(11) DEFAULT NULL ,
`nums` int(11) DEFAULT NULL,
`state` int(2) DEFAULT NULL,
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`er_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- ER分片表
CREATE TABLE `er_detail` (
`er_id` int(11) NOT NULL,
`id` int(11) NOT NULL,
`goods_id` int(11) DEFAULT NULL,
`price` decimal(10,2) DEFAULT NULL,
`is_pay` int(2) DEFAULT NULL,
`is_ship` int(2) DEFAULT NULL,
`status` int(2) DEFAULT NULL,
PRIMARY KEY (`er_id`,`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 创建表,在三个ljxmycat库中创建dict及student表
CREATE TABLE `dict` (
`id` int(11) DEFAULT NULL,
`param_code` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`param_name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; CREATE TABLE `student` (
`sid` int(8) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`qq` varchar(255) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; -- 在第一个数据库ljxmycat节点(103)数据库创建非分片表
CREATE TABLE `noshard` (
`id` bigint(30) DEFAULT NULL,
`name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; truncate table noshard; -- 库内分表
-- 在第一个数据库ljxmycat节点(103)数据库创建单库分片表
CREATE TABLE `fee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin; CREATE TABLE `fee20251` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`create_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `fee20252` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`create_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `fee20253` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`create_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`)
);
启动mycat
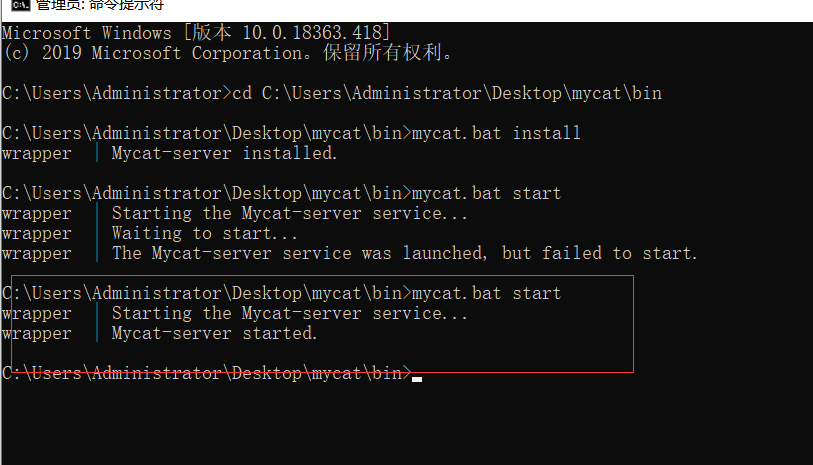
如上图红框所示就代表启动成功,mycat的默认端口是8066,我们用Navicat premium连接成功所会如下图所示,他会把所有表内容进行一个聚合;

3.3.1 范围分片
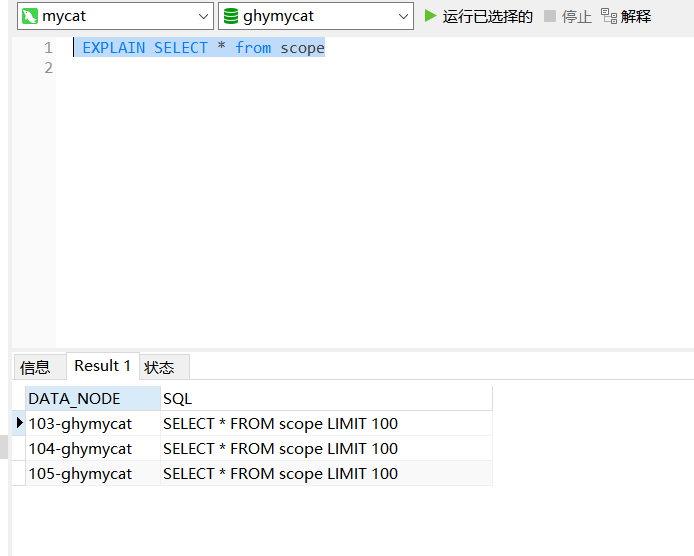
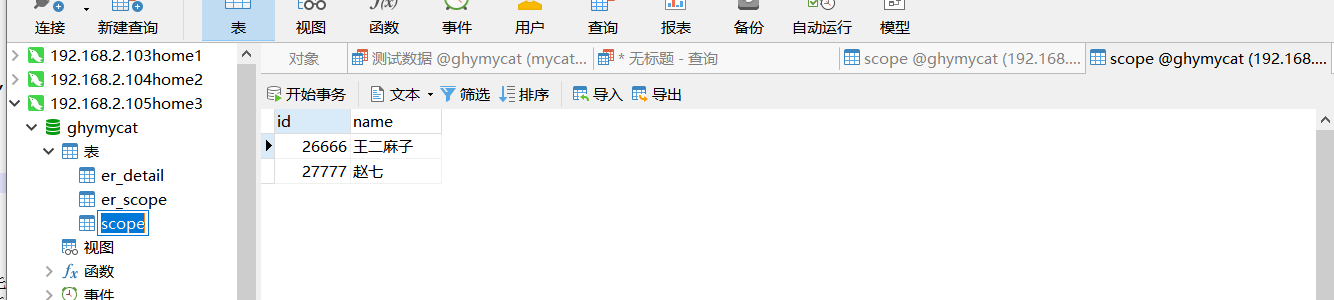
在mycat的ghymycat中执行分片测试数据,scpoe是按范围进行分配的,分配的规则前面也有配置
-- 范围分片scope表
INSERT INTO `scope` (`id`, `name`) VALUES (6666, '张三');
INSERT INTO `scope` (`id`, `name`) VALUES (7777, '李四');
INSERT INTO `scope` (`id`, `name`) VALUES (16666, '王五');
INSERT INTO `scope` (`id`, `name`) VALUES (17777, '孙六');
INSERT INTO `scope` (`id`, `name`) VALUES (26666, '王二麻子');
INSERT INTO `scope` (`id`, `name`) VALUES (27777, '赵七')
插入数据完成后我们查看 ,会发现是分散在三个数据库上的


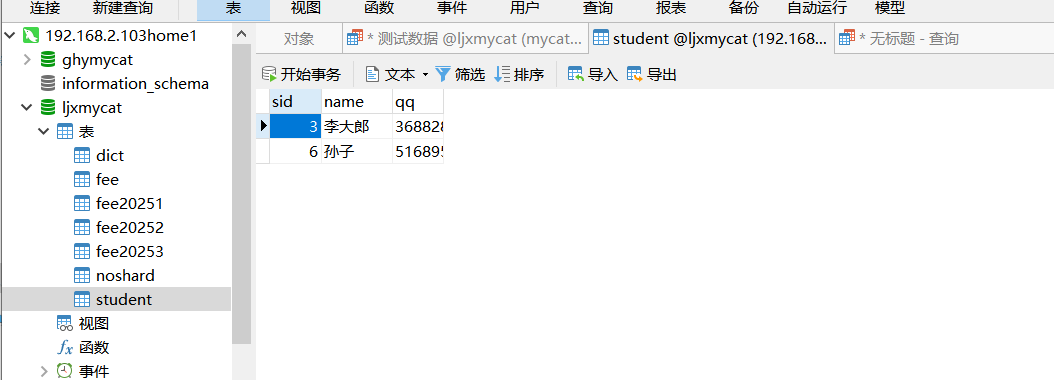
3.3.2 取模分片表
ljxmycat库中的student表,我们从下图可知,我们配置的模数是3

-- 取模分片表(ljxmycat库中的student表)
-- 测试取模分片(在mycat连接中ljxmycat数据库中执行)
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (1, '张三', '166669999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (4, '李四', '655556666');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (2, '王五', '466669999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (5, '赵六', '265286999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (3, '李大郎', '368828888');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (6, '孙子', '516895555');
插入完成后自己可以查下,会发现模余数0的在第一个接点,余数1的在第二个节点上,余数2的在第三个节点上
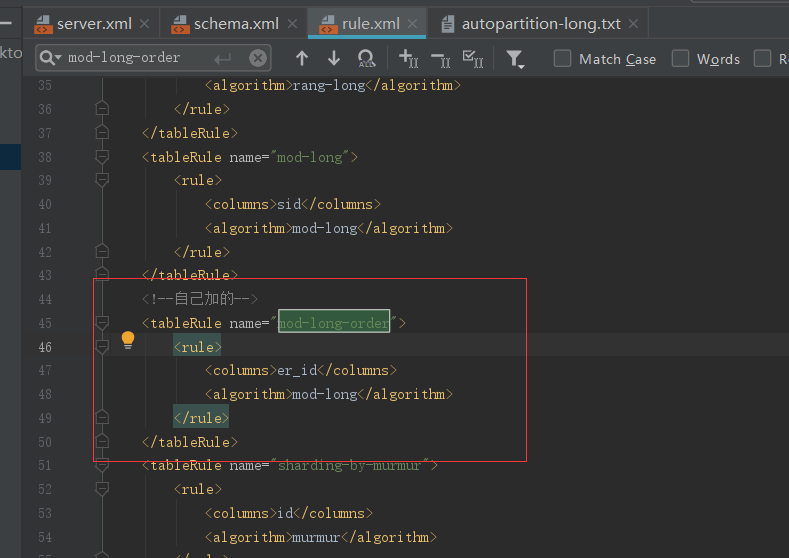
3.3.3 取模分片(ER 表)
在实际生产环境中我们有些表的数据是存在逻辑的主外键关系的,比如订单表 er_scope和er_detail,有主外键的配置如下图
执行插入数据
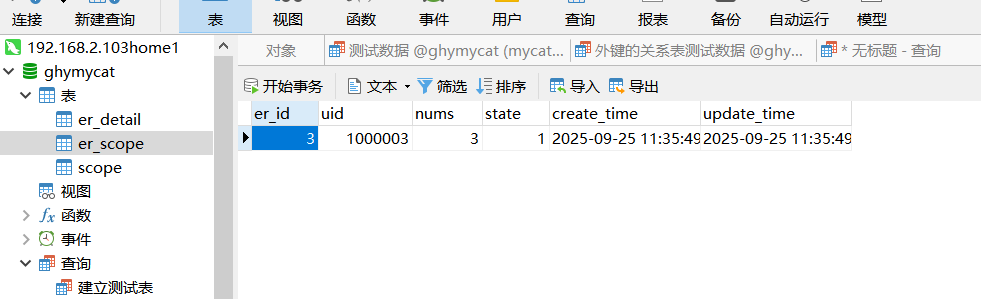
INSERT INTO `er_scope` (`er_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (1, 1000001, 1, 2, '2025-9-23 14:35:37', '2025-9-23 14:35:37'); INSERT INTO `er_scope` (`er_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (2, 1000002, 1, 2, '2025-9-24 14:35:37', '2025-9-24 14:35:37'); INSERT INTO `er_scope` (`er_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (3, 1000003, 3, 1, '2025-9-25 11:35:49', '2025-9-25 11:35:49'); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (3, 20180001, 85114752, 19.99, 1, 1, 1); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (1, 20180002, 25411251, 1280.00, 1, 1, 0); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (1, 20180003, 62145412, 288.00, 1, 1, 2); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180004, 21456985, 399.00, 1, 1, 2); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180005, 21457452, 1680.00, 1, 1, 2); INSERT INTO `er_detail` (`er_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180006, 65214789, 9999.00, 1, 1, 3);
插入完成后我们会发现模数分布规则和上一个例子一样,唯一区别的是,关联的外键表数据存放会和主表放在同一个库里面

3.3.4 全局表
ljxmycat数据库,dict 表:全局表
执行下面语句插入
INSERT INTO `dict` (`id`, `param_code`, `param_name`) VALUES (1, '111', '全局就是所有库都有一样的');
3.3.5 非分片表
ljxmycat数据库,noshard 表
INSERT INTO `noshard` (`id`, `name`) VALUES (1, '分片的数据');
3.3.6 库内分表
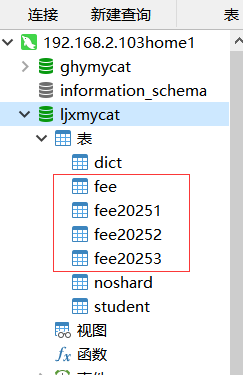
插入数据
INSERT INTO `fee` (`id`, `create_time`) VALUES (1, '2025-1-1 14:46:19'); INSERT INTO `fee` (`id`, `create_time`) VALUES (2, '2025-2-1 14:46:19'); INSERT INTO `fee` (`id`, `create_time`) VALUES (3, '2025-3-1 14:46:19');
然后自己在对应的物理库查看可以看到在一个库里分表了
3.4 Mycat 全局 ID
关于全局ID这块网上有篇文章写的挺全的,如果要配置可以参照文章中配置,网址:https://blog.51cto.com/mynode/1910570
Mycat分库分表(一)的更多相关文章
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- MyCat | 分库分表实践
引言 先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式. 切分模式 一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之 ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- mycat分库分表 看这一篇就够了
之前我们已经讲解过了数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同 ...
- MYCAT分库分表
一.整体架构 1.192.168.189.130:mysql master服务,两个数据库db_store.db_user,db_store做了主从复制 db_user: 用户表users为分片表 数 ...
随机推荐
- mongoose 查询数据属性为数组,且包含某个值的方法
mongoose在创建schema的时候有些属性需要设置为数组类型,比如商品图片.商品标签.不同尺寸.价格等. 那么怎么查询具有某个标签的商品了,下面记录一下两种情况: 查询具有'vue'标签的文章 ...
- 多测师讲解selenium _携程选票定位练习_高级讲师肖sir
打开携程网 from selenium import webdriverfrom time import sleepfrom selenium.webdriver.common.keys import ...
- 【转】Linux-CentOS7设置程序开启自启步骤!
链接:https://blog.csdn.net/wang123459/article/details/79063703
- day08 Pyhton学习
一.昨日内容回顾 .1.基础部分的补充 join() 把列表变成字符串, 拼接 split() 切割 删除: 列表和字典不能在循环的时候进行删除. 把要删除的内容记录在一个新列表中,然后循环新列表, ...
- day21 Pyhton学习 模块
一.模块:就是一个包含了python定义和声明的文件,文件名是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1.使用python编写的代码(.py文件) 2.已被编译为共 ...
- 【数论】HAOI2012 容易题
题目大意 洛谷链接 有一个数列A已知对于所有的\(A[i]\)都是\(1~n\)的自然数,并且知道对于一些\(A[i]\)不能取哪些值,我们定义一个数列的积为该数列所有元素的乘积,要求你求出所有可能的 ...
- 如何制作一个vagrant box
因为要用的窗口应用,基于服务器的各种box不能使用(曾经尝试安装桌面,没有成功).所以试着基于Ubuntu的虚拟机创建自己的box. 过程中主要参考了这篇文章:http://www.360do ...
- Linux系统及第三方应用官方文档
通过在线文档获取帮助 http://www.github.com https://www.kernel.org/doc/html/latest/ http://httpd.apache.org htt ...
- vue知识点12
知识点归纳整理如下: 1. 数组用下标改变,或者对象增加属性,这样的改变数据 是不能触发视图更新的,要用 Vue.set(对象,属性,值) 或this.$set(对象,属性,值) 2. this. ...
- v s
关键字volatile是线程同步的轻量级实现,所以volatile性能肯定比synchronized要好,并且只能修改变量,而synchronized可以修饰方法,以及代码块. ...