kafka 数据存储和发送
摘要
前面我们已经解释获取和更新metadata以及重要性,那么如何给topic 发送数据?
kafkaclient和broker通信,有很多种情况,核心的broker提供的接口有6个
元数据接口(Metadata API),生产消息接口(Produce API),获取消息接口(Fetch API)
偏移量接口(Offset API),偏移量提交接口(Offset Commit API),偏移量获取接口(Offset Fetch API)
如何发送数据,只要研究一下生产消息接口就有一个简单了解啦,贴一下,JSON版本的API,方便理解(根据源码改的,实际请求API非JSON这种序列化方式,而是自定义的序列化的方式)

1,从上面可以看出kafka-client,每次发送消息的时候,不是一条一条发,而是有一个集合这种概念,kafka-client 将同一个topic的partition下的请求,都放到一起,构成messageSet
2,然后按照topic分组,批量发送消息
结合着kafka 消息模型(V0 版本)或许大家理解起来上面的json api,更容易
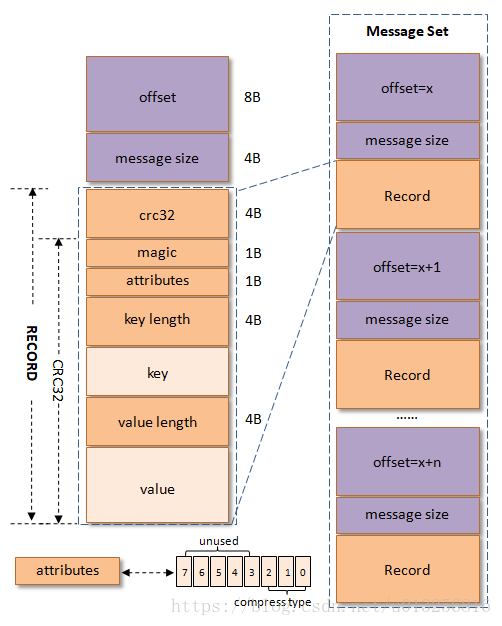
crc32(4B):crc32校验值。校验范围为magic至value之间。
magic(1B):消息格式版本号,此版本的magic值为0。
attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:
key length(4B):表示消息的key的长度。如果为-1,则表示没有设置key,即key=null。
key:可选,如果没有key则无此字段。
value length(4B):实际消息体的长度。如果为-1,则表示消息为空。
value:消息体。可以为空,比如tomnstone消息。
具体实现
1,内存分配
kafka-client 不能无限制使用虚拟机内存,JVM还有其他线程需要内存,kafka-client可以使用的内存上限多少?,消息内存如何分配。
参考kafka-client 内存分配和管理 https://www.cnblogs.com/huxuhong/p/13651696.html
2,消息存储
kafka 支持海量数据发送,如果JVM内存存储这一块如果不够优秀,根本无法支持这么庞大的QPS。
参考 kafka-client 消息存储分析 https://www.cnblogs.com/huxuhong/p/13821491.html
3,消息序列化及发送
kafka 数据存储和发送的更多相关文章
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- 解决KafKa数据存储与顺序一致性保证
“严格的顺序消费”有多么困难 下面就从3个方面来分析一下,对于一个消息中间件来说,”严格的顺序消费”有多么困难,或者说不可能. 发送端 发送端不能异步发送,异步发送在发送失败的情况下,就没办法保证消息 ...
- kafka 数据存储结构+原理+基本操作命令
数据存储结构: Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的.每个topic又可以分成几个不同的partition(每个topic有几个partitio ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
- Kafka session.timeout.ms heartbeat.interval.ms参数的区别以及对数据存储的一些思考
Kafka session.timeout.ms heartbeat.interval.ms参数的区别以及对数据存储的一些思考 在计算机世界中经常需要与数据打交道,这也是我们戏称CURD工程师的原因之 ...
- 小程序的数据存储,与Django等服务发送请求
目录 官方文档 快速归纳 存取改删 1.wx存储数据到本地以及本地获取数 1.1 wx.setStorageSync(string key, any data) 存(同步) 1.2 wx.setSto ...
- kafka数据迁移实践
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:mikealzhou 本文重点介绍kafka的两类常见数据迁移方式:1.broker内部不同数据盘之间的分区数据迁移:2.不同broker ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
随机推荐
- D. Maximum Distributed Tree 解析(思維、DFS、組合、貪心、DP)
Codeforce 1401 D. Maximum Distributed Tree 解析(思維.DFS.組合.貪心.DP) 今天我們來看看CF1401D 題目連結 題目 直接看原題比較清楚,略. 前 ...
- CSS动画之转换模块
2D转换模块:注意点:1.可以类似于过渡模块一样简写,但是这里不是用逗号隔开而是用空格 2.2D的转换模块会修改元素的坐标系,所以旋转之后的平移就不是水平平移 格式:旋转:transform: rot ...
- Redis常用命令(2)——String
APPEND 格式:APPEND key value 作用:在key的键值后追加value,如果key不存在,则创建key,并存入value. 返回值:追加value后的字符串长度. 示例: 192. ...
- openshift 平台上部署 gitlab代码仓库服务
背景: 本文档将以在openshift 平台上部署 gitlab 服务来验证集群各个服务组件的可用性以及熟悉openshift的使用方法.服务部署方式可以多种多样,灵活部署.本篇以常见的镜像部署方式来 ...
- Linux 系统编程 学习:06-基于socket的网络编程1:有关概念
Linux 系统编程 学习:006-基于socket的网络编程1:有关概念 背景 上一讲 进程间通信:System V IPC(2)中,我们介绍了System IPC中关于信号量的概念,以及如何使用. ...
- MIPS汇编及模拟器下载
1. 简述汇编语言发展 在计算机发展初期,人们用0-1序列来表示每一条语言,亦即二进制的机器指令 由于机器指令过于繁琐,程序员们开发出了一种新的语言,这种用符号表示的计算机语言被称为汇编语言 计算机继 ...
- Angular2 初学小记
1.与Angular1的异同 几乎完全不同(什么鬼~ 1)保留一些特性 表达式仍旧用{{}}. 2)属性指令变为驼峰式 ng-if ---> ngIf 3)ng-repeat被ngFor代替 4 ...
- 3、Django之路由层
一 路由的作用 路由即请求地址与视图函数的映射关系,如果把网站比喻为一本书,那路由就好比是这本书的目录,在Django中路由默认配置在urls.py中. 二 简单的路由配置 # urls.py fro ...
- leetcode117:search-rotated-sorted-array
题目描述 给出一个转动过的有序数组,你事先不知道该数组转动了多少 (例如,0 1 2 4 5 6 7可能变为4 5 6 7 0 1 2). 在数组中搜索给出的目标值,如果能在数组中找到,返回它的索引, ...
- Uipath_考证学习之路
写在前面 第一次考证的时候,就是为了考证而考证,从网上获取了试题,修改了一下,就通过了,对 REFramework的了解甚少,经过几周的学习,决定赶在 4.30号考证收费之前再重新考一次. 原文章发表 ...