spark-2-RDD
RDD提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。
两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用(比如Web应用系统、增量式的网页爬虫等)。
RDD典型的执行过程:
- RDD读入外部数据源(或者内存中的集合)进行创建;
- RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
- 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
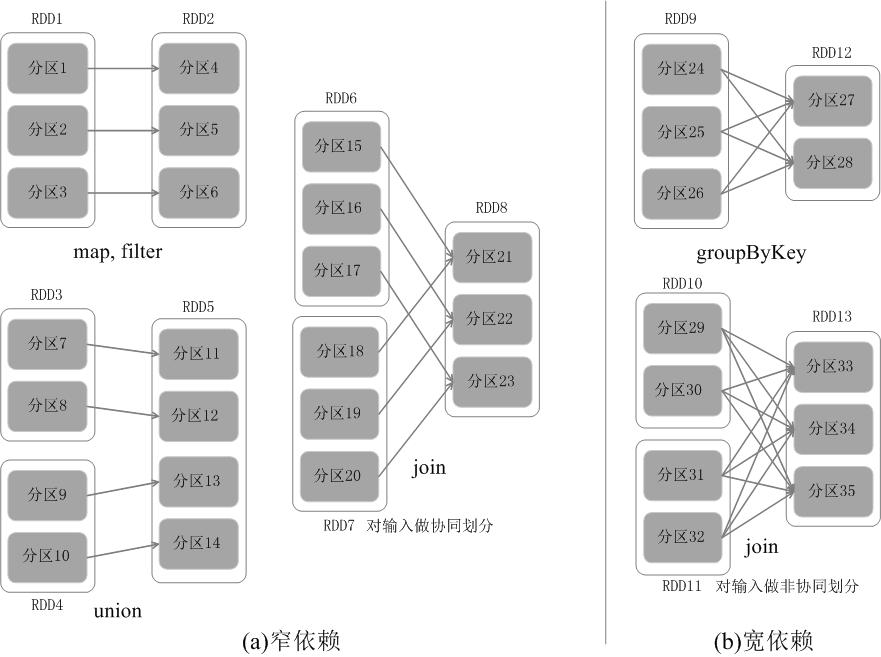
宽窄依赖:
(1)对输入进行协同划分,属于窄依赖。协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖。对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
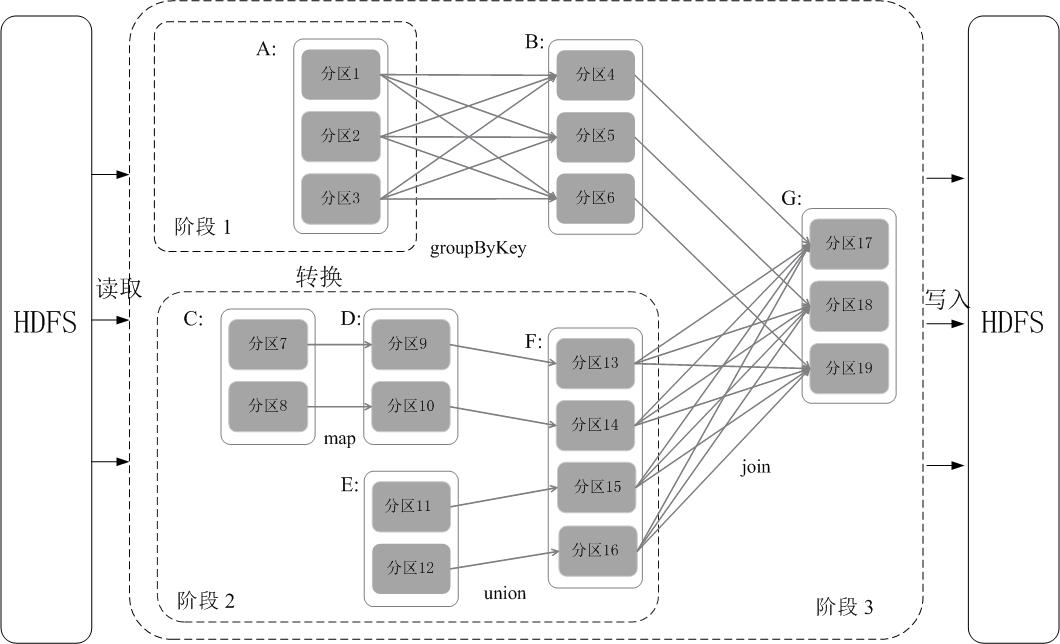
阶段的划分:
在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
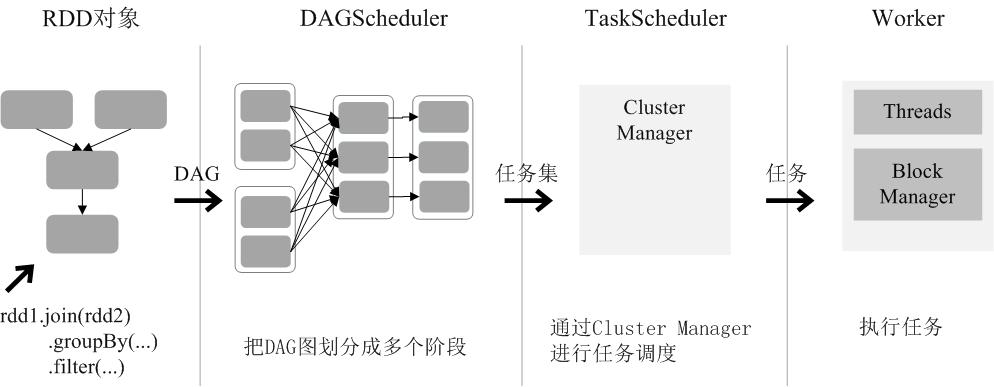
RDD的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
Source【厦门大学林子雨大数据实验室spark入门教程】http://dblab.xmu.edu.cn/blog/1709-2/
spark-2-RDD的更多相关文章
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- Spark核心—RDD初探
本文目的 最近在使用Spark进行数据清理的相关工作,初次使用Spark时,遇到了一些挑(da)战(ken).感觉需要记录点什么,才对得起自己.下面的内容主要是关于Spark核心-RDD的相关 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- [Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子
[Spark][Python][RDD][DataFrame]从 RDD 构造 DataFrame 例子 from pyspark.sql.types import * schema = Struct ...
- spark中RDD的转化操作和行动操作
本文主要是讲解spark里RDD的基础操作.RDD是spark特有的数据模型,谈到RDD就会提到什么弹性分布式数据集,什么有向无环图,本文暂时不去展开这些高深概念,在阅读本文时候,大家可以就把RDD当 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark之 RDD
简介 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的集合. Resilien ...
- 解读Spark Streaming RDD的全生命周期
本节主要内容: 一.DStream与RDD关系的彻底的研究 二.StreamingRDD的生成彻底研究 Spark Streaming RDD思考三个关键的问题: RDD本身是基本对象,根据一定时间定 ...
随机推荐
- Nginx Ingress 高并发实践
概述 Nginx Ingress Controller 基于 Nginx 实现了 Kubernetes Ingress API,Nginx 是公认的高性能网关,但如果不对其进行一些参数调优,就不能充分 ...
- sdf文件可以通过database net4工具升级版本
用database .net4工具打开数据库后,右键数据库->数据库工具->upgrade to->to 4.0 or to 3.5; 可以用来判断数据库版本及是否要升级.
- CTF线下awd攻防文件监控脚本
CTF线下awd攻防赛中常用一个文件监控脚本来保护文件,但是就博主对于该脚本的审计分析 发现如下的问题: 1.记录文件的路径未修改导致log暴露原文件备份文件夹:drops_JWI96TY7ZKNMQ ...
- Java面试题(1):详解int与Integer
Java面试题(1):详解int与Integer int与Integer的区别 int是Java的基本数据类型之一,Integer是int的包装类 int直接再内存中储存值,Integer进行new操 ...
- 打包下载zip代码
/// <summary> /// 下载文件 /// </summary> /// <param name="dt">需要处理的数据集</ ...
- SpringAOP+源码解析,切就完事了
本文是对近期学习知识的一个总结,附带源码注释及流程图,如有不足之处,还望评论区批评指正. 目录 一.AOP.SpringAOP.AspectJ的区别 二.AOP关键术语 三.通知的五种类型 四.切入点 ...
- JS语法_类型
类型 JS 的数据类型 boolean number string undefined null symbol object TS 额外的数据类型 void BigInt 是一种内置对象,它提供了一种 ...
- Android 4.X 系统加载 so 失败的原因分析
1 so 加载过程 so 加载的过程可以参考小米的系统工程师的文章loadLibrary动态库加载过程分析 2 问题分析 2.1 问题 年前项目里新加了一个 so库,但发现native 方法的找不到的 ...
- 记一次线上OOM问题分析与解决
一.问题情况 最近用户反映系统响应越来越慢,而且不是偶发性的慢.根据后台日志,可以看到系统已经有oom现象. 根据jdk自带的jconsole工具,可以监视到系统处于堵塞时期.cup占满,活动线程数持 ...
- Java I/O流 复制文件速度对比
Java I/O流 复制文件速度对比 首先来说明如何使用Java的IO流实现文件的复制: 第一步肯定是要获取文件 这里使用字节流,一会我们会对视频进行复制(视频为非文本文件,故使用之) FileInp ...