机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述
在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响。
同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或者有一些特征带有的信息和其他一些特征是重复的(比如一些特征可能会线性相关)。
我们希望能够找出一种办法来帮助我们衡量特征上所带的信息量,让我们在降维的过程中,能够即减少特征的数量,又保留大部分有效信息——将那些带有重复信息的特征合并,并删除那些带无效信息的特征等等——逐渐创造出能够代表原特征矩阵大部分信息的,特征更少的,新特征矩阵。
上周的特征工程课中,我们提到过一种重要的特征选择方法:方差过滤。如果一个特征的方差很小,则意味着这个特征上很可能有大量取值都相同(比如90%都是1,只有10%是0,甚至100%是1),那这一个特征的取值对样本而言就没有区分度,这种特征就不带有有效信息。从方差的这种应用就可以推断出,如果一个特征的方差很大,则说明这个特征上带有大量的信息。
因此,在降维中,PCA使用的信息量衡量指标,就是样本方差,又称可解释性方差,方差越大,特征所带的信息量越多。

Var代表一个特征的方差,n代表样本量,xi代表一个特征中的每个样本取值,xhat代表这一列样本的均值。

降维究竟是怎样实现
class sklearn.decomposition.PCA (n_components=None, copy=True, whiten=False, svd_solver=’auto’, tol=0.0,
iterated_power=’auto’, random_state=None)
PCA作为矩阵分解算法的核心算法,其实没有太多参数,但不幸的是每个参数的意义和运用都很难,因为几乎每个参数都涉及到高深的数学原理。为了参数的运用和意义变得明朗,我们来看一组简单的二维数据的降维。
我们现在有一组简单的数据,有特征x1和x2,三个样本数据的坐标点分别为(1,1),(2,2),(3,3)。我们可以让x1和x2分别作为两个特征向量,很轻松地用一个二维平面来描述这组数据。这组数据现在每个特征的均值都为2,方差
则等于:
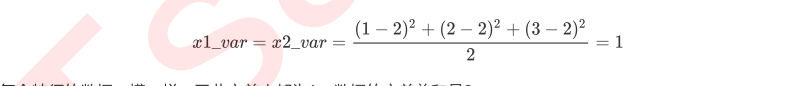
每个特征的数据一模一样,因此方差也都为1,数据的方差总和是2。
现在我们的目标是:只用一个特征向量来描述这组数据,即将二维数据降为一维数据,并且尽可能地保留信息量,即让数据的总方差尽量靠近2。于是,我们将原本的直角坐标系逆时针旋转45°,形成了新的特征向量x1*和x2*组成的新平面,在这个新平面中,三个样本数据的坐标点可以表示为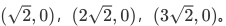
。可以注意到,x2*上的数值此时都变成了0,因此x2*明显不带有任何有效信息了(此时x2*的方差也为0了)。此时,x1*特征上的数据均值是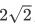
,而方差则可表示成:
x1*上的数据均值为0,方差也为0。
此时,我们根据信息含量的排序,取信息含量最大的一个特征,因为我们想要的是一维数据。所以我们可以将x2*删除,同时也删除图中的x2*特征向量,剩下的x1*就代表了曾经需要两个特征来代表的三个样本点。通过旋转原有特征向量组成的坐标轴来找到新特征向量和新坐标平面,我们将三个样本点的信息压缩到了一条直线上,实现了二维变一维,并且尽量保留原始数据的信息。一个成功的降维,就实现了。
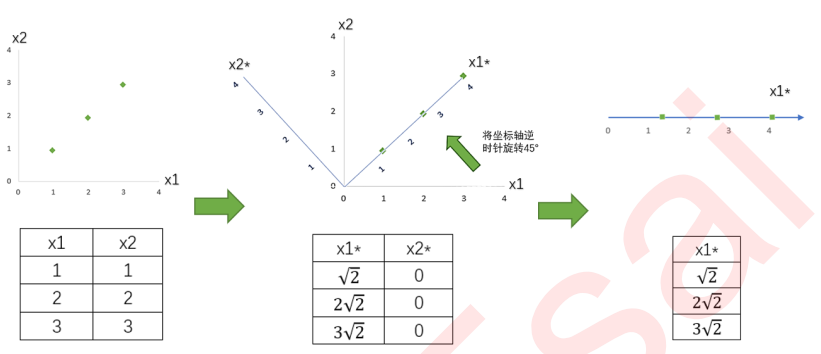
不难注意到,在这个降维过程中,有几个重要的步骤:
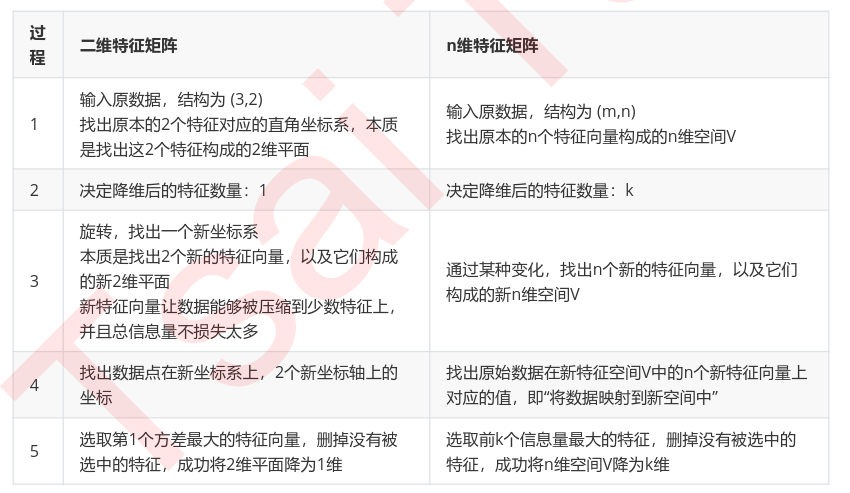
在步骤3当中,我们用来找出n个新特征向量,让数据能够被压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解。
PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。降维时,它会通过一系列数学的神秘操作(比如说,产生协方差矩阵 )将特征矩阵X分解为以下三个矩阵,其
中 和 是辅助的矩阵,Σ是一个对角矩阵(即除了对角线上有值,其他位置都是0的矩阵),其对角线上的元素就是方差。
降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音。
而SVD使用奇异值分解来找出空间V,其中Σ也是一个对角矩阵,不过它对角线上的元素是奇异值,这也是SVD中用来衡量特征上的信息量的指标。U和V^{T}分别是左奇异矩阵和右奇异矩阵,也都是辅助矩阵。
在数学原理中,无论是PCA和SVD都需要遍历所有的特征和样本来计算信息量指标。
并且在矩阵分解的过程之中,会产生比原来的特征矩阵更大的矩阵,比如原数据的结构是(m,n),在矩阵分解中为了找出最佳新特征空间V,可能需要产生(n,n),(m,m)大小的矩阵,还需要产生协方差矩阵去计算更多的信息。
而现在无论是Python还是R,或者其他的任何语言,在大型矩阵运算上都不是特别擅长,无论代码如何简化,我们不可避免地要等待计算机去完成这个非常庞大的数学计算过程。
因此,降维算法的计算量很大,运行比较缓慢,但无论如何,它们的功能无可替代,它们依然是机器学习领域的宠儿。

机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现的更多相关文章
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 机器学习实战基础(二十):sklearn中的降维算法PCA和SVD(一) 之 概述
概述 1 从什么叫“维度”说开来 我们不断提到一些语言,比如说:随机森林是通过随机抽取特征来建树,以避免高维计算:再比如说,sklearn中导入特征矩阵,必须是至少二维:上周我们讲解特征工程,还特地提 ...
- sklearn中的多项式回归算法
sklearn中的多项式回归算法 1.多项式回归法多项式回归的思路和线性回归的思路以及优化算法是一致的,它是在线性回归的基础上在原来的数据集维度特征上增加一些另外的多项式特征,使得原始数据集的维度增加 ...
- 【c语言】二维数组中的查找,杨氏矩阵在一个二维数组中,每行都依照从左到右的递增的顺序排序,输入这种一个数组和一个数,推断数组中是否包括这个数
// 二维数组中的查找,杨氏矩阵在一个二维数组中.每行都依照从左到右的递增的顺序排序. // 每列都依照从上到下递增的顺序排序.请完毕一个函数,输入这种一个数组和一个数.推断数组中是否包括这个数 #i ...
- 机器学习实战基础(二十三):sklearn中的降维算法PCA和SVD(四) PCA与SVD 之 PCA中的SVD
PCA中的SVD 1 PCA中的SVD哪里来? 细心的小伙伴可能注意到了,svd_solver是奇异值分解器的意思,为什么PCA算法下面会有有关奇异值分解的参数?不是两种算法么?我们之前曾经提到过,P ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(二十二):sklearn中的降维算法PCA和SVD(三) PCA与SVD 之 重要参数n_components
重要参数n_components n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值,一般输入[0, min(X.shape)]范围中的整数. ...
- 机器学习实战基础(二十七):sklearn中的降维算法PCA和SVD(八)PCA对手写数字数据集的降维
PCA对手写数字数据集的降维 1. 导入需要的模块和库 from sklearn.decomposition import PCA from sklearn.ensemble import Rando ...
- 机器学习实战基础(二十四):sklearn中的降维算法PCA和SVD(五) PCA与SVD 之 重要接口inverse_transform
重要接口inverse_transform 在上周的特征工程课中,我们学到了神奇的接口inverse_transform,可以将我们归一化,标准化,甚至做过哑变量的特征矩阵还原回原始数据中的特征矩阵 ...
随机推荐
- Docker巨轮的航行之路-基础知识篇
一.什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中 ...
- Spring源码系列(一)--详解介绍bean组件
简介 spring-bean 组件是 IoC 的核心,我们可以通过BeanFactory来获取所需的对象,对象的实例化.属性装配和初始化都可以交给 spring 来管理. 针对 spring-bean ...
- cheerio html方法中文被编码问题
var $ = cheerio.load("<h1><p>你好</p><em>Hello,World!</em></h1&g ...
- Python基础002---基础知识
一.标识符 标识符是自己定义的,是开发人员在程序中自己定义的一些符号和名称,如变量名.函数名等.在 Python 里,标识符由字母(区分大小写).数字.下划线组成,且数字不能开头.常用的命名方法有小驼 ...
- Arduino连接LCD1602显示屏
简介 LCD1602是一种工业字符型液晶,能够同时显示16x02即32个字符.LCD1602液晶显示的原理是利用液晶的物理特性,通过电压对其显示区域进行控制,即可以显示出图形.[百度百科] 引脚说明 ...
- Beta冲刺<4/10>
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺--第四天(05.22) 作业正文 如下 其他参考文献 ... B ...
- Docker图形界面管理
之前都是使用命令行进行Docker的管理,这里简单介绍一下Docker的图形界面管理.之所以说简单介绍,是因为在生产环境都是集群,很少使用图形界面管理单台Docker主机,所以就演示记录一下,在个人测 ...
- NodeJs将异步方法改为同步以上传文件为例
[本文版权归微信公众号"代码艺术"(ID:onblog)所有,若是转载请务必保留本段原创声明,违者必究.若是文章有不足之处,欢迎关注微信公众号私信与我进行交流!] 下面这个例子既写 ...
- JavaWeb网上图书商城完整项目--day02-8.提交注册表单功能之dao、service实现
1.发送邮件 发送邮件的时候的参数我们都写在了配置文件中,配置文件放在src目录下,可以使用类加载器进行加载该数据 //向注册的用户发送邮件 //1读取配置文件 Properties properti ...
- 一个工作了四年的java程序员的心得体会
年底了,该给自己写点总结了!从毕业到现在已经快4年啦,一直在Java的WEB开发行业混迹.我不是牛人,但是自我感觉还算是个合格的程序员,有必要写下自己将近4年来的经历,给自我以提示,给刚入行的朋友提供 ...