中间件面试专题:kafka高频面试问题

![]()
开篇介绍
大家好,近期会整理一些Java高频面试题分享给小伙伴,也希望看到的小伙伴在找工作过程中能够用得到!本章节主要针对Java一些消息中间件高频面试题进行分享。
Q1:
什么是消息和批次?
消息,Kafka里的数据单元,也就是我们一般消息中间件里的消息的概念。消息由字节数组组成。消息还可以包含键,用以对消息选取分区。
为了提高效率,消息被分批写入Kafka。
批次,就是一组消息,这些消息属于同一个主题和分区。如果只传递单个消息,会导致大量的网络开销,把消息分成批次传输可以减少这开销。但是,这个需要权衡,批次里包含的消息越多,单位时间内处理的消息就越多,单个消息的传输时间就越长。如果进行压缩,可以提升数据的传输和存储能力,但需要更多的计算处理。
Q2:
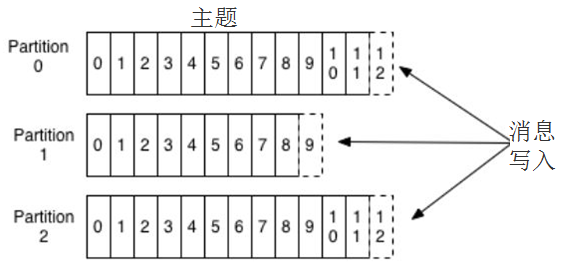
什么是主题和分区?
Kafka的消息用主题进行分类,主题下可以被分为若干个分区。分区本质上是个提交日志,有新消息,这个消息就会以追加的方式写入分区,然后用先入先出的顺序读取。
![]()
但是因为主题会有多个分区,所以在整个主题的范围内,是无法保证消息的顺序的,单个分区则可以保证。
Kafka通过分区来实现数据冗余和伸缩性,因为分区可以分布在不同的服务器上,那就是说一个主题可以跨越多个服务器。
前面我们说Kafka可以看成一个流平台,很多时候,我们会把一个主题的数据看成一个流,不管有多少个分区。
Q3:
Kafka中的ISR、AR代表什么?ISR的伸缩指的什么?
ISR :In-Sync Replicas 副本同步队列
AR :Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(包括 延迟时间replica.lag.time.max.ms 和 延迟条数replica.lag.max.message 两个维度,当前最新的版本0.10.x中只支持 replica.lag.time.max.ms 这个维度),任意一个超过阈值都会把follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。
注:AR = ISR + OSR
Q4:
Broker 和 集群
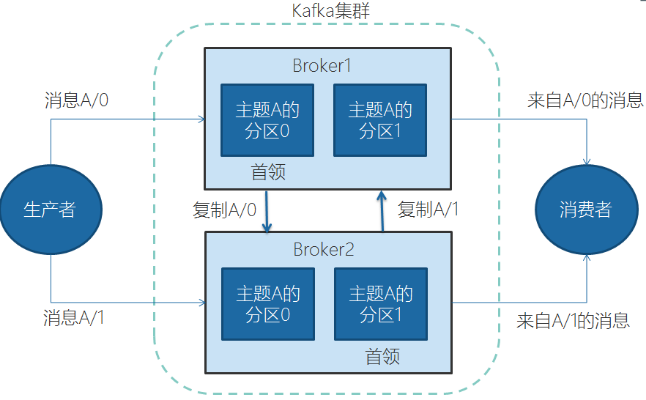
一个独立的Kafka服务器叫Broker。broker的主要工作是,接收生产者的消息,设置偏移量,提交消息到磁盘保存;为消费者提供服务,响应请求,返回消息。在合适的硬件上,单个broker可以处理上千个分区和每秒百万级的消息量。
多个broker可以组成一个集群。每个集群中broker会选举出一个集群控制器。控制器会进行管理,包括将分区分配给broker和监控broker。
集群里,一个分区从属于一个broker,这个broker被称为首领。但是分区可以被分配给多个broker,这个时候会发生分区复制。
![]()
分区复制带来的好处是,提供了消息冗余。一旦首领broker失效,其他broker可以接管领导权。当然相关的消费者和生产者都要重新连接到新的首领上。
Q5:
kafka中的zookeeper起到什么作用?
zookeeper是一个分布式的协调组件,早期版本的kafaka用zk做 meta信息存储 , consumer的消费状态 , group的管理 以及 offset 的值。
考虑到zk本身的一些因素以及整个架构较大概率存在单点问题,新版本中逐渐弱化了zookeeper的作用。新的consumer使用了kafka内部的 group coordination 协议,也减少了对zookeeper的依赖。
Q6:
kafka follower如何与leader数据同步?
kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。
完全同步复制要求 All Alive Follower 都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。
一步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下,如果leader挂掉,会丢失数据;
kafka使用 ISR 的方式很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,而且Leader充分利用磁盘顺序读以及 send file(zero copy) 机制,这样极大的提高复制性能,内部批量写磁盘,大幅减少了Follower与Leader的消息量差。
Q7:
kafka中的消息是否会丢失和重复消费?
消息发送:
kafka消息发送有两种方式:同步(sync)和异步(async);
默认是同步方式,可通过 producer.type 属性进行配置;
kafka通过配置 request.required.acks 属性来确认消息的生产。
0:表示不进行消息接收是否成功的确认;
1:表示当Leader接收成功时确认;
-1:表示Leader和Follower都接收成功时确认;
综上所述,有6种消息产生的情况,消息丢失的场景有:
acks=0,不和kafka集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
消息消费:
kafka消息消费有两个consumer接口, Low-level API 和 High-level API :
Low-level API:消费者自己维护offset等值,可以实现对kafka的完全控制;
High-level API:封装了对parition 和 offset 的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来,并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就"诡异"的消失了;
解决方案:
1 针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入Leader 和 Follower之后再确认消息发送成功;异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态。
2 针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
Q8:
kafka为什么不支持读写分离?
在kafka中,生产者写入消息、消费者读取消息的操作都是与Leader副本进行交互的,从而实现的是一种主写主读的生产消费模型。
kafka并不支持主写从读,因为主写从读有2个很明显的缺点:
数据一致性问题:数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间窗口会导致主从节点之间的数据不一致。某一时刻,在主节点和从节点中A数据的值都为X,之后将主节点中A的值修改为Y,那么在这个变更通知到从节点之前,应用读取从节点中的A数据的值并不为最新的Y值,由此便产生了数据不一致的问题。
延时问题:类似Redis这种组件,数据从写入主节点到同步至从节点的过程中需要经历 网络→主节点内存→网络→从节点内存 这几个阶段,整个过程会耗费一定的时间。而在kafka中,主从同步会比Redis更加耗时,它需要经历 网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘 这几个阶段。对延时敏感的应用而言,主写从读的功能场景并不太适用。
点关注、不迷路
如果觉得文章不错,欢迎关注、点赞、收藏,你们的支持是我创作的动力,感谢大家。
如果文章写的有问题,请不要吝啬,欢迎留言指出,我会及时核查修改。
如果你还想更加深入的了解我,可以私信我。每天8:00准时推送技术文章,让你的上班路不在孤独,而且每月还有送书活动,助你提升硬实力!
中间件面试专题:kafka高频面试问题的更多相关文章
- 字节跳动上传了一份“面试官版Android面试小册”,不讲一句废话,全是精华
前言 金三银四马上就到了,很多粉丝朋友私信希望我出一篇面试专题或者分享面试相关的笔记来学习,这不今天就给大家安排上了?(都是干货,错过就是亏.) 下面的面试笔记都是精心整理好免费分享给大家的,希望新朋 ...
- 手撕面试官系列(八):分布式通讯ActiveMQ+RabbitMQ+Kafka面试专题
ActiveMQ专题 (面试题+答案领取方式见主页) 什么是 ActiveMQ? ActiveMQ 服务器宕机怎么办? 丢消息怎么办? 持久化消息非常慢. 消息的不均匀消费. 死信队列. Active ...
- php面试专题---MySQL分表
php面试专题---MySQL分表 一.总结 一句话总结: 分库分表要数据达到一定的量级才用,这样才有效率,不然利不一定大于弊,可能会增加一次I/O消耗 1.分库分表的使用量级是多少? 单表行数超过 ...
- php面试专题---MySQL分区
php面试专题---MySQL分区 一.总结 一句话总结: mysql的分区操作还比较简单,好处是也不用自己动手建表进行分区,和水平分表有点像 1.mysql分区简介? 一个表或索引-->N个物 ...
- 2019前端面试系列——JS高频手写代码题
实现 new 方法 /* * 1.创建一个空对象 * 2.链接到原型 * 3.绑定this值 * 4.返回新对象 */ // 第一种实现 function createNew() { let obj ...
- 手撕面试官系列(六):并发+Netty+JVM+Linux面试专题
并发面试专题 (面试题+答案领取方式见侧边栏) 现在有 T1.T2.T3 三个线程,你怎样保证 T2 在 T1 执行完后执行,T3 在 T2 执行完后执行? 在 Java 中 Lock 接口比 syn ...
- php面试专题---22、网站优化 总结
php面试专题---22.网站优化 总结 一.总结 一句话总结: 主要从前端.后端.数据库.资源四个方面开始发散 前端浏览器缓存和数据压缩前端优化(减少HTTP请求次数) 资源流量优化(防盗链处理)C ...
- php面试专题---21、MVC框架基本工作原理考察点
php面试专题---21.MVC框架基本工作原理考察点 一.总结 一句话总结: 会的东西快速过,不要浪费时间,生命有限,都是一些很简单的东西. 1.mvc框架单一入口的 优势 是什么? 可以进行统一的 ...
- php面试专题---20、MySQL的安全性考点
php面试专题---20.MySQL的安全性考点 一.总结 一句话总结: 还是得多看视频,教程看的浮光掠影,容易get不到重点:比如预处理防sql注入之前是挺熟,后面就忘记了,而且看文章get不到点 ...
随机推荐
- ip_rcv 中使用skb_share_check
/* * Main IP Receive routine. */ int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct pack ...
- shell编程之俄罗斯方块
按键获取: 向上 ^[[A 向下 ^[[B 向左 ^[[D 向右 ^[[C 其中 ^[为ESC键. 按键获取的具体shell代码如下所示: #! /bin/bash GetKey() { a ...
- hibernate 基础知识
1.hibernate的配置文件,一般放在classpath的根目录下,默认命名为hibernate.cfg.xml,代码例子如下: <!DOCTYPE hibernate-configurat ...
- Qiskit 安装指南
内容参考官方文档 https://qiskit.org/documentation/install.html conda create -n name_of_my_env python=3 创建虚拟环 ...
- java面试必问:多线程的实现和同步机制,一文帮你搞定多线程编程
前言 进程:一个计算机程序的运行实例,包含了需要执行的指令:有自己的独立地址空间,包含程序内容和数据:不同进程的地址空间是互相隔离的:进程拥有各种资源和状态信息,包括打开的文件.子进程和信号处理. 线 ...
- Guitar Pro 7教程之如何导入吉他谱
在前面的章节小编为大家也讲解了不少关于Guitar Pro 的相关教程,譬如{cms_selflink page='index' text='Guitar Pro下载'},安装等等一系列的使用教程,前 ...
- FL Studio钢琴卷轴之画笔工具
在FL Studio中,钢琴卷轴窗口是制作音乐很重要的一个窗口,大部分音乐编辑的工作都要在该窗口中完成.钢琴卷轴的概念来源于旧时自动机械钢琴所使用的纸质卷轴,在钢琴卷轴中,纵轴代表音符的高度,横轴代表 ...
- 实战教程:如何将自己的Python包发布到PyPI上
1. PyPi的用途 Python中我们经常会用到第三方的包,默认情况下,用到的第三方工具包基本都是从Pypi.org里面下载. 我们举个栗子: 如果你希望用Python实现一个金融量化分析工具,目前 ...
- celery原理与组件
1.Celery介绍 https://www.cnblogs.com/xiaonq/p/11166235.html#i1 1.1 celery应用举例 Celery 是一个 基于python开发的 分 ...
- 01-01.单一职责原则(Single Responsibility)
1.基本介绍 对于类来说的,就是一个类,应该只负责一项职责(一个类只管一件事). 如类A负责两个不同职责:职责1,职责2. 当职责1需求变更而改变A时,可能造成职责2执行错误,所以需要将类A的粒度分解 ...