CRACKING THE CODING INTERVIEW 笔记(1)
1. Arrays and Strings
1.1 Hash Tables
哈希表,简单的说就是由一个数组和一个hash函数组成实现key/value映射并且能高效的查找的数据结构。最简单的想法就是将hash(key)做为数组的下标(index)来存取。
但是为了防止hash的冲突(collisions),数组的大小必须设置得足够大,因此上面这种简单的实现在实际中是不可取的。
实际上,哈希表是一个固定大小的数组,数组的每个元素是一个链表(单向或双向)的头指针。每个元素被存放在hash(key)%array_length所在的链表中。如下图所示:
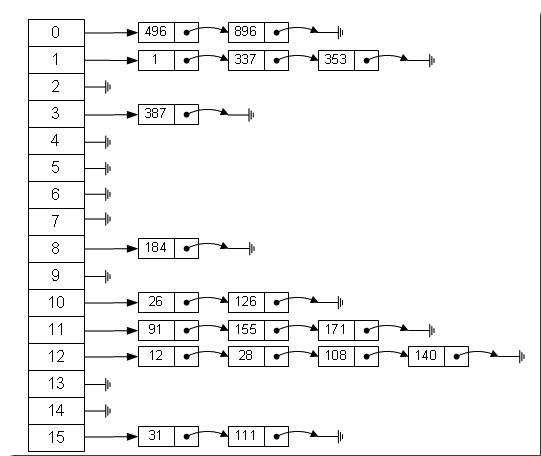
另外,我们可以用二叉查找树(bst)来实现哈希表,在平衡树的基础上能保证0(logn)的查询时间, 而且相对节省空间。
1.2 ArrayList
ArrayList是一个可动态扩张的数组,一个典型的实现就是当ArrayList满了的时候,它会将大小扩大一倍,这个扩张的动作的时间复杂度在O(n),但是发生得很少,所以均摊下来ArrayList的读取复杂度还是O(1)。
1.3 StringBuffer
当考虑进行大量的字符串连接操作的时候,如果使用String中的+操作符来进行,将导致非常糟糕的性能,因为String为不可变对象,一旦被创建,就不能修改它的值。所以下面这条语句
str1 = str1 + str2;
等同于生成了一个新的str1对象,然后将指针指向新的 str1对象,所以经常改变内容的字符串最好不要用String对象 ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后,JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
而如果是使用StringBuffer类则结果就不一样了,每次结果都会对StringBuffer对象本身进行操作,而不是生成新的对象,再改变对象引用。StringBuffer上的主要操作是 append 和 insert 方法。append 方法始终将这些字符添加到缓冲区的末端;而 insert 方法则在指定的点添加字符。
所以在一般情况下我们推荐使用StringBuffer,特别是字符串对象经常改变的情况下。而在某些特别情况下, String 对象的字符串拼接其实是被 JVM 解释成了StringBuffer对象的拼接,所以这些时候 String 对象的速度并不会比StringBuffer对象慢,而特别是以下的字符串对象生成中, String 效率是远要比StringBuffer快的:
String s1 = "This is only a" + "simple" + "test";
StringBuffer sb = new StringBuilder("This is only a").append(" simple").append("test");
你会很惊讶的发现,生成 String S1 对象的速度简直太快了,而这个时候StringBuffer居然速度上根本一点都不占优势。其实这是 JVM 的一个把戏,在 JVM 眼里,这个
String s1 = "This is only a" + "simple" + "test";
其实就是:
String s1 = "This is only a simple test";
所以当然不需要太多的时间了。但要注意的是,如果字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
String S2 = "This is only a";
String S3 = "simple";
String S4 = "test";
String S1 = S2 +S3 + S4;
这时候 JVM 会规规矩矩的按照原来的方式去做。
另外,StringBuilder是5.0新增的一个可变的字符序列。此类提供一个与StringBuffer兼容的 API,但不保证同步。该类被设计用作StringBuffer的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比StringBuffer要快。两者的方法基本相同。区别就在于StringBuffer是线程安全的而
StringBuilder非线程安全。
关于StringBuffer和StringBuilder的实现:
StringBuffer是一个用于存放动态存放字符串数据的类,他继承自java.lang.AbstractStringBuilder这个类。
所谓动态存放是指:你无需考虑StringBuffer大小的问题。
当你利用StringBuffer的append方法向其自身添加字符串的时候,如果此时StringBuffer默认提供的空间大小不够用,
那么它会自动扩展自身的存储空间,以保证数据能够正常的放入到StringBuffer其中。
我们也可以手动的设置StringBuffer的空间大小
例如:
StringBuffer buf = new StringBuffer(10);
上面的意思是指:将StringBuffer的内部容量设置为10个字符(char)大小的长度。
StringBuffer默认的存储空间大小是16个字符,也就是说 new StringBuffer() 就等于 new StringBuffer(16)。
StringBuffer的底层是利用它的父类(AbstractStringBuilder)内部的一个默认长度为16的字符数组来存放数据的。(即:char value[];)
每当利用 StringBuffer的append方法向其中添加一个字符串的时候StringBuffer都会调用其父类(AbstractStringBuilder)的append方法,
然后AbstractStringBuilder会判断其内部用于存放数据的那个char[]数组是否已经满了,
(1)如果没有满,就会将你传入的字符串转化为
字符并存入到那个字符数组中(即: str.getChars(0, len, value, count);)。
(2)而如果那个char[]数组已经满了,那么AbstractStringBuilder会创建一个大小为当前数组两倍的新的char[]数组。
然后利用System.arraycopy(value, 0, newValue, 0, count);将原始数据拷贝到这个新的数组中即可。
CRACKING THE CODING INTERVIEW 笔记(1)的更多相关文章
- 《Cracking the Coding Interview》读书笔记
<Cracking the Coding Interview>是适合硅谷技术面试的一本面试指南,因为题目分类清晰,风格比较靠谱,所以广受推崇. 以下是我的读书笔记,基本都是每章的课后习题解 ...
- Cracking the coding interview
写在开头 最近忙于论文的开题等工作,还有阿里的实习笔试,被虐的还行,说还行是因为自己的水平或者说是自己准备的还没有达到他们所需要人才的水平,所以就想找一本面试的书<Cracking the co ...
- Cracking the coding interview 第一章问题及解答
Cracking the coding interview 第一章问题及解答 不管是不是要挪地方,面试题具有很好的联系代码总用,参加新工作的半年里,做的大多是探索性的工作,反而代码写得少了,不高兴,最 ...
- Cracking the Coding Interview(Trees and Graphs)
Cracking the Coding Interview(Trees and Graphs) 树和图的训练平时相对很少,还是要加强训练一些树和图的基础算法.自己对树节点的设计应该不是很合理,多多少少 ...
- Cracking the Coding Interview(Stacks and Queues)
Cracking the Coding Interview(Stacks and Queues) 1.Describe how you could use a single array to impl ...
- Cracking the coding interview目录及资料收集
前言 <Cracking the coding interview>是一本被许多人极力推荐的程序员面试书籍, 详情可见:http://www.careercup.com/book. 第六版 ...
- Cracking the Coding Interview 题目分析笔记—— Array and String
1.Determine if a string has all unique characters learn: 为了减少空间利用率,其比较优秀的算法一般都适用位操作 返回值的命名方法,我们需要学习 ...
- 二刷Cracking the Coding Interview(CC150第五版)
第18章---高度难题 1,-------另类加法.实现加法. 另类加法 参与人数:327时间限制:3秒空间限制:32768K 算法知识视频讲解 题目描述 请编写一个函数,将两个数字相加.不得使用+或 ...
- 《Cracking the Coding Interview》——第13章:C和C++——题目6
2014-04-25 20:07 题目:为什么基类的析构函数必须声明为虚函数? 解法:不是必须,而是应该,这是种规范.对于基类中执行的一些动态资源分配,如果基类的析构函数不是虚函数,那么 派生类的析构 ...
随机推荐
- 【转】C++读写二进制文件
原文网址:http://blog.csdn.net/lightlater/article/details/6364931 摘要: 使用C++读写二进制文件,在开发中操作的比较频繁,今天有幸找到一篇文章 ...
- HDU_2012——判断表达式是否都为素数
Problem Description 对于表达式n^2+n+41,当n在(x,y)范围内取整数值时(包括x,y)(-39<=x<y<=50),判定该表达式的值是否都为素数. I ...
- linux 建库,编码,导入数据
二.导入数据库1.首先建空数据库mysql>create database abc; 2.导入数据库方法一:(1)选择数据库mysql>use abc;(2)设置数据库编码mysql> ...
- [Polymer] Custom Elements: Styling
Code: <dom-module id="business-card"> <template> <div class="card" ...
- sql列转行
1.需要实现一个单行的统计报表 思路先用一个union查出单列,然后再把单列转成单行 2.实现 SELECT MAX(CASE WHEN type = 1 THEN num ELSE 0 END) A ...
- hdu4893Wow! Such Sequence! (线段树)
Problem Description Recently, Doge got a funny birthday present from his new friend, Protein Tiger f ...
- WPF控件---Border应用
内容模型:Border 只能具有一个子元素.若要显示多个子元素, 需要将一个容器元素放置在父元素Border中. <Grid> <Border BorderBrush="B ...
- 国外.net学习资源网站
转载 :出处:http://www.cnblogs.com/kingjiong/ 名称:快速入门地址 http://chs.gotdotnet.com/quickstart/ 描述:本站点是微软.NE ...
- Jquery JSOPN在WebApi中的问题
1. 客户端代码: $.ajax({ data: { name: 'zhangsan' }, url: apiUrl.getTwo('TestFourth'), dataType: 'jsonp', ...
- sqlserver获取当前id的前一条数据和后一条数据
一.条件字段为数值的情况 select * from tb where id=@id; --当前记录 select top 1 * from tb where id>@id order ...