ASP.NET + SqlSever 大数据解决方案 PK HADOOP
半个月前看到博客园有人说.NET不行那篇文章,我只想说你们有时间去抱怨不如多写些实在的东西。
1、SQLSERVER优点和缺点?
优点:支持索引、事务、安全性以及容错性高
缺点:数据量达到100万以上就需要开始优化了,一般我们会对 表进行水平拆分,分表、分区和作业同步等,这样做大大提高了逻辑的复杂性,难以维护,只有群集容错,没有多库负载均衡并行计算功能。
2、SQLSERVER真的不能处理大数据?
答案:当然可以的,打个比方:操作单一数据库称为一维操作,如果操作相同结构,分布在多个服务器上的多个数据库这个可以称为二维操作。 我们只需要对这个二维操作进行一层封装,让他支持并行运算,把服务器压力分散开,我们不需要写太多东西,SQL已经为我们封装了很多,它就好比是一个巨人,而我们只需要站在他的肩膀上,就可以轻松实现针对WEB的大数据处理。
3、hadoop适不适合.NET,他有哪些缺点?
(1)、数据同步慢
(2)、事务处理难
(3)、异常捕获难
(4)、很难与ASP.NET结合,无论是学习学成本,还是自身的支持方面
(5)、 需要安装,适合离线大数据处理,但未必适合WEB
4、什么是SqlSugar框架?
SqlSugar是一款基于SqlSever的轻量级高性能ORM框架,除了具有和ADO.NET匹敌的性能外,现在已经支持多库并行计算。

优点:
(1)、适合海量数据的无延迟查询
(2)、支持分布式事务
(3)、让JOIN飞起来,告别大数据NOJOIN
(4)、C#.NET自家语法和大量封装函数
(5)、随机存储,也就是说可以存储在任意一个节点数据库,做到真正正的负载均衡,而不是以往主从模式的读写分离。
缺点: SqlServer授权费太贵,适合有钱的公司或者不交授权费的创业小企业
SqlSugar学习目录
2、使用SqlSugar处理大数据
3、使用SqlSugar实现Join 待更新
4、使用SqlSugar实现分页+分组+多列排序 待更新
5、节点故障如何进行主从调换
》》》》2、使用SqlSugar处理大数据《《《
1、SqlSugar的原理
Insert: 随机存储到某个节点数据库(每个节点可以配置处理的机率,如果设置为0表示该节点不会有新数据添加进来)
Update、Delete:异步请求所有数据库节点同步汇总处理结果
Search: 对分页前X页、后X页和PageCount<1000(1000这个值可以在程序中设置)的数据进行了特殊优化,其它数据进行了异步节点算法同步对结果进行汇,性能在多服务器架构中可以完美的体现出来,在单服务器架构需要注意保证足够IO,避免全表扫描,否则起不到优化效果。
1、单服务器、单硬盘、多库架构:
适合低并发,数据量在1亿以下,响应速度有较高要求,建议数据量最好不要超过1000W,在查询中避免全表扫描,充分利用io性能,让异步的优势体现出来。
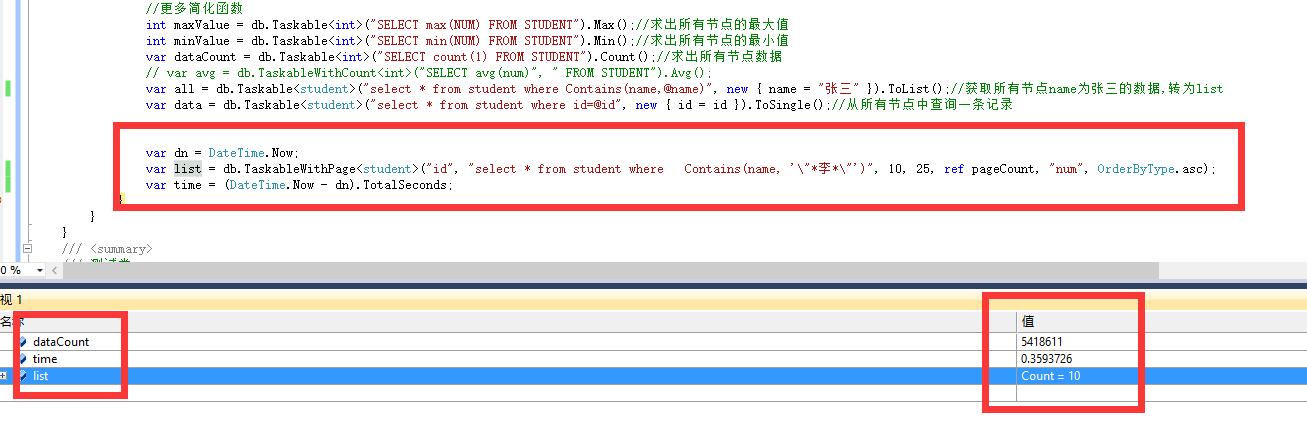
如图:
对部署在同一台PC机上的10个同结构库进行了模糊搜索
name建了全文索引,id和num建立了复合索引
十个库加起来总共有540万条数据 ,普通机械硬盘 只用了0.3秒的时间。
2、单服务器、多硬盘或阵列:
可以使用LIKE等进行全表扫描,性能有明显的提升
3、多服务器、多库架构
就按单台PC机10个库540万0.3秒的来算,如果有10台PC机那就可以处理5000万,时间预算在0.3秒-0.5秒之间。
这10台PC换成10台服务器又能处理多少呢?
总结:节点越多、服务器越多处理能力就越强。

Landa
2、用法
1、引用SqlSugar.dll
2、配置连接字符串
其中rate是Insert时存储到某节点的机率,0表示不会有新数据添加到该节点,下面设置都为1表示我一点都不偏心

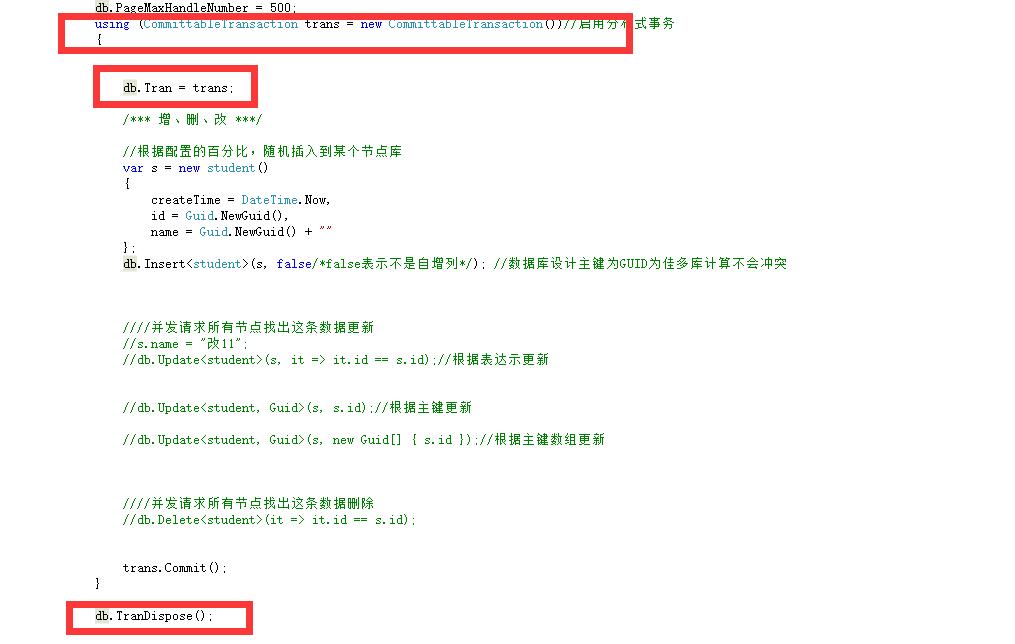
3、添、删、改用法

4、启用分布式事务
服务器需要开启MSDTC等服务
5、Taskable是所有分布式计算的底层核心
分页、分组等复杂的查询都从这里展开,支持DataTable、T:Class、值类型 三种类型,能够方便的把多库的结果同步汇总到一个容器中。
使用Taskable需要注意每个节点获取的数据量都不能很大,通过少取,内存运算,在取在运算的方式处理复杂数据的查询。

6、使用Taskable进行分组查询
统计类报表类的查询,查询结果集不会太大,完全可使用Taskable进行处理,Merge方法能够将所有库查询的结果集合并到一个新的集合

7、使用Taskable扩展函数,让你处理多库运算更加方便。

8、分布式分页
考虑了分库机制,主键建议使用GUID来保证独一,只有主键唯一才可以使用该分页函数

分页是通过 节点数 每页显示条数 当前页码 等算出一个初步的索引,然后取出这个索引位置所在的数据,在算出这个数据的真实索引 与 page begin比较在算出一个新的索引直到找到精准位置在把数据读出来。原理是这样子的。
至于原理我就不多讲了,一个贴子也说不完,有幸趣的朋友可以加群: 225982985 讨论
源码地址:https://github.com/sunkaixuan/SqlSugar
哈哈 我已经尽力了, 不管好坏为了给个赞哈
ASP.NET + SqlSever 大数据解决方案 PK HADOOP的更多相关文章
- 浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
作者 王枫发布于2014年2月19日 综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个 ...
- 转:浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个时代决胜未来的关键因素,而基于大数据的 ...
- 转:甲骨文发布大数据解决方案 含最新版NoSQL数据库
原文出处: http://www.searchdatabase.com.cn/showcontent_88247.htm 以下是部分节选: 最新发布的大数据创新成果包括: Oracle Big Dat ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- dkh人力资源大数据解决方案整体架构
大数据技术的应用正在潜移默化改变着我们的日常生活习惯和工作方式,很多看起来有点“不可思议”的事情也渐渐被我们“习以为常”.大数据可能在国内的起步较晚,但我们可能却是对大数据应用最好的了代表了.前些时候 ...
随机推荐
- Python 标准异常
异常名称 描述 BaseException 所有异常的基类 SystemExit 解释器请求退出 KeyboardInterrupt 用户中断执行(通常是输入^C) Exception 常规错误的 ...
- Javascript进度条
一个简单的进度条演示. <!doctype html> <html> <head> <meta charset="utf8"> &l ...
- Linux nm命令
一.简介 显示关于对象文件.可执行文件以及对象文件库里的符号信息. 二.选项 http://www.cnblogs.com/wangkangluo1/archive/2012/07/02/257243 ...
- css3中变形与动画(一)
css3制作动画的几个属性:变形(transform),过渡(transition)和动画(animation). 首先介绍transform变形. transform英文意思:改变,变形. css3 ...
- SpringMVC从入门到精通之第二章
这一章原本我是想写一个入门程序的,但是后来仔细想了一下,先从下面的图中的组件用代码来介绍,可能更效果会更加好一点.第一节:开发准备介绍之前先说下我的开发调试环境:JDK 1.7的64位 .Eclips ...
- java设计模式之命令模式
学校中.生活中.社会中总是会存在一定的阶层,虽然我们很多人都不可认可阶层的存在.命令这一词也就在阶层中诞生.家长命令孩子,老师命令学生,领导命令小娄娄.这些都在我们的生活存在的东西,相信这一个模式学习 ...
- 【2016-10-12】【坚持学习】【Day3】【责任链模式】
今天学习责任链模式 例子: 采购审批系统 采购单需要经过不同人审批 采购价格<500 部门经理审批 采购价格<1000 部门主任审批 采购价格<2000 副总审批 采购价格<5 ...
- POJ 2826 An Easy Problem?! --计算几何,叉积
题意: 在墙上钉两块木板,问能装多少水.即两条线段所夹的中间开口向上的面积(到短板的水平线截止) 解法: 如图: 先看是否相交,不相交肯定不行,然后就要求出P与A,B / C,D中谁形成的向量是指向上 ...
- reflect2015破解
具体看 http://download.congci.com/download/net-reflector-7-6-1-824-wanquan-pojie#downloads *博主注:因为很多破解程 ...
- SQL2012连接字符串
安装了sqlserver2012数据库,测试一包代码,搜索网上的方法,死活连接不上,最后偶然测试通过,居然是连接字符串的问题. “如果开发软件的时候是在局域网或者是在本机,并且数据库不在远程计算机上面 ...