在VMWare中建立Hadoop虚拟集群的详细步骤(使用CentOS)
最近在学习Hadoop,于是想使用VMWare建立一个虚拟的集群环境。网上有很多参考资料,但参照其步骤进行设置时却还是遇到了不少问题,所以在这里详细写一下我的配置过程,以及其中遇到的问题及相应的解决方法。一来做个记录,二来也希望能帮到大家。
目标
我们要建立一个具有如下配置的集群:
| host name | ip address | os | |
| 1 | master | 192.168.224.100 | CentOS |
| 2 | slave1 | 192.168.224.201 | CentOS |
| 3 | slave2 | 192.168.224.202 | CentOS |
其中master为name node和job tracker节点,slaveN为data node和task tracker节点。
步骤
1. 配置虚拟网络
如果你对VMWare和网络配置比较熟悉,可以忽略这一步,但是后面配置IP地址时具体的参数可能和我说的不一样。如果你想通过一步一步操作就能成功的话,就需要这些设置
通过VMWare -> Edit -> Virtual Network Editor打开如下对话框:
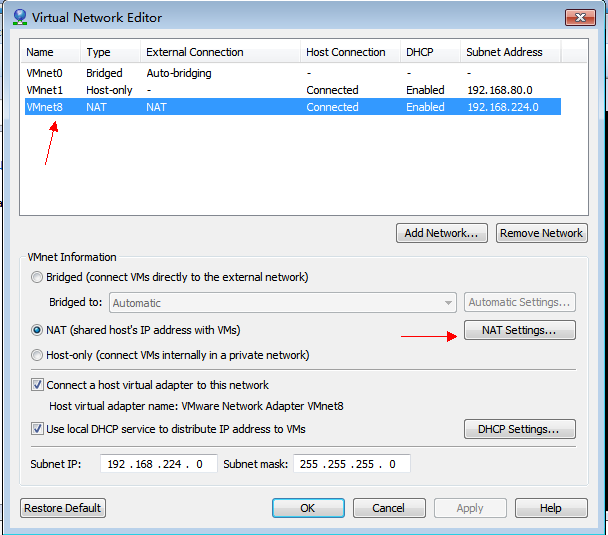
在上面的列表中选中VMnet8 NAT那一行,然后按图设置所有内容,之后点击NAT Setting按钮,打开如下对话框,确保各个参数如图中所示设置。

2. 创建虚拟机
虚拟机命名为master,创建过程中网络模式可以任意选择,下面假设选择的是NAT方式。需要额外注意的是去【控制面板/管理工具/服务】中看一下VMWare相关的服务是否都已经启用,我就曾因为NAT服务没有启用,而造成各个虚拟机之间无法ping通,而浪费了很多时间。

到http://www.centos.org/中下去CentOS的iso镜像,使用minimal版本就可以,这样能效的控制虚拟机的大小。
然后就是虚拟机安装的过程了,我们不需要安装VMWare Tools。而且这时不需要创建多台虚拟机,我们将统一配置一台虚拟机,然后复制出其它虚拟机,后面的详细的说明。
后面的步骤中我们假设使用root登录虚拟机,密码假设为hadoop。
2. 配置网络
关掉SELINUX:vi /etc/selinux/config ,设置SELINUX=disabled,保存退出。
关闭防火墙:/sbin/service iptables stop;chkconfig --level 35 iptables off
修改IP地址为静态地址:vi /etc/sysconfig/network-scripts/ifcfg-eth0,将其内容改为如下图所示,注意HWADDR那一行,你所创建的虚拟机的值很可能与之不同,保持原值,不要修改它!

修改主机名称: vi /etc/sysconfig/network,将其内容改为如下图所示:

修改hosts映射:vi /etc/hosts,将其内容改为如下图所示。我们在这里就加入了slave1和slave2的映射项,以简化后面的步骤。

执行:service network restart 以重启网络。
3. 安装putty
我使用这个工具将windows中的文件传到虚拟机中,因为使用wget下载相应的软件包比较困难。
从http://www.putty.org/下载putty套件,解压到你喜欢的目录就可以了,确保里面有pscp.exe。
4. 安装JDK
从下面的地址下载JDK,文件名是jdk-6u26-linux-i586.bin,如果这个地址已经失效,你可以在oracle的网站上下载最新的版本。
http://download.oracle.com/otn/java/jdk/6u26-b03/jdk-6u26-linux-i586.bin
我是在windows下用迅雷下载的,假设下载后文件放在 e:\jdk-6u26-linux-i586.bin 这个位置,在虚拟机开机的状态下从windows中打开命令提示符,运行如下命令(其中的pscp就是putty中的pscp.exe,所以你可能需要到相应的目录中去执行,或者将其所在的目录添加到PATH中):
pscp e:\jdk-6u26-linux-i586.bin root@192.168.224.100:~/
如果提示输入密码,就输入虚拟机中root帐户的密码(假设为hadoop)。
然后进入虚拟机,执行如下命令:
mkdir -p ~/bin
mv ~/jdk-6u26-linux-i586.bin ~/bin
cd ~/bin
./jdk-6u26-linux-i586.bin
然后修改环境变量:vi ~/.bash_profile,在最后添加
export JAVA_HOME=/root/bin/jdk1.6.0_26
export PATH=$PATH:$JAVA_HOME/bin
保存退出后,执行 source ~/.bash_profile 使配置生效,之后可以执行java命令以判断是否已经配置成功。
5. 安装Hadoop
从http://labs.renren.com/apache-mirror/hadoop/common/hadoop-0.20.2/中下载hadoop-0.20.2.tar.gz,放到~/bin目录下(如果你是在windows下下载的,就通过上面的方法将其复制到虚拟机中)。执行下列命令:
tar -xzvf hadoop-0.20.2.tar.gz
cd ~/bin/hadoop-0.20.2/conf
vi hadoop-env.sh
将JAVA_HOME一行的注释去掉,并改为如下设置:
export JAVA_HOME=/root/bin/jdk1.6.0_26
然后添加环境变量 vi ~/.bash_profile ,使其内容如下所示(已经合并了前面关于JAVA的设置)
export JAVA_HOME=/root/bin/jdk1.6.0_26
export HADOOP_HOME=/root/bin/hadoop-0.20.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
现在就可以在shell中运行hadoop,以确定能正常执行了。下面还要对hadoop进行设置,所有要设置的文件都在~/bin/hadoop-0.20.2/conf目录下。如果你足够懒的话,可以在windows下创建这几个文件,把相应的内容复制到文件中,然后通过pscp.exe复制到虚拟机中去。
core-site.xml的内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/tmp/hadoop-root</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>
slaves
slave1
slave2
masters的内容为空,此文件用于配置secondary name node,我这次建立的集群不需要此节点,如果需要的话可以将其主机名加入此文件中(别忘了在/etc/hosts中加入相应的条目)。
6. 复制虚拟机
使用VMWare中clone功能,复制出另外两台虚拟机,分别命名为slave1和slave2。因为克隆出的虚拟机网卡地址已经改变,所以要分别在复制出的两台虚拟机中执行以下操作:
- 执行:rm -f /etc/udev/rules.d/70-persistent-net.rules
- 执行:reboot 重启虚拟机
- 执行:vim /etc/sysconfig/networking/devices/ifcfg-eth0 将其中的 HWADDR修改为新虚拟机的网卡地址,具体查看方式为:在虚拟机设置中选中Network Adapter,如下图所示,选择Advanced,如下图红框中所示即为网卡地址。

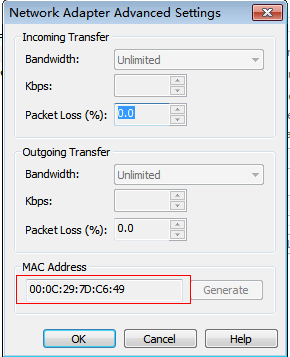
- 同样在此文件中将IPADDR改为192.168.224.201(对于slave1)或192.168.224.202(对于slave2)。
- 修改slave1和slave2的/etc/sysconfig/network文件,将主机名改为slave1或者slave2。
7. 设置SSH
打开三台虚拟机,登录到master中,执行如下命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh slave1 "mkdir ~/.ssh"
scp ~/.ssh/id_dsa.pub slave1:~/.ssh/authorized_keys
ssh slave2 "mkdir ~/.ssh"
scp ~/.ssh/id_dsa.pub slave2:~/.ssh/authorized_keys
中间可能需要输入密码 ,按提示输入即可。现在分别执行如下命令
ssh localhost
ssh slave1
ssh slave2
不需要再输入密码就对了。
8. 启动Hadoop
执行HDFS格式化命令:hadoop namenode -format
在master虚拟机中进入/root/hadoop-0.20.2/bin目录,执行 ./start-all.sh 就OK了。
你可以在宿主机中打开浏览器,指向 192.168.224.100:50070 查看HDFS的信息。
如果你是一步一步操作下来的,应该不会遇到什么问题,如果有问题,欢迎一起来讨论。
在VMWare中建立Hadoop虚拟集群的详细步骤(使用CentOS)的更多相关文章
- Apache版本的Hadoop HA集群启动详细步骤【包括Zookeeper、HDFS HA、YARN HA、HBase HA】(图文详解)
不多说,直接上干货! 1.先每台机器的zookeeper启动(bigdata-pro01.kfk.com.bigdata-pro02.kfk.com.bigdata-pro03.kfk.com) 2. ...
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
- redis3.0.0 集群安装详细步骤
Redis集群部署文档(centos6系统) Redis集群部署文档(centos6系统) (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对 ...
- 最新版solr7.2集群搭建详细步骤
集群:高可用,备份,数据可分片 需要运行4个tomcat 1.tomcat端口号(默认占用8005,8009,8080三个端口) tomcat服务 占用端口 tomcat1 6005.6060.600 ...
- rabbitmq普通集群搭建详细步骤
由于工作需求,需要安装rabbitmq,学习之余,记录一下安装过程 准备基础编译环境yum install gcc glibc-devel make ncurses-devel openssl-dev ...
- KafKa集群安装详细步骤
最近在使用Spring Cloud进行分布式微服务搭建,顺便对集成KafKa的方案做了一些总结,今天详细介绍一下KafKa集群安装过程: 1. 在根目录创建kafka文件夹(service1.serv ...
- Redis集群安装详细步骤
环境: Centos7 redis3.0 三台虚拟机主机名分别为 master node1 node2 如果单机的时候设置过密码最好把密码去掉,避免位置的错误. 拍个快照方便恢复. 1.创 ...
- Hadoop 跨集群访问
[原文地址] 跨集群访问 发表于 2015-06-01 | 简单总结下跨集群访问的多种方式. 跨集群访问HDFS 直接给出HDFS URI 我们平常执行hadoop fs -ls /之类的操作 ...
- (二 )VMware workstation 部署虚拟集群实践——并行批量操作环境部署
在上一篇博客中,已经介绍了安装虚拟集群的过程和需要注意的细节问题. 这篇主要是介绍如何批量登陆远程主机和配置,这个过程中是在没有部署并行处理工具或者集群管理工具的前进行的. ------------首 ...
随机推荐
- 忘记XP密码的解决方案
仅供教学与研究用,后果自负! !! USE AT YOUR OWN RISK !! !! ONLY FOR EDUCATIONAL PURPOSE !! 介绍 获取SYSTEM权限.测试通过. 进入G ...
- Tween Animation----Alpha渐变透明度动画
本博文是我自己操作过的并且能运行才给大家分享的 layout ----activity_main.xml 在res/新建一个anim文件夹,用来保存动画属性的xml 在anim文件夹里新建一个alph ...
- Python网络数据采集系列-------概述
这是一个正在准备中的系列文章,主要参考的是<Web Scraping with Python_Collecting Data from the Modern Web-O'Reilly(2015) ...
- Asp.net mvc页面传值-- dropdownlist
后台传值 List<ConfigParamInfo> paramList = configParamBLL.GetModelList(" and parentID=1" ...
- update maven之后jre被改成1.5的问题
在 pom.xml 中添加如下代码: <build> <plugins> <plugin> <groupId>org.apache.maven.plug ...
- Spring 使用 SLF4J代替 Commons Logging 写日志 异常
项目的日志更换成slf4j和logback后,发现项目无法启动.错误提示 Caused by: java.lang.NoClassDefFoundError: Lorg/apache/commons/ ...
- python中的函数
Python 函数 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段. 函数能提高应用的模块性,和代码的重复利用率.你已经知道Python提供了许多内建函数,比如print().但你也 ...
- POJ 1979 题解
Red and Black Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 31722 Accepted: 17298 D ...
- 无法连接虚拟设别 ide1:0.
安装虚拟机时出现提示:无法连接虚拟设备 ide1:0,因为主机上没有相应的设备.您要在每次开启此虚拟机时都尝试连接此虚拟设备吗? ide1:0一般是虚拟机的光驱,配置选项是“使用物理驱动器”,而宿主机 ...
- WINFORM 输出txt文件
SaveFileDialog saveFile1 = new SaveFileDialog(); saveFile1.Filter = "文本文件(.txt)|*.txt"; sa ...