jmeter 实时搜索结果
因为JMeter 2.13你可以得到实时搜索结果发送到后端通过 后端侦听器 使用潜在的任何后端(JDBC、JMS网络服务,Š) 通过提供一个实现类 AbstractBackendListenerClient 。
JMeter附带GraphiteBackendListenerClient它允许您发送指标石墨后端。
这个特性提供了:
- 生活的结果
- 漂亮的图表为指标
- 比较2个或更多的负载测试的能力
- 监控数据存储在同一后端只要JMeter结果
- 一个Š
在本文档中,我们将配置设置图和historize 2中的数据不同的后端:
- InfluxDB
- 石墨
指标暴露
线程/虚拟用户指标
线程指标如下:
- < rootMetricsPrefix > test.minAT
- 分钟活动线程
- < rootMetricsPrefix > test.maxAT
- 马克斯活动线程
- < rootMetricsPrefix > test.meanAT
- 活动线程的意思
- < rootMetricsPrefix > test.startedT
- 启动线程
- < rootMetricsPrefix > test.endedT
- 完成线程
响应时间指标
响应相关指标如下:
- < rootMetricsPrefix > < samplerName > .ok.count
- 许多成功的响应采样器的名字
- < rootMetricsPrefix > < samplerName > .h.count
- 服务器每秒钟,这个指标堆积样本结果和子结果(如果使用事务控制器,应该无节制的“生成父取样器”)
- < rootMetricsPrefix > < samplerName > .ok.min
- 最小响应时间成功响应采样器的名字
- < rootMetricsPrefix > < samplerName > .ok.max
- 最大响应时间成功响应采样器的名字
- < rootMetricsPrefix > < samplerName > .ok.pct < percentileValue >
- 百分比计算成功响应采样器的名字。 将有一个为每个计算值指标。
- < rootMetricsPrefix > < samplerName > .ko.count
- 失败的反应数量取样器的名字
- < rootMetricsPrefix > < samplerName > .ko.min
- 最小响应时间没有响应的采样器的名字
- < rootMetricsPrefix > < samplerName > .ko.max
- 最大响应时间没有响应的采样器的名字
- < rootMetricsPrefix > < samplerName > .ko.pct < percentileValue >
- 百分比计算失败的响应的采样器的名字。 将有一个为每个计算值指标。
- < rootMetricsPrefix > < samplerName > .a.count
- 取样器的反应数量名称(好吧。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.min
- 最小响应时间响应采样器的名字(最低的好。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.max
- 最大响应时间取样器名称(Max的反应好。 计数和ko.count)
- < rootMetricsPrefix > < samplerName > .a.pct < percentileValue >
- 百分比计算响应的采样器的名字。 将有一个为每个计算值指标。 (好和失败样本计算总数)
默认的 百分位数 设置在 后端侦听器 是“90;95;95”, 即3百分位数90%、95%和99%。
的 石墨命名层次结构 使用点(“。”)单独的元素。 这可能与十进制百分位值混淆。 JMeter转换任何这样的价值观,用下划线代替点(“。”)(“-”)。 例如,“ 99.9 “变成了” 99年_9 ”
默认JMeter发送采样指标累计samplerName” 所有 ”。 如果后端侦听器 samplersList 配置,然后JMeter也发送指标吗 除非匹配样本的名字 summaryOnly = true
JMeter配置
JMeter指标发送给后端添加一个 BackendListener 使用GraphiteBackendListenerClient。
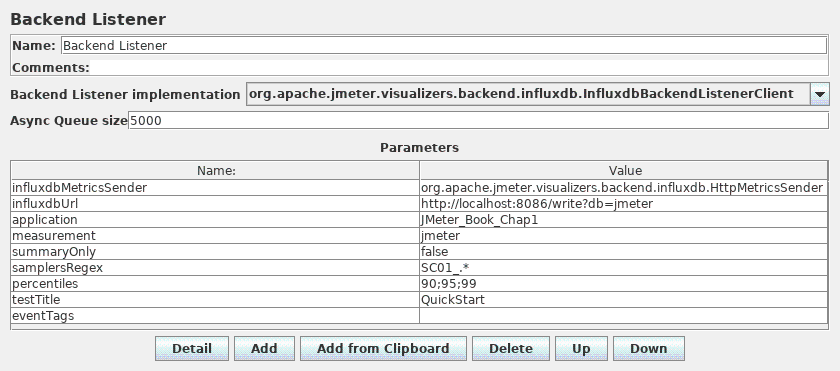 石墨的配置
石墨的配置
InfluxDB
InfluxDB是一个开源的、分布式的、允许时间序列数据库 很容易存储度量。 安装和配置很简单,读了更多的细节 InfluxDB文档 。
InfluxDB数据可以很容易地在浏览器中查看 Influga 或 Grafana 。 在这种情况下,我们将使用Grafana。
InfluxDB石墨侦听器配置
使石墨InfluxDB侦听器,编辑文件 / opt / influxdb /共享/ config.toml 或 /usr/local/etc/influxdb.conf , 找到“ input_plugins.graphite ”并设置:
# Configure the graphite api
[input_plugins.graphite]
enabled = true
address = "0.0.0.0" # If not set, is actually set to bind-address.
port = 2003
database = "jmeter" # store graphite data in this database
# udp_enabled = true # enable udp interface on the same port as the tcp interface
为以后的版本InfluxDb(例如0.12),替换 (input_plugins.graphite) 与 [[石墨]]
InfluxDB数据库配置
连接到InfluxDB管理控制台并创建两个数据库:
- grafana:grafana用来存储我们将创建的仪表板
- jmeter:InfluxDB用来存储数据发送到石墨侦听器为每个数据库=“jmeter”配置 元素 influxdb.conf 或config.toml
Grafana配置
安装grafana只是把问题背后的解压包一个Apache HTTP服务器。
读 文档 为更多的细节。 开放 config.js 文件并找到 数据源 这样的元素,和编辑:
datasources: {
influxdb: {
type: 'influxdb',
url: "http://localhost:8086/db/jmeter",
username: 'root',
password: 'root',
},
grafana: {
type: 'influxdb',
url: "http://localhost:8086/db/grafana",
username: 'root',
password: 'root',
grafanaDB: true
},
},
这里的仪表板,您可以获得: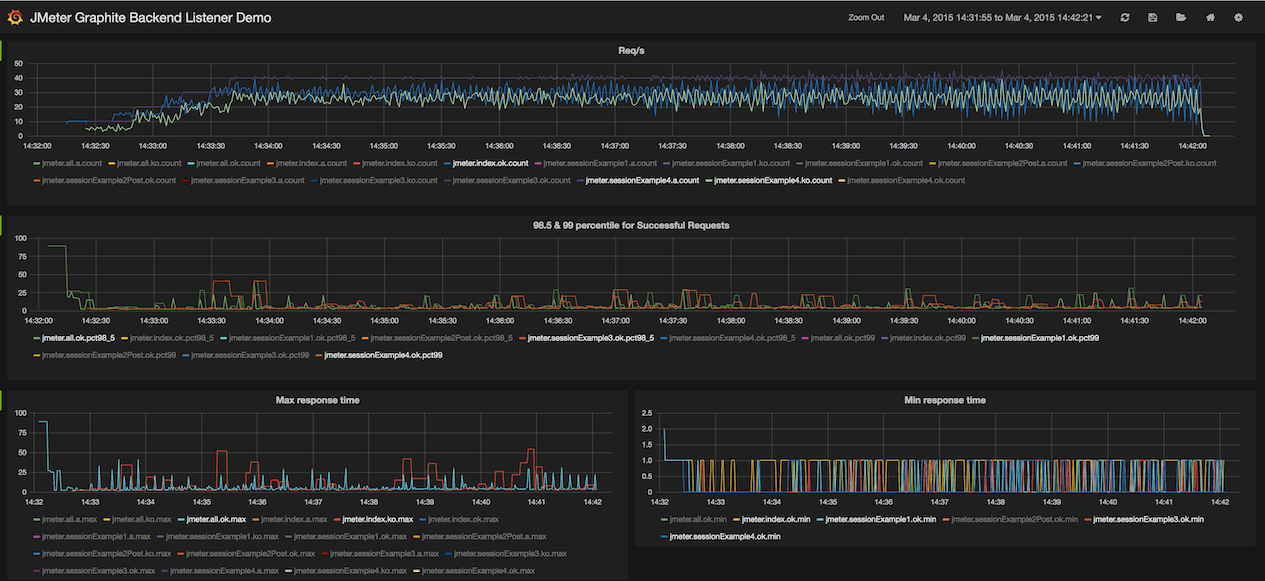 Grafana仪表板
Grafana仪表板
jmeter 实时搜索结果的更多相关文章
- Lucene.net 实现近实时搜索(NRT)和增量索引
Lucene做站内搜索的时候经常会遇到实时搜索的应用场景,比如用户搜索的功能.实现实时搜索,最普通的做法是,添加新的document之后,调用 IndexWriter 的 Commit 方法把内存中的 ...
- Lucene系列-近实时搜索(1)
近实时搜索(near-real-time)可以搜索IndexWriter还未commit的内容,介于immediate和eventual之间,在数据比较大.更新较频繁的情况下使用.本文主要来介绍下如何 ...
- Solr -- 实时搜索
在solr中,实时搜索有3种方案 ①soft commit,这其实是近实时搜索,不能完全实时. ②RealTimeGet,这是实时,但只支持根据文档ID的查询. ③和第一种类似,只是触发softcom ...
- Everything文件名实时搜索||解决局域网文件共享问题
内容概要:Everything中文版下载地址及使用.用Everything轻松解决局域网文件共享问题.Everything语言设置问题 另:Everything只支持NTFS格式的磁盘(工作原理的缘故 ...
- 【jmeter】基于InfluxDB&Grafana的JMeter实时性能测试数据的监控和展示
本文主要讲述如何利用JMeter监听器Backend Listener,配合使用InfluxDB+Grafana展示实时性能测试数据 关于JMeter实时测试数据 JMeter从2.11版本开始,命令 ...
- Elasticsearch是一个分布式可扩展的实时搜索和分析引擎,elasticsearch安装配置及中文分词
http://fuxiaopang.gitbooks.io/learnelasticsearch/content/ (中文) 在Elasticsearch中,文档术语一种类型(type),各种各样的 ...
- lucene4.5近实时搜索
近实时搜索就是他能打开一个IndexWriter快速搜索索引变更的内容,而不必关闭writer,或者向writer提交,这个功能是在2.9版本以后引入的,在以前没有这个功能时,必须调用writer的c ...
- 关于lucene的IndexSearcher单实例,对于索引的实时搜索
Lucene版本:3.0 一般情况下,lucene的IndexSearcher都要写成单实例,因为每次创建IndexSearcher对象的时候,它都需要把索引文件加载进来,如果访问量比较大,而索引也比 ...
- 【Lucene】近实时搜索
近实时搜索:可以使用一个打开的IndexWriter快速搜索索引的变更内容,而不必首先关闭writer,或者向该writer提交:这是2.9版本之后推出的新功能. 代码示例(本例参考<Lucen ...
随机推荐
- 高通平台点亮LCD个人总结
点击打开链接 高通平台LCD模块大致分为两部分:KERNEL和LK.在进行点屏之前,应该认真查看LCD原理图,弄清楚LCD亮屏需要满足的条件和上电时序,同时可以跟LCD IC原厂拿到初始化代码. 首先 ...
- UE4编程之C++创建一个FPS工程(一)创建模式&角色&处理输入
转自:http://blog.csdn.net/u011707076/article/details/44180951 从今天开始,我们一起来学习一下,如何使用C++将一个不带有任何初学者内容的空模板 ...
- Cheatsheet: 2015 03.01 ~ 03.31
Web The Architecture of Algolia's Distributed Search Network No promises: asynchronous JavaScript wi ...
- [HDU5727]Necklace(二分图最大匹配,枚举)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5727 题意:有N个阴珠子和N个阳珠子,特定序号的阴阳珠子放在一起会让阳珠子暗淡.现在问排放成一个环,如 ...
- data-*属性——使用自定义属性的方式存储数据
HTML5提供了data-*属性能存储页面或应用程序的私有自定义数据.只需在属性前加上data-前缀即可,值可以是任意字符串. 存储的(自定义)数据能够被页面的 JavaScript 中利用,以创建更 ...
- Scrum Meeting---One(2015-10-20)
一.scrum meeting 在上周六我们团队进行了一次会议,讨论了我们团队的项目以及项目分工.首先是确立我们的项目,在团队的激烈讨论下我们决定做一个校园相关的APP.然后对于这个项目我们大致进行了 ...
- SAP供应商和客户的创建
进来遇到一个创建供应商的需求,由于在系统中关于供应商和客户的创建比较特殊,且没有相关函数进行创建, 找到一个类和方法来创建,类名:VMD_EI_API 方法名:MAINTAIN_DIRECT_INP ...
- HDU5730 FFT+CDQ分治
题意:dp[n] = ∑ ( dp[n-i]*a[i] )+a[n], ( 1 <= i < n) cdq分治. 计算出dp[l ~ mid]后,dp[l ~ mid]与a[1 ~ r-l ...
- html,CSS文字大小单位px、em、pt的关系换算
html,CSS文字大小单位px.em.pt的关系换算 这里引用的是Jorux的“95%的中国网站需要重写CSS”的文章,题目有点吓人,但是确实是现在国内网页制作方面的一些缺陷.我一直也搞不清楚px与 ...
- C#中“==”和equals()的区别
如以下代码: 1 2 3 4 5 6 7 8 9 int age = 25; short newAge = 25; Console.WriteLine(age == newAge); //t ...