scrapy数据存储在mysql数据库的两种方式
方法一:同步操作
1.pipelines.py文件(处理数据的python文件)
import pymysql class LvyouPipeline(object):
def __init__(self):
# connection database
self.connect = pymysql.connect(host='XXX', user='root', passwd='XXX', db='scrapy_test') # 后面三个依次是数据库连接名、数据库密码、数据库名称
# get cursor
self.cursor = self.connect.cursor()
print("连接数据库成功") def process_item(self, item, spider):
# sql语句
insert_sql = """
insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s)
"""
# 执行插入数据到数据库操作
self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'],
item['Price']))
# 提交,不进行提交无法保存到数据库
self.connect.commit() def close_spider(self, spider):
# 关闭游标和连接
self.cursor.close()
self.connect.close()
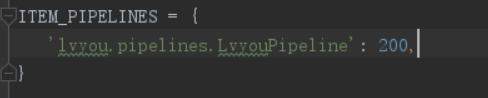
2.配置文件中
方式二 异步储存
pipelines.py文件:
通过twisted实现数据库异步插入,twisted模块提供了 twisted.enterprise.adbapi
1. 导入adbapi
2. 生成数据库连接池
3. 执行数据数据库插入操作
4. 打印错误信息,并排错
import pymysql
from twisted.enterprise import adbapi
# 异步更新操作
class LvyouPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool @classmethod
def from_settings(cls, settings): # 函数名固定,会被scrapy调用,直接可用settings的值
"""
数据库建立连接
:param settings: 配置参数
:return: 实例化参数
"""
adbparams = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
password=settings['MYSQL_PASSWORD'],
cursorclass=pymysql.cursors.DictCursor # 指定cursor类型
) # 连接数据池ConnectionPool,使用pymysql或者Mysqldb连接
dbpool = adbapi.ConnectionPool('pymysql', **adbparams)
# 返回实例化参数
return cls(dbpool) def process_item(self, item, spider):
"""
使用twisted将MySQL插入变成异步执行。通过连接池执行具体的sql操作,返回一个对象
"""
query = self.dbpool.runInteraction(self.do_insert, item) # 指定操作方法和操作数据
# 添加异常处理
query.addCallback(self.handle_error) # 处理异常 def do_insert(self, cursor, item):
# 对数据库进行插入操作,并不需要commit,twisted会自动commit
insert_sql = """
insert into lvyou(name1, address, grade, score, price) VALUES (%s,%s,%s,%s,%s)
"""
self.cursor.execute(insert_sql, (item['Name'], item['Address'], item['Grade'], item['Score'],
item['Price'])) def handle_error(self, failure):
if failure:
# 打印错误信息
print(failure)
注意:
1、python 3.x 不再支持MySQLdb,它在py3的替代品是: import pymysql。
2、报错pymysql.err.ProgrammingError: (1064, ……
原因:当item['quotes']里面含有引号时,可能会报上述错误
解决办法:使用pymysql.escape_string()方法
例如:
sql = """INSERT INTO video_info(video_id, title) VALUES("%s","%s")""" % (video_info["id"],pymysql.escape_string(video_info["title"]))
3、存在中文的时候,连接需要添加charset='utf8',否则中文显示乱码。
4、每执行一次爬虫,就会将数据追加到数据库中,如果多次的测试爬虫,就会导致相同的数据不断累积,怎么实现增量爬取?
scrapy-deltafetch
scrapy-crawl-once(与1不同的是存储的数据库不同)
scrapy-redis
scrapy-redis-bloomfilter(3的增强版,存储更多的url,查询更快)
原文:https://blog.csdn.net/weixin_40096730/article/details/87863797
scrapy数据存储在mysql数据库的两种方式的更多相关文章
- 猫眼电影爬取(一):requests+正则,并将数据存储到mysql数据库
前面讲了如何通过pymysql操作数据库,这次写一个爬虫来提取信息,并将数据存储到mysql数据库 1.爬取目标 爬取猫眼电影TOP100榜单 要提取的信息包括:电影排名.电影名称.上映时间.分数 2 ...
- C++连接mysql数据库的两种方法
本文主要介绍了C++连接mysql数据库的两种方法,希望通过本文,能对你有所帮助,一起来看. 现在正做一个接口,通过不同的连接字符串操作不同的数据库.要用到mysql数据库,以前没用过这个数据库,用a ...
- Android开发之使用sqlite3工具操作数据库的两种方式
使用 sqlite3 工具操作数据库的两种方式 请尊重他人的劳动成果,转载请注明出处:Android开发之使用sqlite3工具操作数据库的两种方式 http://blog.csdn.net/feng ...
- .Net 中读写Oracle数据库常用两种方式
.net中连接Oracle 的两种方式:OracleClient,OleDb转载 2015年04月24日 00:00:24 10820.Net 中读写Oracle数据库常用两种方式:OracleCli ...
- C语言中存储多个字符串的两种方式
C语言中存储多个字符串的两种方式 方式一 二维字符串数组 声明: char name[][] = { "Justinian", "Momo", " ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- springmvc和servlet在上传和下载文件(保持文件夹和存储数据库Blob两种方式)
参与该项目的文件上传和下载.一旦struts2下完成,今天springmvc再来一遍.发现springmvc特别好包,基本上不具备的几行代码即可完成,下面的代码贴: FileUpAndDown.jsp ...
- Django框架操作数据库的两种方式
Django操作数据库的前提操作是成功连接数据库,详情见上篇:https://www.cnblogs.com/kristin/p/10791358.html Django查询数据库的方式一 from ...
- jsp中使用动态数据进行mySQL数据库的两种操作方法
使用动态数据进行数据库内容的增删改查操作有两种方法: 在此定义数据库连接为conn 假设有表单进行数据输入并提交到处理页面一种是使用预编译格式: 其格式如下: String name = reques ...
随机推荐
- Android -- 《 最美有物》好看的点赞效果
1,前天在鸿洋的公众号上看到一款不错的点赞效果,是仿最美有物的点赞,再加上自己最近学习状态很差,自己想着通过这个效果练手一下,果然,花了整整两天的时间,按照以前的效率的话一天就够了,哎,已经调整了一个 ...
- Catch That Cow (BFS广搜)
问题描述: Farmer John has been informed of the location of a fugitive cow and wants to catch her immedia ...
- CentOS7编译安装SVN(subversion1.9.7)
参考连接0:http://www.programering.com/a/MDMzYDMwATg.html参考连接1:http://www.zsythink.net/archives/13180.系统信 ...
- racle SQL性能优化
(1) 选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving table)将被最先 ...
- Hadoop 进程配置总结
HDFS: NameNode: core-site.xml <property> <name>fs.defaultFS</name> <value>hd ...
- Spring Cloud 和 Dubbo 比较
Spring Cloud 和 Dubbo 比较
- zigbee组网函数的一些用法
1.NLME_PermitJoiningRequest(0) :(1)值0x00:表示禁止加入网络 (2)值0x01-0xFE:表示允许链接的秒数 (3) 值0xff:表示启用网络 同时此函数:是 ...
- 在java中使用ssm框架的定时的实现
1.首先需要在application.xml里面配置如下的代码: xmlns:task="http://www.springframework.org/schema/task http:// ...
- GCOV&LCOV&GCOVR入门
索引 一.概述 二.关于gcov的安装 三.代码覆盖率测试(以GCOV为例) 1.编译源代码 2.运行可执行程序 3.通过gcov指令生成代码覆盖率报告 四.生成更全面.直观的代码覆盖率报告 1.LC ...
- KVO的使用二:常用方法及小技巧
(文章及代码接上一篇) options详解: KVO的注册方法中有一个options枚举,用来确定观察者的接收消息方法接收的信息,那么具体有什么关联呢?下面通过一段代码来验证是如何关联的.依次选择op ...