前提条件是主从同步操作完成(主从同步的前提是两个数据库表结构必须一样)
先看一下mysql配置文件
vi /usr/local/mysql/my.cnf
配置内容:------------------------------------------------------------------------------------
[client]
port=3306
socket=/tmp/mysql.sock
default-character-set=utf8
[mysql]
no-auto-rehash
#default-storage-engine=INNODB
default-character-set=utf8
[mysqld]
user = mysql
port = 3306
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysql3306.pid
log-error= /usr/local/mysql/logs/error.log
skip_name_resolve = 1
open_files_limit = 65535
back_log = 1024
max_connections = 1500
max_connect_errors = 1000000
table_open_cache = 1024
table_definition_cache = 1024
table_open_cache_instances = 64
thread_stack = 512K
external-locking = FALSE
max_allowed_packet = 32M
sort_buffer_size = 16M
join_buffer_size = 16M
thread_cache_size = 2250
query_cache_size = 0
query_cache_type = 0
interactive_timeout = 600
wait_timeout = 600
tmp_table_size = 96M
max_heap_table_size = 96M
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
event_scheduler=ON
###***slowqueryparameters
long_query_time = 0.1
slow_query_log = 1
slow_query_log_file = /usr/local/mysql/logs/slow.log
###***binlogparameters
log-bin=mysql-bin
binlog_cache_size=4M
max_binlog_cache_size=8M
max_binlog_size=1024M
binlog_format=MIXED
expire_logs_days=7
###***master-slavereplicationparameters
server-id=1
binlog-do-db=zabbix #只同步zabbix数据库
innodb_buffer_pool_size = 128M
innodb_flush_method = O_DIRECT
innodb_file_per_table = 1
#slave-skip-errors=all
[mysqldump]
quick
max_allowed_packet=32M
配置文件下载:https://pan.baidu.com/s/1Qd5oWsAQYESzn3pne8yBkg 密码:wanb
首先删除表
use zabbix
drop table history;
drop table history_text;
drop table history_log;
drop table history_str;
drop table history_uint;
drop table trends;
drop table trends_uint;
新建数据表
范例:(1471910400)==(UNIX_TIMESTAMP("2017-04-01 00:00:00"))
注意:时间设置为自修改日期到月底。
执行以下操作新建表:
CREATE TABLE `history` (
`itemid` bigint(20) unsigned NOT NULL,
`clock` int(11) NOT NULL DEFAULT '0',
`value` double(16,4) NOT NULL DEFAULT '0.0000',
`ns` int(11) NOT NULL DEFAULT '0',
KEY `history_1` (`itemid`,`clock`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
PARTITION BY RANGE (`clock`)
(PARTITION p20171101 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-1 23:59:00")) ENGINE = InnoDB,
PARTITION p20171102 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-2 23:59:00")) ENGINE = InnoDB,
PARTITION p20171103 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-3 23:59:00")) ENGINE = InnoDB,
PARTITION p20171104 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-4 23:59:00")) ENGINE = InnoDB,
PARTITION p20171105 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-5 23:59:00")) ENGINE = InnoDB,
PARTITION p20171106 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-6 23:59:00")) ENGINE = InnoDB,
PARTITION p20171107 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-7 23:59:00")) ENGINE = InnoDB,
PARTITION p20171108 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-8 23:59:00")) ENGINE = InnoDB,
PARTITION p20171109 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-9 23:59:00")) ENGINE = InnoDB,
PARTITION p20171110 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-10 23:59:00")) ENGINE = InnoDB,
PARTITION p20171111 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-11 23:59:00")) ENGINE = InnoDB,
PARTITION p20171112 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-12 23:59:00")) ENGINE = InnoDB,
PARTITION p20171113 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-13 23:59:00")) ENGINE = InnoDB,
PARTITION p20171114 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-14 23:59:00")) ENGINE = InnoDB,
PARTITION p20171115 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-15 23:59:00")) ENGINE = InnoDB,
PARTITION p20171116 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-16 23:59:00")) ENGINE = InnoDB,
PARTITION p20171117 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-17 23:59:00")) ENGINE = InnoDB,
PARTITION p20171118 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-18 23:59:00")) ENGINE = InnoDB,
PARTITION p20171119 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-19 23:59:00")) ENGINE = InnoDB,
PARTITION p20171120 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-20 23:59:00")) ENGINE = InnoDB,
PARTITION p20171121 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-21 23:59:00")) ENGINE = InnoDB,
PARTITION p20171122 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-22 23:59:00")) ENGINE = InnoDB,
PARTITION p20171123 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-23 23:59:00")) ENGINE = InnoDB,
PARTITION p20171124 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-24 23:59:00")) ENGINE = InnoDB,
PARTITION p20171125 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-25 23:59:00")) ENGINE = InnoDB,
PARTITION p20171126 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-26 23:59:00")) ENGINE = InnoDB,
PARTITION p20171127 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-27 23:59:00")) ENGINE = InnoDB,
PARTITION p20171128 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-28 23:59:00")) ENGINE = InnoDB,
PARTITION p20171129 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-29 23:59:00")) ENGINE = InnoDB,
PARTITION p20171130 VALUES LESS THAN (UNIX_TIMESTAMP("2017-11-30 23:59:00")) ENGINE = InnoDB
);
。。。。。。
sql文件根据实际情况修改
链接:https://pan.baidu.com/s/1vUPTQOIAWTHRN1Y1LWnkbQ 密码:cgxx
依次创建新的表结构
修改自动分区脚本中用户名和密码,拷贝自动分区脚本到指定目录下
主从都需要添加
chmod 755 autopartitions.sh
chown mysql.mysql autopartitions.sh
3.设置后台计划任务自动分区
执行crontab -e
01 01 * * * /data/mysqldb/autopartitions.sh
脚本下载
链接:https://pan.baidu.com/s/18N8rkh2vDhltq9DVjq9EhQ 密码:7o0l
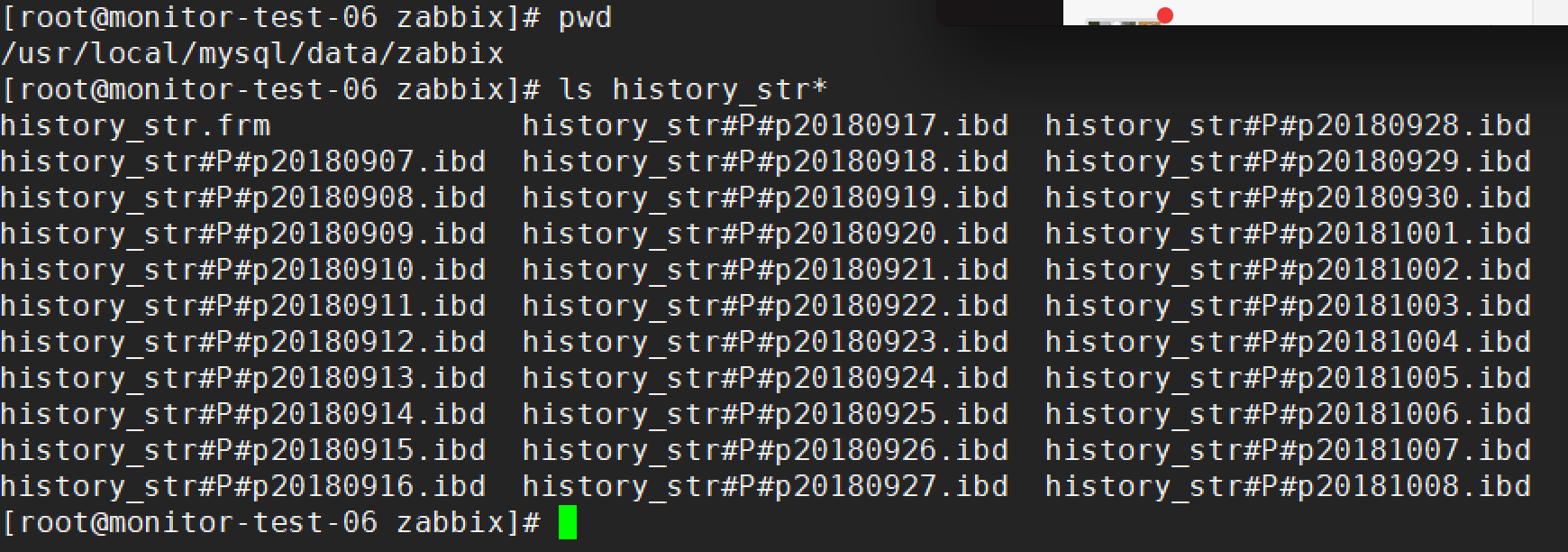
是否成功可以参考mysql配置文件中对应库文件下是否有基于日期的文件
主库
从库

- zabbix 数据库分表操作
近期zabbix数据库占用的io高,在页面查看图形很慢,而且数据表已经很大,将采用把数据库的数据目录移到新的磁盘,将几个大表进行分表操作 一.数据迁移: 1.数据同步到新的磁盘上,先停止mysql(不 ...
- MySQL数据库分表的3种方法
原文地址:MySQL数据库分表的3种方法作者:dreamboycx 一,先说一下为什么要分表 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目 ...
- Hibernate与数据库分表
数据库分片(shard)是一种在数据库的某些表变得特别大的时候采用的一种技术. 通过按照一定的维度将表切分,可以使该表在常用的检索中保持较高的效率,而那些不常用的记录则保存在低访问表中.比如:销售记录 ...
- 数据库分表之Mybatis+Mysql实践(含部分关键代码)
2018年01月31日 随着我们系统用户数量的日增,业务数据处于一个爆发前,增长的数据量已经给我们的系统造成了很大的不确定.在上个周末用户量较多,并发较大的情况下,读写频繁的验证码表,数据量 ...
- 一致性Hash算法在数据库分表中的实践
最近有一个项目,其中某个功能单表数据在可预估的未来达到了亿级,初步估算在90亿左右.与同事详细讨论后,决定采用一致性Hash算法来完成数据库的自动扩容和数据迁移.整个程序细节由我同事完成,我只是将其理 ...
- Oracle亿级数据查询处理(数据库分表、分区实战)
大数据量的查询,不仅查询速度非常慢,而且还会导致数据库经常宕机(刚接到这个项目时候,数据库经常宕机o(╯□╰)o). 那么,如何处理上亿级的数据量呢?如何从数据库经常宕机到上亿数据秒查?仅以此篇文章作 ...
- Mycat(4):消息表mysql数据库分表实践
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/46882777 未经博主同意不得转载. 1,业务需求 比方一个社交软件,比方像腾讯 ...
- MySQL数据库分表分区(一)(转)
面对当今大数据存储,设想当mysql中一个表的总记录超过1000W,会出现性能的大幅度下降吗? 答案是肯定的,一个表的总记录超过1000W,在操作系统层面检索也是效率非常低的 解决方案: 目前针对 ...
- 数据库分表和分库的原理及基于thinkPHP的实现方法
为什么要分表,分库: 当我们的数据表数据量,訪问量非常大.或者是使用频繁的时候,一个数据表已经不能承受如此大的数据訪问和存储,所以,为了减轻数据库的负担,加快数据的存储,就须要将一张表分成多张,及将一 ...
随机推荐
- input输入限制,只允许输入数字和“.”,长度不得超过20
<input style="margin-top: 10px;width: 100%;text-align:center;" id="removeArea" ...
- MySQL InnoDB 日志管理机制中的MTR和日志刷盘
1.MTR(mini-transaction) 在MySQL的 InnoDB日志管理机制中,有一个很重要的概念就是MTR.MTR是InnoDB存储擎中一个很重要的用来保证物理写的完整性和持久性的机制. ...
- 歌曲的BPM (Beat Per Minute)--每分钟节拍数
因为老爸喜欢跳舞,总让我帮他整理舞曲,一会儿要慢三,一会儿要慢四,一会儿又要快四....我真的分不清啊 我想啊,慢三,慢四这些应该是歌曲的节拍吧(后来得知专业术语叫BPM),于是就在网上搜看看能不能通 ...
- Windows server 2012 R2 部署WSUS补丁服务
一.WSUS 安装要求 1.硬件要求: 对于多达 13000 个客户端的服务器,建议使用以下硬件:* 4 Core E5-2609 2.1GHz 的处理器* 8 GB 的 RAM 2.软件要求: 要使 ...
- 【Teradata】扩容操作步骤
第一章,前期准备(旧系统信息收集) 1.DBScontrol关键信息 DBSCONTROL系统参数是在节点上设置的,其参数直接关系到系统全局,需要慎重设置,新节点的关键参数要与生产库一致或者相容.主要 ...
- nginx [alert] 12339#0: 1024 worker_connections are not enough
进一步分析报错原因,具体步骤如下: l 查看这两台系统最大的允许文件打开数 [root@nginx01 logs]# cat /proc/sys/fs/file-max 343927 l 通过ul ...
- vue-router(hash模式)常见问题以及解决方法
问题一:// 动态路由/detail/:id 问题:动态路由跳转的时候,页面是不刷新的,相信很多人都遇到了相同的问题解决方法:在全局的router-view组件上设置一个key值,此key值为一个时间 ...
- js前端导出Excel表格后数字自动变成科学计数法问题
一般的文件导出都是后端进行导出,最近一个项目遇到导出接口挂掉了,前端实现导出的情况. 背景是vue框架,iView组件.可以直接使用exportCsv方法进行导出. 导出时进行一下行和列的切割就可以了 ...
- c++stack类的用法
官方解释: LIFO stack Stacks are a type of container adaptor, specifically designed to operate in a LIFO ...
- SQL分组求每组最大值问题的解决方法收集 (转载)
例如有一个表student,其结构如下: id name sort score 1 张三 语文 82 2 李四 数 ...