hive的join
第一:在map端产生join
- set hive.auto.convert.join=true;
这样设置,hive就会自动的识别比较小的表,继而用mapJoin来实现两个表的联合。看看下面的两个表格的连接。这里的dept相对来讲是比较小的。我们看看会发生什么,如图所示:

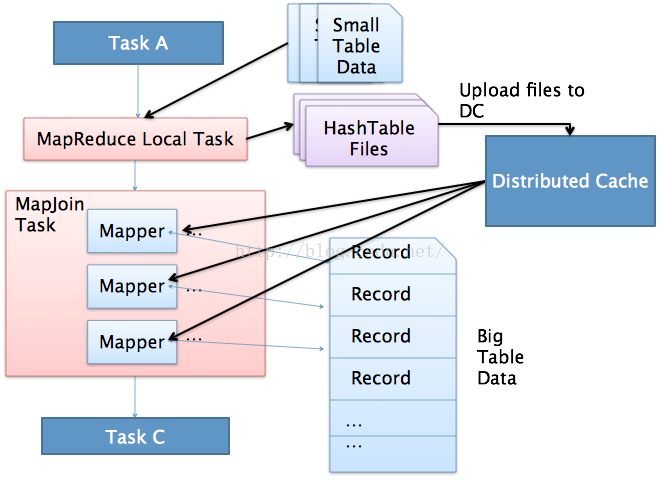
第二:common join

- set hive.auto.convert.sortmerge.join=true;
- set hive.optimize.bucketmapjoin = true;
- set hive.optimize.bucketmapjoin.sortedmerge = true;
- set hive.auto.convert.sortmerge.join.noconditionaltask=true;
- create table emp_info_bucket(ename string,deptno int)
- partitioned by (empno string)
- clustered by(deptno) into 4 buckets;
- insert overwrite table emp_info_bucket
- partition (empno=7369)
- select ename ,deptno from emp
- create table dept_info_bucket(deptno string,dname string,loc string)
- clustered by (deptno) into 4 buckets;
- insert overwrite table dept_info_bucket
- select * from dept;
- select * from emp_info_bucket emp join dept_info_bucket dept
- on(emp.deptno==dept.deptno);//正常的情况下,应该是启动smbjoin的但是这里的数据量太小啦,还是启动了mapjoin
hive的join的更多相关文章
- HIVE: Map Join Vs Common Join, and SMB
HIVE Map Join is nothing but the extended version of Hash Join of SQL Server - just extending Hash ...
- hive:join操作
hive的多表连接,都会转换成多个MR job,每一个MR job在hive中均称为Join阶段.按照join程序最后一个表应该尽量是大表,因为join前一阶段生成的数据会存在于Reducer 的bu ...
- Hive中Join的原理和机制
转自:http://lxw1234.com/archives/2015/06/313.htm 笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Joi ...
- Hive的join表连接查询的一些注意事项
Hive支持的表连接查询的语法: join_table: table_reference JOIN table_factor [join_condition] | table_reference {L ...
- hive的join查询
hive的join查询 语法 join_table: table_reference [INNER] JOIN table_factor [join_condition] | table_refere ...
- Hive 中Join的专题---Join详解
1.什么是等值连接? 2.hive转换多表join时,如果每个表在join字句中,使用的都是同一个列,该如何处理? 3.LEFT,RIGHT,FULL OUTER连接的作用是什么? 4.LEFT或RI ...
- Hive中Join的类型和用法
关键字:Hive Join.Hive LEFT|RIGTH|FULL OUTER JOIN.Hive LEFT SEMI JOIN.Hive Cross Join Hive中除了支持和传统数据库中一样 ...
- Hive 基本语法操练(五):Hive 的 JOIN 用法
Hive 的 JOIN 用法 hive只支持等连接,外连接,左半连接.hive不支持非相等的join条件(通过其他方式实现,如left outer join),因为它很难在map/reduce中实现这 ...
- hive的join优化
“国际大学生节”又称“世界大学生节”.“世界学生日”.“国际学生日”.1946年,世界各国学生代表于布拉格召开全世界学生大会,宣布把每年的11月17日定为“世界大学生节”,以加强全世界大学生的团结和友 ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
随机推荐
- docker安装小笔记
作者:邓聪聪 yum update Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker docker卸载旧版本(如 ...
- Discuz x 转码要记
Discuz 开源项目仅保留了 UTF8 编码版本,要从GBK版本升级,须进行编码转换. 转换主要执行以下步骤: 关闭网站,做好源文件备份: 导出数据库,在MySQL中生成Self-Contained ...
- 【Flask】报错解决方法:AssertionError: View function mapping is overwriting an existing endpoint function: main.user
运行Flask时出现了一个错误, AssertionError: View function mapping is overwriting an existing endpoint function: ...
- JVM内存模型分析(一个程序运行的例子)
(.class字节码)类加载到内存之后,内存模型:(ps:.class文件可以通过javap 指令反编译成一个可读文件) 1.java栈,本地方法栈,程序计数器(每个线程私有) 看如下程序: 以该程序 ...
- tp5.1入口文件隐藏
修改.htaccess文件 <IfModule mod_rewrite.c> Options +FollowSymlinks -Multiviews RewriteEngine On Re ...
- arm寄存器
ARM 处理器拥有 37 个寄存器. 这些寄存器按部分重叠组方式加以排列. 每个处理器模式都有一个不同的寄存器组. 编组的寄存器为处理处理器异常和特权操作提供了快速的上下文切换. 提供了下列寄存器:三 ...
- Redis数据类型SortedSET
Sorted Set有点像Set和Hash的结合体.和Set一样,它里面的元素是唯一的,类型是String,所以它可以理解为就是一个Set.但是Set里面的元素是无序的,而Sorted Set里面的元 ...
- 二.Nginx反向代理和静态资源服务配置
2018年03月31日 10:30:12 麦洛_ 阅读数:1362更多 所属专栏: nginx 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/M ...
- Codeforces 959F Mahmoud and Ehab and yet another xor task 线性基 (看题解)
Mahmoud and Ehab and yet another xor task 存在的元素的方案数都是一样的, 啊, 我好菜啊. 离线之后用线性基取check存不存在,然后计算答案. #inclu ...
- Linux下crontab计划任务使用详解
Linux在相应用户下,用crontab -l 命令可以查看该用户定时执行的任务,-e可以编辑,但是其真实文件在哪儿呢??以CentOS为例,其真实的位置在:/var/spool/cron下面,有执行 ...