大数据学习-2 认识Hadoop
一.什么是Hadoop?
Hadoop可以简单的理解为一个数据存储和数据分析分布式系统。随着互联网的普及产生的数据是非常的庞大的,那么我们怎么去处理这么大量的数据呢?传统的单一计算机肯定是完成不了的,那么大体的出路只有两条,第一种是研究更牛逼的计算机(比如说超级计算机和量子计算机),但是超级计算机和量子计算机研究耗费的时间和金钱是难以想象的,第二条就是集群计算(数据量巨大一台计算机不行,我一百台,一万台计算机处理总可以了吧?)那么Hadoop就是后者。
Hadoop并不是去强化某一台计算机的计算能力而是去解决一百台、一万台计算机集群计算时的故障和异常,为这一百台、一万台计算机集群计算提供可能性服务。在简单来说就是Hadoop就是让这么多计算机一起去处理一批数据,保证数据在这么多的机子上还不出错。
二.Hadoop的发展历史
在这里我们不得不去提一下Apache软件基金会,他是一个是专门为支持开源软件项目而办的一个非盈利性组织。在它所支持的Apache项目与子项目中,所发行的软件产品都遵循Apache许可证(Apache License)。
那么Hadoop就是在这个基金会下诞生的。
最开始我们还是要讲到谷歌,谷歌为了摆脱IOE(IBM小型机、Oracle数据库以及EMC存储)就创建了他们的GFS(Google File System)也是一个文件分布式系统,并发表了三篇分别有关与GFS、MapReduce、BigTable的论文但是没有开源GFS的核心技术。然后在论文的指导下Doug Cutting(Hadoop之父)对其做了开发并且开源。最后Apache软件基金会对Doug Cutting的开发和其他公司的开发其进行了整合完善推出了Hadoop。
三.为什么要使用Hadoop?
3.1开始我们一定会有这样的问题就是为什么MySQL、Oracle等等数据库不能满足大量的数据的查询呢?
首先传统的数据库底层还是对磁盘的一个读写操作,那么读写操作就要涉及到一个寻找地址的操作,但是这个寻址操作是十分耗费时间的(虽然在数据库上有很多的优化包括索引操作等等),那么读取大量数据的时候这个时间必然会很长(再好的算法在合理的数据结构设计还是会去遍历数据)。
在一个就是就是更改数据库操作,对于有大量的数据数据库我们去更新它的时候往往会增加这个数据库的压力,而且效率较为低下。
3.2那么传统的数据库在大数据(PB级别 1PB=1024TB)存在一定的缺陷那么我们该怎么去解决呢?
现在我们就要引入MapReduce这个概念,首先来了解一下MapReduce,在后面我们会详细的去学习Hadoop中的MapReduce,MapReduce的简单介绍如下:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。(其实我现在也不太懂MapReduce这个编程模型,但是通过我们后期的学习一定可以搞懂)
那么我么来对比一下他们MapReduce和传统的关系型数据库的对比
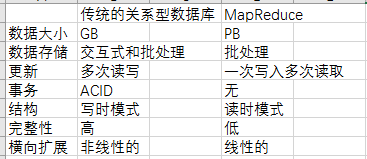
3.3MapReduce的三大设计目标
1.服务于只需要短短几分钟或者几个小时就可以完成任务
2.运行于同一个内部有高速网络连接的数据中心内
3.数据中心内部的计算机都是可靠的专门的硬件
四.部分专业名词介绍
4.1MapReduce中的专业名词
job:一个MapReduce程序就是一个job。
task:在一个job中可以有多个task,task可以是Map Task,Reduce Task,这个task就是每个节点计算机的计算任务。
HDFS:Hadoop分布式文件系统(Hadoop distributed file system)
Namenode:它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata),没有namenode那么HDFS就不能运行
Secondary Namenode:主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大,如果namenode宕机了,secondary namenode中的文件就会用的上。大多数情况下会与NFS远程挂载。
DateNode:Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
JobTracker:负责任务的管理和调度(一个hadoop集群中只有一台JobTracker)
TaskTracker:负责执行工作,在DataNode节点上执行(Map函数和Reduce函数运行的节点)
五.理解MapReduce
5.1MapReduce高度抽象
将多台计算机联合起来处理一个问题那么这个过程一定是相当复杂的,但是Hadoop将其高度的抽象了,他只需要程序员去编写map函数和reduce函数即可。
5.2MapReduce的工作流
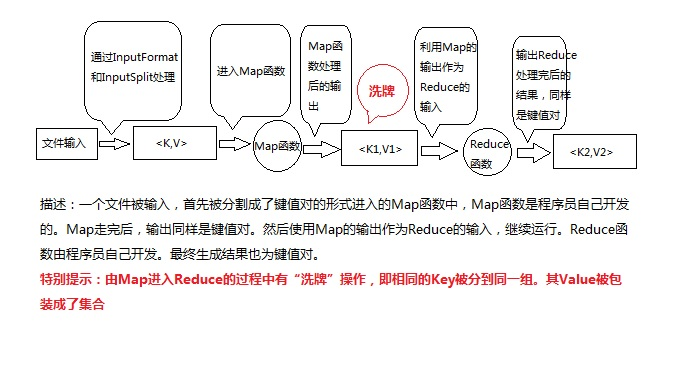 图片来自:https://blog.csdn.net/chaojixiaozhu/article/details/78931413
图片来自:https://blog.csdn.net/chaojixiaozhu/article/details/78931413
5.3map任务和reduce任务作用介绍
map任务将其输出写入本地硬盘,而非HDFS。这是为什么?因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除。因此,如果把它存储在HDFS中并实现备份,难免有些小题大做。如果该节点上运行的map任务在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
reduce任务并不具备数据本地化的优势——单个reduce任务的输入通常来自于所有mapper的输出。在本例中,我们仅有一个reduce任务,其输入是所有map任务的输出。因此,排过序的map输出需通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。reduce的输出通常存储在HDFS中以实现可靠存储。对于每个reduce输出的HDFS块,第一个副本存储在本地节点上,其他副本存储在其他机架节点中。因此,将reduce的输出写入HDFS确实需要占用网络带宽,但这与正常的HDFS流水线写入的消耗一样。(该部分截取自 https://blog.csdn.net/universe_ant/article/details/56494398)
大数据学习-2 认识Hadoop的更多相关文章
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
- 大数据学习笔记4 - Hadoop的优化与发展(Hadoop 2.0)
前面介绍了Hadoop核心组件HDFS和MapReduce,Hadoop发展之初在架构设计和应用性能方面仍然存在不足,Hadoop的优化与发展一方面体现在两个核心组件的架构设计改进,一方面体现在Had ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
随机推荐
- hdu6415 记忆化搜索或找规律
Rikka with Nash Equilibrium Time Limit: / MS (Java/Others) Memory Limit: / K (Java/Others) Total Sub ...
- 刷题upupup【Java中Queue、Stack、Heap用法总结】
[Queue] 先进先出(First-In-First-Out),LinkedList实现了Queue接口.它只允许在表的前端进行删除操作,而在表的后端进行插入操作. add() 增加一个 ...
- C#生成.tlb文件初认识
刚接手同事的代码,生成文件时,发现生成了一个对应的dll文件(应用程序中输出类型为类库),和一个对应的.tlb文件,但是报如下的错误: 那么.tlb文件是如何生成的呢? 选择项目->右键属性-& ...
- 查看JVM内存使用状况
1.jps:查看本地正在运行的java进程和进程ID(pid) 2.jinfo pid,查看指定pid的所有JVM信息 1)jinfo -flags pid 查询虚拟机运行参数信息. 2)jinfo ...
- echarts 去掉 x轴坐标
symbol:'none', //这句就是去掉点的 smooth:true,
- centos 日志文件
以下介绍的是20个位于/var/log/ 目录之下的日志文件.其中一些只有特定版本采用,如dpkg.log只能在基于Debian的系统中看到./var/log/messages — 包括整体系统信息, ...
- SharePoint CU、Hotfix和SP版本的区别
1.Hotfix:通常是对一个特殊问题的修复包 2.CU(Cumulative Update):Hotfix的集合,包含从上一个SP(Service Pack)版本以来所有的Hotfix 3.SP(S ...
- Ubuntu16.04下安装sublime text3
通过ppa安装,打开终端,输入以下命令: sudo add-apt-repository ppa:webupd8team/sublime-text-3 sudo apt-get update sudo ...
- eclipse svn不显示提交人、提交时间的问题
最近eclipse换到最新的mars版本,装了svn插件subversive后,拉下项目后发现都不显示提交人了,以前都不这样的呀,新版不一样了么? 后来网上搜索总算找到方法解决: Window--&g ...
- http/1.0/1.1/2.0与https的比较
HTTP是HyperText Transfer Protocol的缩写,译为超文本传输协议.是一种应用于OSI七层模型中应用层的协议,是我们平常互联网网络通信传输的基础.它的作用就是规定了服务器和客户 ...