C++ 几种经典的垃圾回收算法
之前遇到了一篇好文(https://blog.csdn.net/wallwind/article/details/6889917)准备学习一下的,课程繁忙就忘记了,今日得闲,特来补一下。
自己写一遍加深一下印象。
1.引用计数算法
引用计数(Reference Counting)算法是每个对象计算指向它的指针的数量
当有一个指针指向自己时,计数器+1;
当删除一个指向自己的指针时,计数器-1
如果计数器减为0,说明不存在指向该对象的指针了所以它可以被安全地销毁了。
如图:
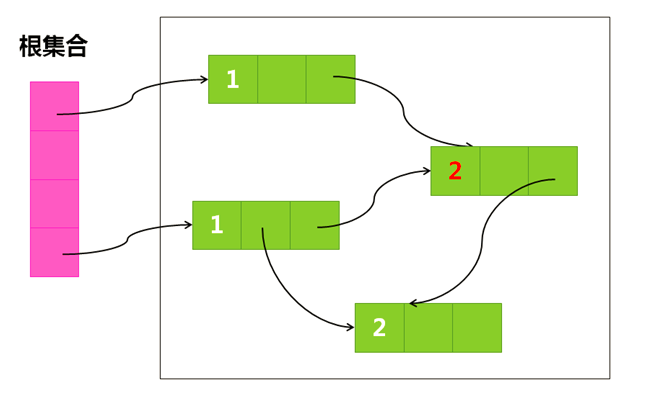
引用计数算法 优点:
1)内存管理的开销分布于整个应用程序运行期间,非常的“平滑“,无需挂起应用程序的运行来做垃圾回收;
2)空间上的引用局部性比较好。当某个对象的引用计数器为0时,系统无需访问位于堆中其他页面的单元,而后面我们将要看到的几种垃圾回收算法在回收前都会遍历所有的存活单元,这可能会引起换页(Paging)操作;
3)引用计数算法提供了一种类似栈分配的方式,废弃即回收,后面我们将要看到的几种垃圾回收算法在对象废弃后,都会存活一段时间,才会被回收。
引用计数算法 缺点
1)时间上的开销。每次在对象创建或者释放的时,都要计算引用计数器,这会引起一些额外的开销;
2)空间的开销,由于每个对象要保持自己被引用的数量,必须付出额外的空间来存放引用计数器;
3)它无法处理环形引用,如下图:
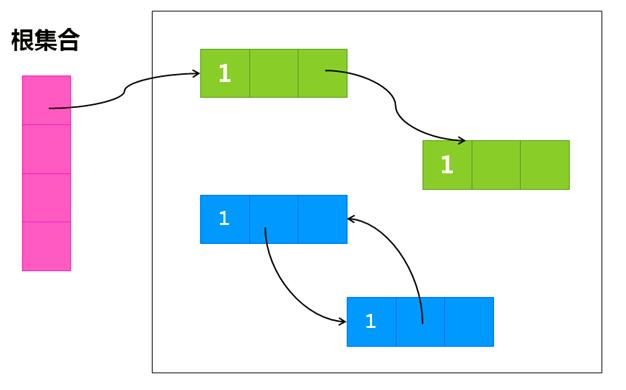
此处蓝色的这两个对象既不可达也无法回收,因为彼此之间互相引用,它们各自的计数器不为0,这种情况对引用计数算法来说是无能为力的,而其他的垃圾回收算法却能很好的处理环形引用。
引用计数算法最著名的运用,莫过于微软的COM计数,大名鼎鼎的IUnknown接口:
interface IUnknown
{
virtual HRESULT _stdcall QueryInterface
(const IID& iid, void* * ppv) = ;
virtual ULONG _stdcall AddRef() = ;
virtual ULONG _stdcall Release() = ;
}
其中的AddRef和Release就是用来让组件自己管理其生命周期,而客户程序只管in接口,而无法再去关心组件的生命周期,一个简单的使用实例如下:
int main()
{
IUnknown* pi = CreateInstance(); IX* pix = NULL;
HRESULT hr = pi->QueryInterface(IID_IX, (void*)&pix);
if(SUCCEEDED(hr))
{
pix->DoSomething();
pix->Release();
} pi->Release();
}
上面的客户程序在CtreatInstance中已经调用过AddRef,所以无需再次调用,而在使用完几口后调用Release,这样组件自己维护的计数器将会改变。下面代码给出一个简单的实现AddRef和Release示例:
ULONG _stdcall AddRef()
{
return ++ m_cRef;
} ULONG _stdcall Release()
{
if(--m_cRef == )
{
delete this;
return ;
}
return m_cRef;
}
在编程语言Python中,使用也是引用计数算法,当对象的引用计数值为0时,将会调用__del__函数,至于为什么Python要选用引用计数算法,据我看过的一篇文章里面说,由于Python作为脚本语言,经常要与C/C++这些语言交互,而使用引用计数算法可以避免改变对象在内存中的位置,而Python为了解决环形引用问题,也引入gc模块,所以本质上Python的GC的方案是混合引用计数和跟踪(后面要讲的三个算法)两种垃圾回收机制。
2.标记-清除算法
标记-清除(Mark-Sweep)算法依赖于对所有存活对象进行一次全局遍历来确定哪些对象可以回收,遍历的过程从根出发,找到所有可达的对象,除此之外,其他不可达的对象就是垃圾对象,可被回收。
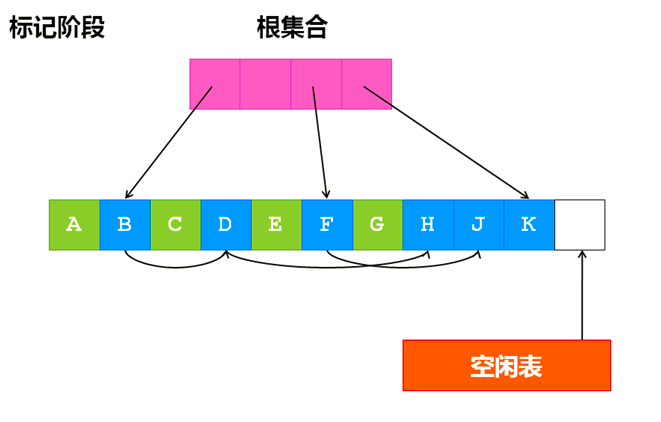
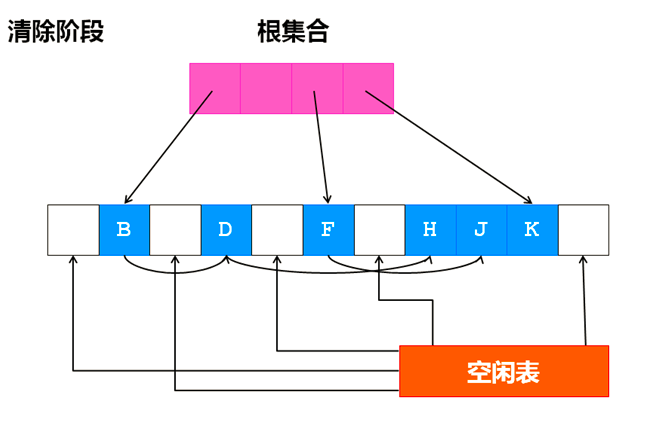
相比较引用计数算法,标记-清除算法可以非常自然的处理环形引用问题,另外在创建对象和销毁对象时少了引用计数器的开销。
它的缺点在于标记-清除算法需要研究如何减少它的停顿时间,而分代式垃圾收集器就是为了减少它的停顿时间,后面会说到。
另外,标记-清除算法在标记阶段需要遍历所有的存活对象,会造成一定的开销,在清除阶段,清除垃圾对象后会造成大量的内存碎片需要遍历所有的存活对象,这样会造成一定的时间开销,在清除阶段,清除垃圾对象后会造成大量的内存碎片。
3.标记-缩并算法
标记-缩并算法是为了解决内存碎片问题而产生的一种算法。它的整个过程可以描述为:标记所有的存活对象;通过重新调整存活对象位置来缩并对象图;更新指向被移动了位置的对象的指针。

缩并阶段 根集合

标记-缩并算法最大的难点在于如何选择缩并算法,如果缩并算法选择得不好,将会导致极大的程序性能问题,如导致Cache命中率低等。一般来说,根据压缩后对象的位置不同,压缩算法可以分为以下三种:
1. 任意:移动对象时不考虑它们原来的次序,也不考虑它们之间是否有互相引用的关系。
2. 线性:尽可能地将原来的对象和它所指向的对象放在相邻的位置上,这样可以达到更好的空间局部性。
3. 滑动:将对象“滑动”到对的一端,把存活对象之间的自由单元“挤出去”,从而维持了分配时的原始次序。
4.节点拷贝算法
节点拷贝算法(GC)是把整个堆分为两个半区(From、To),GC的过程其实就是把存活的对象从一个半区From拷贝到另一个半区To的过程,而在下一次回收的时候,两个半区互换角色。在移动结束后,再更新对象的指针引用,GC开始前的情形:

GC结束后的情形:

节点拷贝算法由于在拷贝过程中,就可以进行内存整理,所以不会再有内存碎片的问题,同时也不需要再专门做一次内存压缩。,而它最大的缺点在于需要双倍的空间。
5.总结
本文总共介绍了四种经典的垃圾回收算法,其中后三种经常称之为跟踪垃圾回收,因为引用计数算法能够平滑的进行垃圾回收,而不会出现“停止”现象,经常出现于一些实时系统中,但它无法解决环形问题;而基于跟踪的垃圾回收机制,在每一次垃圾回收过程中,要遍历或者复制所有的存活对象,这是一个非常耗时的工作,一种好的解决方案就是对堆上的对象进行分区,对不同区域的对象使用不同的垃圾回收算法,分代式垃圾回收器正是其中一种,CLR和JVM中都采用了分代式垃圾回收机制,但它们在处理上又有些不同。
感谢您的阅读,生活愉快~
C++ 几种经典的垃圾回收算法的更多相关文章
- C/C++中几种经典的垃圾回收算法
1.引用计数算法 引用计数(Reference Counting)算法是每个对象计算指向它的指针的数量,当有一个指针指向自己时计数值加1:当删除一个指向自己的指针时,计数值减1,如果计数值减为0,说明 ...
- 垃圾回收算法手册:自动内存管理的艺术 BOOK
垃圾回收算法手册:自动内存管理的艺术 2016-03-18 华章计算机 内容简介 PROSPECTUS 本书是自动内存管理领域的里程碑作品,汇集了这个领域里经过50多年的研究沉积下来的最佳实践,包含当 ...
- JVM03——四种垃圾回收算法,你都了解了哪几种
在之前的文章中,已经为各位带来了JVM的内存结构与堆内存的相关介绍,今天将为为各位详解JVM垃圾回收与算法.关注我的公众号「Java面典」了解更多 Java 相关知识点. 如何确定垃圾 想要回收垃圾, ...
- JVM垃圾回收算法及回收器详解
引言 本文主要讲述JVM中几种常见的垃圾回收算法和相关的垃圾回收器,以及常见的和GC相关的性能调优参数. GC Roots 我们先来了解一下在Java中是如何判断一个对象的生死的,有些语言比如Pyth ...
- 【JVM从小白学成大佬】4.Java虚拟机何谓垃圾及垃圾回收算法
在Java中内存是由虚拟机自动管理的,虚拟机在内存中划出一片区域,作为满足程序内存分配请求的空间.内存的创建仍然是由程序猿来显示指定的,但是对象的释放却对程序猿是透明的.就是解放了程序猿手动回收内存的 ...
- Java虚拟机之垃圾回收算法思想总结
1.引用计数法 这是个比较古老而经典的垃圾回收算法,其核心就是在对象被其他所引用的时候计数器加1,而当引用失去时减1.这个方法有非常严重的问题:无法此话有理循环引用的情况,还有就是每次进行加减操作比较 ...
- 直通BAT必考题系列:JVM的4种垃圾回收算法、垃圾回收机制与总结
垃圾回收算法 1.标记清除 标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段. 在标记阶段首先通过根节点(GC Roots),标记所有从根节点开始的对象,未被标记的对象就是未被引用的垃圾对象. ...
- (5)jvm垃圾回收器相关垃圾回收算法
引用计数法[原理]--->引用计数器是经典的也是最古老的垃圾收集防范.--->实现原理:对于对象A,只要有任何一个对象引用A,则计数器加1.当引用失效时,计数器减1.只要对象A的计数器值为 ...
- 【JVM】jvm垃圾回收器相关垃圾回收算法
引用计数法[原理]--->引用计数器是经典的也是最古老的垃圾收集防范.--->实现原理:对于对象A,只要有任何一个对象引用A,则计数器加1.当引用失效时,计数器减1.只要对象A的计数器值为 ...
随机推荐
- 【转】线程间操作无效: 从不是创建控件“textBox2” 的线程访问它。
using System;using System.Collections.Generic;using System.ComponentModel;using System.Data;using Sy ...
- phpcms数据结构
v9_admin 管理员表 v9_admin_panel 快捷面板 v9_admin_role 角色表 v9_admin_role_priv 管理员权限表 v9_announce 公告表 v9_att ...
- 【文件上传】文件上传的form表单提交方式和ajax异步上传方式对比
一.html 表单代码 …… <input type="file" class="file_one" name="offenderExcelFi ...
- align-items和align-content的区别
最近在研究flex布局,容器中有两个属性,是用来定义crossAxis测轴排列方式的.一开始接触align-items还可以理解感觉不难,后来看到align-content就感觉有点混淆了,特开一篇博 ...
- 正在载入中......loading页面的几种方法
网页加载过程中提示“载入中…”,特别是使用动画效果,可以一个“等待”的温馨提示,用户体验很不错.下面介绍几种方法. 第一种: 原理就是,在网页载入时在页面最中间打入一个层上面显示,"网页正在 ...
- 【LinuxC】GCC编译C程序,关闭随机基址
1.编译.链接和运行程序 C代码示例: #include <stdio.h> #include <stdlib.h> int main() { printf("hel ...
- Mysql_Learning_Notes_mysql系统结构_2
Mysql_Learning_Notes_mysql系统结构_2 三层体系结构,启动方式,日志类型及解析方法,mysql 升级 连接层 通信协议处理\线程处理\账号认证(用户名和密码认证)\安全检查等 ...
- C#利用System.Net发送邮件
啥也不说了,直接上干货 using System.Net.Mail;using System.Net; //使用发送邮件的邮箱 var emailAcount = "826217795@qq ...
- Scrapy的【SitemapSpider】的【官网示例】没有name属性
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0, 上午看了Scrapy的Spiders官文,并按照其中的SitemapSpider的示例练习,发现官文的示例存在问题 ...
- python基础-类的封装
封装:类中封装了公有属性和方法,对象封装了私有属性的值 class F1: def __init__(self,n): self.N=n print('F') class F2: def __init ...