ubuntu16.04上Eclipse和hadoop配置
1.安装Eclipse
1》下载Eclipse
可以以多种方式下载Eclipse,下面介绍直接从eplise官网下载和从中国镜像站点下载,下载把eclipse上传到Hadoop环境中。
第一种方式从elipse官网下载:
http://www.eclipse.org/downloads/?osType=linux
我们运行的环境为CentOS 64位系统,需要选择eclipse类型为linux,然后点击linux 64bit链接下载
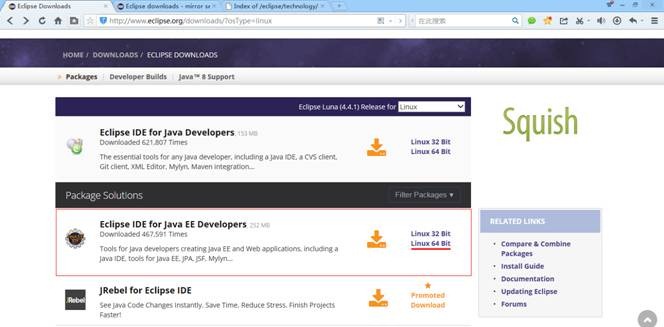
会根据用户所在地,推荐最佳的下载地址
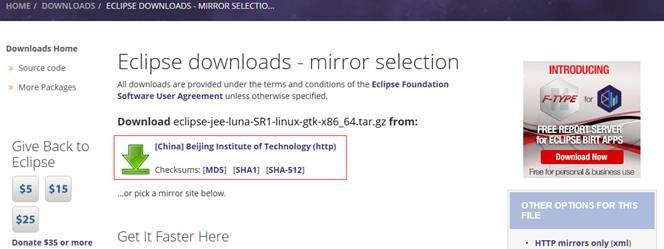
在该页面的下部分也可以根据自己的情况选择合适的镜像站点进行下载

第二种方式从镜像站点直接下载elipse:
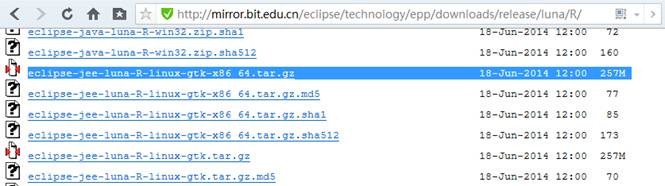
http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/
在镜像站点选择 eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz进行下载
(http://mirror.bit.edu.cn/eclipse/technology/epp/downloads/release/luna/R/eclipse-jee-luna-R-linux-gtk-x86_64.tar.gz)
2》解压elipse
在/home/hadoop/Downloads/目录中,使用如下命令解压elipse并移动到/usr/local目录下:
cd /home/hadoop/Downloads
tar -zxvf eclipse-jee-luna-SR1-linux-gtk-x86_64.tar.gz
sudo mv eclipse /usr/local/
cd /usr/local
ls


3》启动eclipse
登录到虚拟机桌面,进入/usr/local/eclipse目录,通过如下命令启动eclipse:
cd /usr/local/eclipse
./eclipse
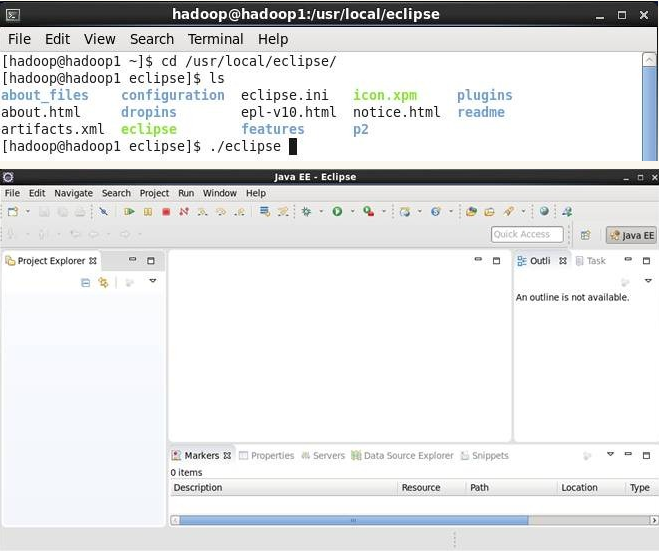
为了方便操作,可以在虚拟机的桌面上建立elipse的快捷操作
2.在Eclipse中安装hadoop插件
Hadoop2.7.1插件下载:http://download.csdn.net/download/gaoyunbo007/9973198
1、将下载好的插件移动到eclipse安装目录下的plugins文件夹下。
2、重新启动eclispe,配置hadoop安装目录和hdfs端口。
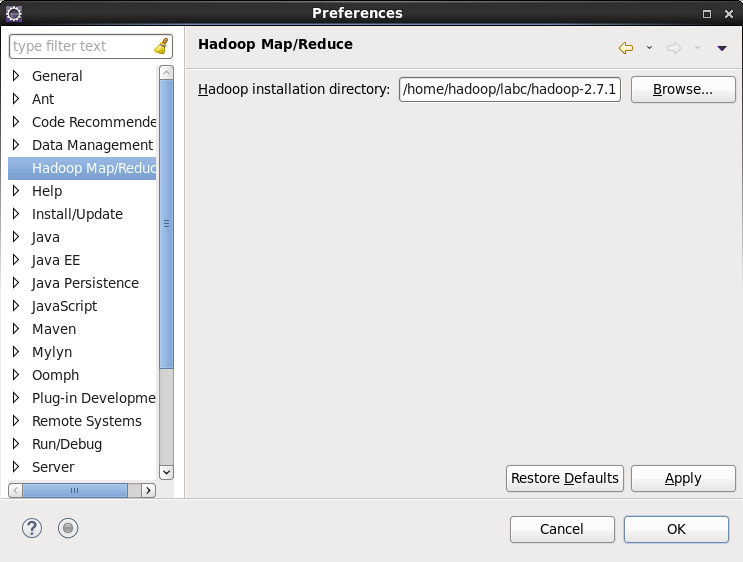
如果插件安装成功,打开【Windows】—>【Preferences】后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置hadoop安装路径,然后点击【OK】。
打开【Windows】–>【Perspective】–>【Open perspective】–>【Other】,选择【Map/Reduce】,点击【OK】。

点击【Map/Reduce Location】选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
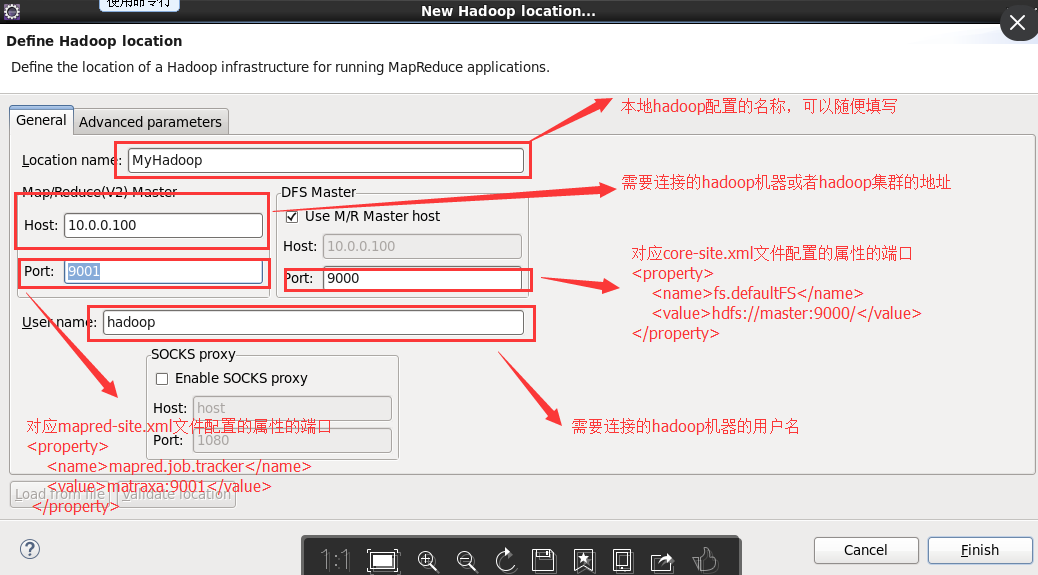
输入Location Name,任意名称即可。配置Map/Reduce Master,Host和Port配置成与mapred-site.xml的设置一致和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致,点击【Finish】。
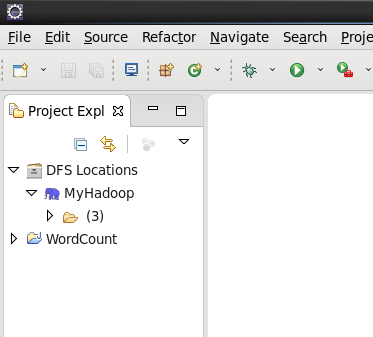
点击左侧的DFSLocations—>MyHadoop(上一步配置的location name),如果不报错,表示安装成功。
注意:这里和Hadoop1.x不一样,1.x版本这里会有user文件夹,2.x以后没有,如果你是新装的hadoop,这里显示的文件数为0,此时并不是报错。
3.测试插件是否配置成功
新建WordCount项目
1、点击【File】—>【Project】,选择【Map/Reduce Project】,输入项目名称WordCount,一直回车。
在WordCount项目里新建class,名称为WordCount,代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}2、在HDFS上创建目录input
hadoop fs -mkdir /input
3、拷贝本地README.txt到HDFS的input里
hadoop fs -copyFromLocal /home/hadoop/labc/hadoop/README.txt /input
4、点击WordCount.java,右键,点击【Run As】—>【Run Configurations】,配置运行参数,即输入和输出文件夹
hdfs://Master:9000/input hdfs://Master:9000/output
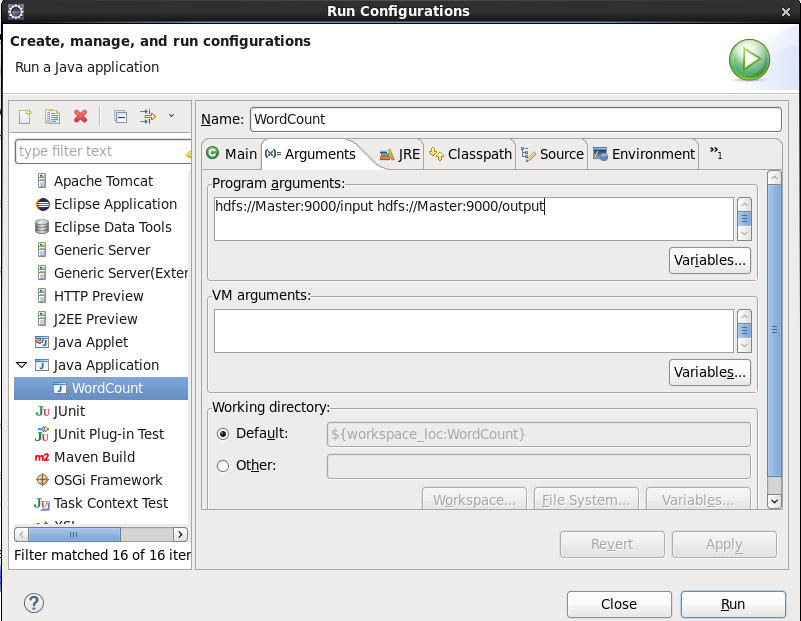
5、点击【Run】,运行程序。
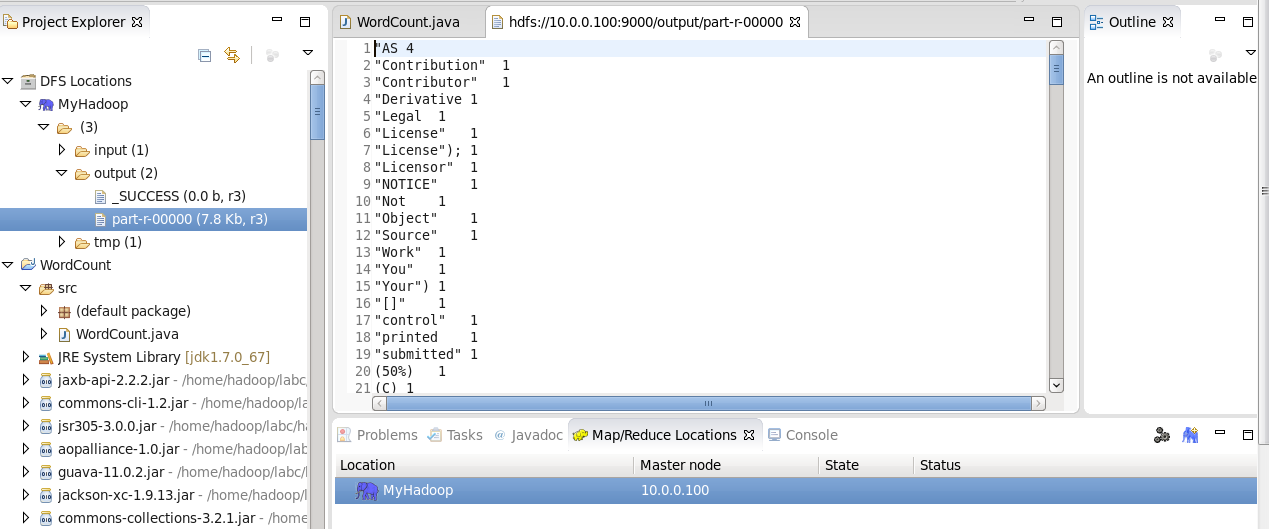
查看运行结果:
1> 在控制台输入:
hadoop fs -cat /output/part-r-00000
2>展开【DFS Locations】
ubuntu16.04上Eclipse和hadoop配置的更多相关文章
- 在ubuntu16.04上安装eclipse
在ubuntu16.04上安装eclipse 一.下载 首先我们需要安装jdk1.8及其以上,然后从官网:https://www.eclipse.org/downloads/上下载,需要注意 ...
- 在ubuntu16.04上编译android源码【转】
本文转载自:http://blog.csdn.net/fuchaosz/article/details/51487585 1 前言 经过3天奋战,终于在Ubuntu 16.04上把Android 6. ...
- ubuntu16.04上在使用搜狗输入法时,按shift不能正常切换中英文
问题描述: ubuntu16.04上在使用搜狗输入法时,不知道把什么组合键给错按了,导致了按shift不能正常切换中英文,这是一件很烦恼的事儿! 解决步骤: 1,终端输入打开: fcitx-confi ...
- primecoin在ubuntu16.04上部署服务:
primecoin在ubuntu16.04上部署服务: 一.下载Tomcat,Jdk,primecoin(公司内部文件) 注意Tomcat版本需要高于Jdk的,不然会报错. 二.把它们都解压到你要的安 ...
- Ubuntu16.04上安装cudnn教程和opencv
https://blog.csdn.net/wang15061955806/article/details/80791112 Ubuntu16.04上安装cudnn教程 2018年06月24日 14: ...
- Ubuntu11.04上tftp服务的配置
Ubuntu11.04上tftp服务的配置 2011-06-17 15:01 以前ubuntu版本上的tftp已经配置很多遍了,详情可以参见:www.mcuos.com/thread-646-1-2. ...
- Ubuntu16.04上用源代码安装ICE
ubuntu16.04上用源代码安装ICE
- Ubuntu16.04上安装neo4j数据库
什么是neo4j数据库? neo4j数据库是图数据库的一种,属于nosql的一种,常见的nosql数据库还有redis.memcached.mongDB等,不同于传统的关系型数据库,nosql数据也有 ...
- 【MindSpore】Ubuntu16.04上成功安装GPU版MindSpore1.0.1
本文是在宿主机Ubuntu16.04上拉取cuda10.1-cudnn7-ubuntu18.04的镜像,在容器中通过Miniconda3创建python3.7.5的环境并成功安装mindspore_g ...
随机推荐
- VHDL实例化过程
第二步:建立一个名为MUX_0的乘法器 第三步:在程序中例化,看以下程序. -- 该程序用来实现复数的乘法,端口分别定义的复数的 -- 输入的实部和虚部和输出的实部和虚部 LIBRARY IEEE; ...
- faceswap安装说明
Installing Faceswap Installing Faceswap Prerequisites Hardware Requirements Supported operating syst ...
- springmvc 开涛 生产者/消费者
媒体类型: text/html, text/plain, text/xml image/gif, image/jpg, image/png application/x-www-form-urlenco ...
- delphi 动态加载dll
引入文件 DLL比较复杂时,可以为它的声明专门创建一个引入单元,这会使该DLL变得更加容易维护和查看.引入单元的格式如下: unit MyDllImport; {Import unit for MyD ...
- DevExpress中Tile Application窗体的模型架构图
DEV中Tile Application模型架构比较复杂,整理一下和大家分享. 图中:立体代表类:虚线椭圆代表属性.
- 在Sublime中集成Team Foundation Server (TFS),实现版本管理
Sublime是一款具有代码高亮.语法提示.自动完成且反应快速的编辑器软件,由于它开发的技术架构.丰富的插件,和轻盈而快速的编程响应,Sublime广受程序员的爱好.在C, C++, Javascri ...
- INDEX--创建索引和删除索引时的SCH_M锁
最近有一个困惑,生产服务器上有一表索引建得乱七八糟,经过整理后需要新建几个索引,再删除几个索引,建立索引时使用联机(ONLINE=ON)创建,查看下服务器负载(磁盘和CPU压力均比较低的情况)后就选择 ...
- python——回文函数(reversed)
回文数:正向排列与反向排列所得结果是相等的(即从左到右和从右到左的结果是相等的),例如:“123321”,“0000”等. reversed函数:反转一个序列对象,将其元素从后向前颠倒构建成一个新的迭 ...
- Js加密算法
使用crypto-js在浏览器上对数据加密签名 重要知识点: CryptoJS.lib.WordArray WordArray对象可以理解为byte[] CryptoJS.enc 提供编码转换,从字 ...
- JS 中的数据类型转换
转成字符串 String 1. 使用 toString方法 这种方法可以将 number, boolean, object,array,function 转化为字符串,但是无法转换 null, und ...