Java数据结构和算法(五)二叉排序树(BST)
Java 数据结构 - 堆和堆排序:为什么快排比堆排序性能好
数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html)
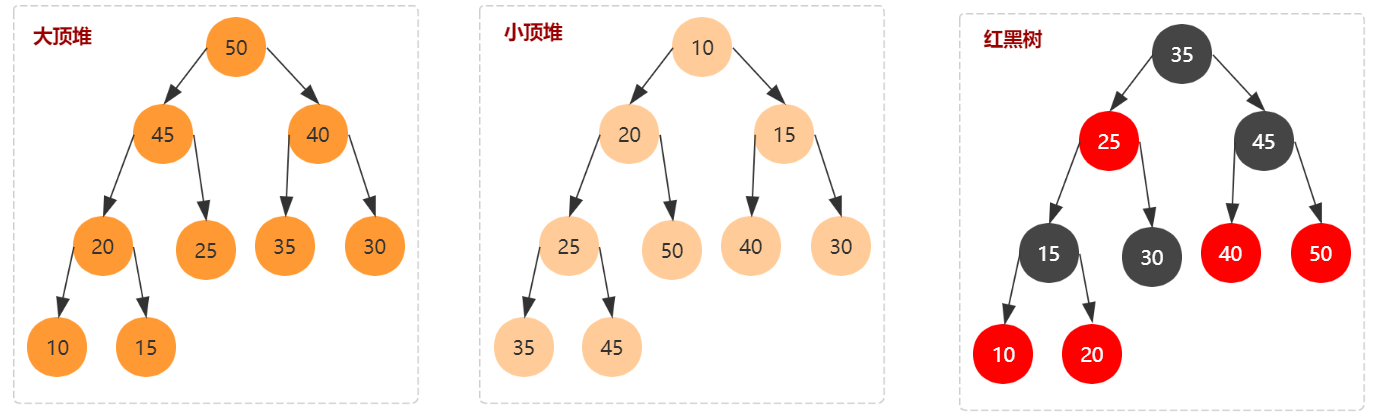
关于二叉树这种数据结构在实现软件工程中的应用,前面我们已经介绍了红黑树,下面我们再介绍另一种常见的二叉树 - 堆。
- 红黑树:基于平衡二叉查找树的动态数据结构,用于快速插入和查找数据,其时间复杂度都是 O(logn)。
- 堆:按照结点大于等于(或小于等于)子结点,又分为大顶堆和小顶堆。和红黑树不同,椎只是部分有序,即 "左结点 < 父结点 && 右结点 < 父结点",而有序二叉树要求 "左结点 < 父结点 < 右结点"。椎插入和删除元素的时间复杂度都是 O(logn)。堆常见的应用有优先级队列和堆排序。
1. 什么是堆
1.1 堆的定义
堆的严格定义如下,只要满足这两点,它就是一个堆:
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
说明: 和红黑树不同,椎并是一个部分有序队列,尤其要注意以下两点。
- 堆是完全二叉树,因此堆这种数据都是用数组进行存储。
- 对于每个节点的值都大于等于子树中每个节点值的堆,叫作大顶堆。反之则是小顶堆。
1.2 堆的常见操作
堆的常见操作两个,分别是插入元素和删除堆顶元素:
- 堆化(heapify):往堆中插入元素叫做堆化。堆化分为从下往上和从上往下两种堆化方法。
- 删除堆顶元素:我们知道,堆顶元素是最小或最大元素。删除堆顶元素后,需要通过从上往下的堆化,使其重新满足堆的定义。
(1)堆化
我们往一个小顶堆中添加新的结点,分析从下往上是如何进行堆化。当然,你也可以使用从下往上的堆化。
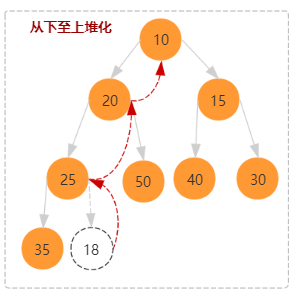
如上图所示,插入结点时从下往上是堆化为两步:
- 将数组最后位置添加一个新的结点,也就是 arr[size] = value。
- 从这个新结点和父结点依次向上比较并交换,直接重新符合堆的定义。其时间复杂度为树的高度,也就是 O(logn)。
private int[] arr;
private int size;
// arr[0] 不存储任何元素,当然你也可以将堆整体向前移动一位
public void add(int value) {
if (size >= capcity) return;
++size;
arr[size] = value;
int i = size;
while (i > 0 && arr[i / 2] > arr[i]) {
swap(arr, i, i / 2);
i = i / 2;
}
}
(2)删除堆顶元素
与插入结点时相反,删除元素时需要从上至下堆化
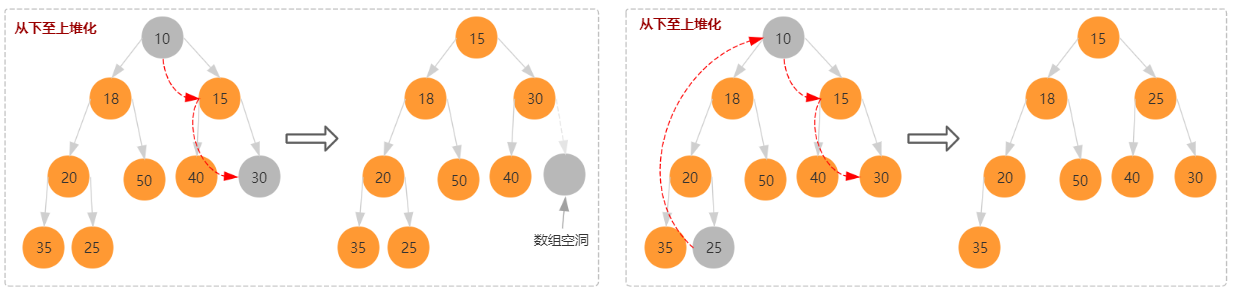
需要注意的是直接和子结点比较并交换位置,可能会出现数组空洞,不符合完全二叉树的定义,如右图所示出现的数据空洞。解决方案如左所示,先将数组最后一位的结点交换到堆顶,然后再从上至下比较交换。
- 将数组最后结点赋值给椎顶结点,也就是 arr[1] = arr[size]。
- 从这个新结点和子结点依次向下比较并交换,直接重新符合堆的定义。其时间复杂度为树的高度,也就是 O(logn)。
public int poll() {
if (size <= 0) return -1;
int value = arr[1];
int i = 1;
arr[i] = arr[size];
arr[size] = 0;
size--;
while (true) {
int minPos = i;
if (size >= 2 * i && arr[minPos] > arr[2 * i]) minPos = 2 * i;
if (size >= 2 * i + 1 && arr[minPos] > arr[2 * i + 1]) minPos = 2 * i + 1;
if (minPos == i) break;
swap(arr, i, minPos);
i = minPos;
}
return value;
}
2. 堆排序
如果我们要堆数据结构实现从小到大的排序,该怎么实现呢?我们知道将数组堆化成大顶堆后,堆顶是最大值,然后我们依次取出堆顶元素,这样取出的元素就是按从大到小的顺序,我们每次取出元素时依次放到数组最后。这样当全部取出后,就实现了从小到大的排序。堆排序分为两步:
- 堆化:将数组原地建成一个堆。
- 排序:依次取出堆顶元素与数组最后一个元素交换位置。
2.1 堆化
原地堆化也有两种思路:
- 从下往上进行堆化。和插入排序一样,将数组分为两部为:已经堆化和未堆化。依次遍历未堆化部为,将其插入到已经堆化部分。
- 从上往下进行堆化。遍历所有的叶子结点,将其与堆顶结点交换后从上往下进行堆化。
// 从下往上堆化
private static void heavify(Integer[] arr) {
for (int i = 1; i < arr.length; i++) {
shiftUp(i, arr);
}
}
// 大顶堆:从下往上堆化
private static void shiftUp(int i, Integer[] arr) {
while (i > 0 && arr[i] > arr[(i - 1) / 2]) {
swap(arr, i, (i - 1) / 2);
i = (i - 1) / 2;
}
}
// 从上往下堆化,对于完全二叉树而言,号子结点起始位置: "arr.length / 2 + 1"
public void heavify(int[] arr) {
for (int i = arr.length / 2; i >= 1; --i) {
// 随机数据的插入和删除,堆的长度会发生变化,需要第二个参数来控制向下堆化的最大位置
shiftDown(i, arr.length, arr[i]);
}
}
// 大顶堆:从上往下堆化
private static void shiftDown(int i, int size, Integer[] arr) {
while (true) {
int maxPos = i;
if (size > 2 * i + 1 && arr[maxPos] < arr[2 * i + 1]) {
maxPos = 2 * i + 1;
}
if (size > 2 * i + 2 && arr[maxPos] < arr[2 * i + 2]) {
maxPos = 2 * i + 2;
}
if (maxPos == i) {
break;
}
swap(arr, i, maxPos);
i = maxPos;
}
}
说明: 最核心的方法是向上堆化 shiftUp 和 向下堆化 shiftDown 这两个方法,可以参考 PriorityQueue 小顶堆的实现。
2.2 排序
排序同样是将数据分为已经排序和未排序部分。其中未排序部分是一个大顶堆,依次从大顶堆中取出最大元素,插入已经排序部分。
public void sort(Integer[] arr) {
heavify(arr);
// 从大顶堆中取出最大元素,依次插入已经排序部分
doSort(arr);
}
private void doSort(Integer[] arr) {
int n = arr.length;
for (int i = 1; i < n; i++) {
swap(arr, 0, n - i);
shiftDown(0, n - i, arr);
}
}
2.3 三大指标
(1)时间复杂度
堆化时间复杂度:O(n)
层数 元素个数 时间复杂度 总时间复杂度
○ 1 1 h-1 h-1
○ ○ 2 2 h-2 2(h-2)
○ ○ ○ ○ 3 n/8 2 n/2^3 * 2
○ ○ ○ ○ ○ ○ ○ ○ 4 n/4 1 n/2^2 * 1
... h n/2 0 0 S = n/2 + 2n/4 + 3n/16 + 4n/32 + 2(h-2) + (h-1) = O(n)
排序时间复杂度:O(nlogn)
如果数据原本就是有序的,堆排序在堆化过程会打乱原先的顺序,再进行排序,因此,即便是完全有序数组的时间复杂度是 O(nlogn)。但对完全逆序的数组,其时间复杂度也是 O(nlogn)。总的来说,堆排序的时间复杂度非常稳定。
(2)空间复杂度
堆排序是原地排序。
(3)稳定性
在堆化的过程中,会出现非相邻元素交换,因此堆排序是非稳定排序。
2.4 堆排序 vs 快速排序
在实际开发中,为什么快速排序要比堆排序性能好?
- 堆排序对 CPU 不友好。快速排序来说局部顺序访问,而堆排序则是逐层访问。 比如,堆排序会依次访问数组下标是 1,2,4,8 的元素,而不是像快速排序那样,局部顺序访问。
- 堆排序算法的数据交换次数要多于快速排序。比如,有序数组建堆后,数据反而变得更无序。
3. 优先级队列
如 Java 中的优先级队列 PriorityQueue 和 PriorityBlockingQueue 就是使用小顶堆实现的。
- 合并有序小文件
- 高性能定时器
- Top N
- 利用堆求中位数
每天用心记录一点点。内容也许不重要,但习惯很重要!
Java数据结构和算法(五)二叉排序树(BST)的更多相关文章
- Java数据结构和算法(五)--希尔排序和快速排序
在前面复习了三个简单排序Java数据结构和算法(三)--三大排序--冒泡.选择.插入排序,属于算法的基础,但是效率是偏低的,所以现在 学习高级排序 插入排序存在的问题: 插入排序在逻辑把数据分为两部分 ...
- Java数据结构和算法(五)——队列
队列.queue,就是现实生活中的排队. 1.简单队列: public class Queqe { private int array[]; private int front; private in ...
- Java数据结构和算法(六)——前缀、中缀、后缀表达式
前面我们介绍了三种数据结构,第一种数组主要用作数据存储,但是后面的两种栈和队列我们说主要作为程序功能实现的辅助工具,其中在介绍栈时我们知道栈可以用来做单词逆序,匹配关键字符等等,那它还有别的什么功能吗 ...
- Java数据结构和算法(十四)——堆
在Java数据结构和算法(五)——队列中我们介绍了优先级队列,优先级队列是一种抽象数据类型(ADT),它提供了删除最大(或最小)关键字值的数据项的方法,插入数据项的方法,优先级队列可以用有序数组来实现 ...
- Java数据结构和算法 - 递归
三角数字 Q: 什么是三角数字? A: 据说一群在毕达哥拉斯领导下工作的古希腊的数学家,发现了在数学序列1,3,6,10,15,21,……中有一种奇特的联系.这个数列中的第N项是由第N-1项加N得到的 ...
- Java数据结构和算法 - 哈希表
Q: 如何快速地存取员工的信息? A: 假设现在要写一个程序,存取一个公司的员工记录,这个小公司大约有1000个员工,每个员工记录需要1024个字节的存储空间,因此整个数据库的大小约为1MB.一般的计 ...
- Java数据结构和算法(一)树
Java数据结构和算法(一)树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 前面讲到的链表.栈和队列都是一对一的线性结构, ...
- Java数据结构和算法(四)--链表
日常开发中,数组和集合使用的很多,而数组的无序插入和删除效率都是偏低的,这点在学习ArrayList源码的时候就知道了,因为需要把要 插入索引后面的所以元素全部后移一位. 而本文会详细讲解链表,可以解 ...
- Java数据结构和算法(七)--AVL树
在上篇博客中,学习了二分搜索树:Java数据结构和算法(六)--二叉树,但是二分搜索树本身存在一个问题: 如果现在插入的数据为1,2,3,4,5,6,这样有序的数据,或者是逆序 这种情况下的二分搜索树 ...
- Java数据结构和算法(六)--二叉树
什么是树? 上面图例就是一个树,用圆代表节点,连接圆的直线代表边.树的顶端总有一个节点,通过它连接第二层的节点,然后第二层连向更下一层的节点,以此递推 ,所以树的顶端小,底部大.和现实中的树是相反的, ...
随机推荐
- HTML+CSS实现页面
使用HTML和CSS实现以下页面: 抽屉首页 个人博客首页 小米官网首页 登录注册页面 一.抽屉首页 1.实现目标:https://dig.chouti.com/ 2.代码: HTML: <!- ...
- 用javac编译servlet类出现问题
本人写了一个关于servlet的webapp,但是在用javac编译的时候,只是单纯的将jsp-api.jar和servlet-api.jar拷贝放在了其目录下面,然后利用命令行 javac XXX. ...
- OpenACC 书上的范例代码(Jacobi 迭代),part 2
▶ 使用Jacobi 迭代求泊松方程的数值解 ● 首次使用 OpenACC 进行加速,使用动态数组,去掉了误差控制 #include <stdio.h> #include <stdl ...
- jpa 一对多and 多对一
配置: <?xml version="1.0" encoding="UTF-8"?> <persistence version="2 ...
- Maven 项目中 添加自己的jar包
mvn install:install-file -Dfile=java-bloomfilter-1.0.jar -DgroupId=com.sina -DartifactId=java-bl ...
- eclipse 乱码
svn乱码: 教你解决Eclipse中SVN比较乱码问题 workspace->utf-8设置后成功! console乱码: 项目右键 : run as configuration 设置com ...
- 双机\RAC\Dataguard的区别
Oracle 双机/RAC/Dataguard的区别 Data Guard 是Oracle的远程复制技术,它有物理和逻辑之分,但是总的来说,它需要在异地有一套独立的系统,这是两套硬件配置可以不同的系统 ...
- visual c++ 中的stdafx.h头文件的作用
stdafx.h VC工程里面经常见到stdafx.h这个头文件,以前也没有特别注意,但是这个文件用不好经常会出错,所以就GOOGLE了一下,总算是弄清楚了... stdafx的英文全称为:Stand ...
- 迷你MVVM框架 avalonjs 学习教程12、数据联动
在许多表单应用,我们经常遇到点击一个复选框(或下拉框)会引发旁边的复选框(或下拉框)发生改变,这种联动效果用avalon来做是非常简单的.在avalon里,存在各种绑定回调与$watch回调,完全满足 ...
- MVC3 发布到IIS 7.5
1.应用程序池采用集成模式(建议),.NET Framework版本为: .NET Framework4.0.30319. 2.确保ASP.NET MVC3已安装好,然后检查站点的处理程序映射,看是否 ...