Spring Data JPA中的动态查询 时间日期
功能:Spring Data JPA中的动态查询 实现日期查询
页面对应的dto类
private String modifiedDate;
//实体类
@LastModifiedDate
protected Calendar modifiedDate;
1 public Predicate toPredicate(Root<Infolink> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
2 query.distinct(true);
3 List<Predicate> pl = new ArrayList<Predicate>();
4 Join<Infolink, Infosort> join = (Join<Infolink, Infosort>) root
5 .join(root.getModel().getList("infosorts", Infosort.class), JoinType.LEFT);
6 for (Map f : filters) {
7 String field = f.get("field").toString().trim();
8 String value = f.get("value").toString().trim();
9 if (value != null && value.length() > 0) {
10 if ("infosortId".equalsIgnoreCase(field)) {
11 pl.add(cb.equal(join.get("id"), value));
12 }
13 if ("infolinkTitle".equalsIgnoreCase(field)) {
14 pl.add(cb.like(root.<String>get(field), "%" + value + "%"));
15 }
16 if ("keyword".equalsIgnoreCase(field)) {
17 pl.add(cb.like(root.<String>get(field), "%" + value + "%"));
18 }
19 if ("summary".equalsIgnoreCase(field)) {
20 pl.add(cb.like(root.<String>get(field), "%" + value + "%"));
21 }
22 if ("user".equalsIgnoreCase(field)) {
23 pl.add(cb.equal(root.<String>get(field), value));
24 }
25 if ("infolinkType".equalsIgnoreCase(field)) {
26 pl.add(cb.equal(root.<String>get(field), value));
27 }
28 if ("infolinkState".equalsIgnoreCase(field)) {
29 pl.add(cb.equal(root.<String>get(field), value));
30 }
31 if ("id".equalsIgnoreCase(field)) {
32 pl.add(cb.equal(root.<String>get(field), value));
33 }
34 // 日期查询
35 if ("modifiedDate".equalsIgnoreCase(field)) {
36 // 处理时间
37 SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
38 Date startDate;
39 Date endDate;
40 try {
41 startDate = format.parse(value);
42 } catch (ParseException e) {
43 startDate = new Date(946656000000L);// 2000 01 01
44 }
45 endDate = startDate;
46 Calendar calendar = Calendar.getInstance();
47 calendar.setTime(endDate);
48 calendar.add(Calendar.DATE, 1);
49 endDate = calendar.getTime();
50 calendar = null;
51 pl.add(cb.between(root.<Date>get(field), startDate, endDate));
52 }
53 }
54 }
55 pl.add(cb.equal(root.<Integer>get("flag"), 1));
56 return cb.and(pl.toArray(new Predicate[0]));
57 }
效果展示:
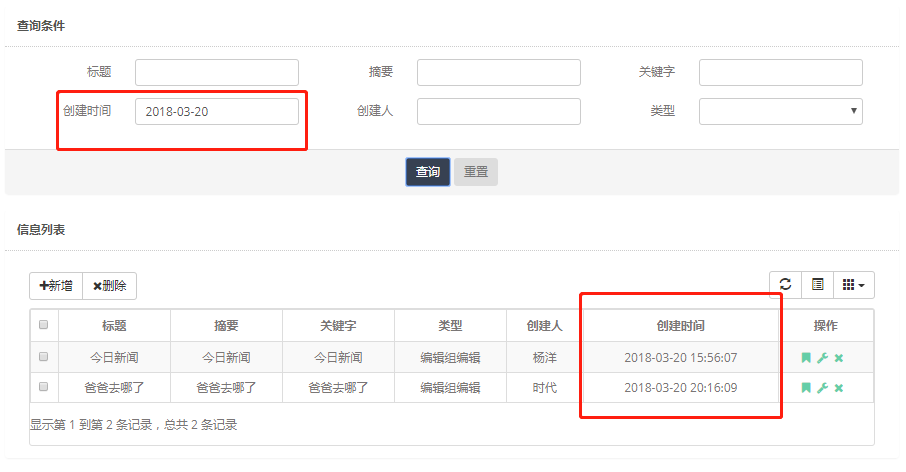
================================多条件查询=================================================
二 有多个条件,我们就可以创建一个Predicate集合,最后用CriteriaBuilder的and和or方法进行组合,得到最后的Predicate对象。
root参数是我们用来对应实体的信息的。criteriaBuilder可以制作查询信息。
CriteriaBuilder对象里有很多条件方法,比如制定条件:某条数据的创建日期小于今天。
criteriaBuilder.lessThan(root.get("createDate"), today) //该方法返回的对象类型是Predicate。正是toPredicate需要返回的值。
创建一个Predicate集合,最后用CriteriaBuilder的and和or方法进行组合,得到最后的Predicate对象。 //and到一起的话所有条件就是且关系,or就是或关系了。
public List<WeChatGzUserInfoEntity> findByCondition(Date minDate, Date maxDate, String nickname){
List<WeChatGzUserInfoEntity> resultList = null;
Specification querySpecifi = new Specification<WeChatGzUserInfoEntity>() {
@Override
public Predicate toPredicate(Root<WeChatGzUserInfoEntity> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
List<Predicate> predicates = new ArrayList<>();
if(null != minDate){
predicates.add(criteriaBuilder.greaterThan(root.get("subscribeTime"), minDate));
}
if(null != maxDate){
predicates.add(criteriaBuilder.lessThan(root.get("subscribeTime"), maxDate));
}
if(null != nickname){
predicates.add(criteriaBuilder.like(root.get("nickname"), "%"+nickname+"%"));
}
return criteriaBuilder.and(predicates.toArray(new Predicate[predicates.size()]));
}
};
resultList = this.weChatGzUserInfoRepository.findAll(querySpecifi);
return resultList;
}
相关链接:
1. Spring Data JPA,一种动态条件查询的写法
www.cnblogs.com/derry9005/p/6282571.html
2. Spring data jpa 复杂动态查询方式总结
https://blog.csdn.net/qq_30054997/article/details/79420141
3. 带有条件的查询后分页和不带条件查询后分页实现
https://blog.csdn.net/lihuapiao/article/details/48782843
Spring Data JPA中的动态查询 时间日期的更多相关文章
- Spring Data JPA 的 Specifications动态查询
主要的结构: 有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在Spring Data JPA中可以通过JpaSpecificationExecutor接口查询. ...
- Spring data jpa 实现简单动态查询的通用Specification方法
本篇前提: SpringBoot中使用Spring Data Jpa 实现简单的动态查询的两种方法 这篇文章中的第二种方法 实现Specification 这块的方法 只适用于一个对象针对某一个固定字 ...
- Spring data JPA中使用Specifications动态构建查询
有时我们在查询某个实体的时候,给定的条件是不固定的,这是我们就需要动态 构建相应的查询语句,在JPA2.0中我们可以通过Criteria接口查询,JPA criteria查询.相比JPQL,其优势是类 ...
- 【hql】spring data jpa中 @Query使用hql查询 问题
spring data jpa中 @Query使用hql查询 问题 使用hql查询, 1.from后面跟的是实体类 不是数据表名 2.字段应该用实体类中的字段 而不是数据表中的属性 实体如下 hql使 ...
- spring data jpa使用原生sql查询
spring data jpa使用原生sql查询 @Repository public interface AjDao extends JpaRepository<Aj,String> { ...
- 如何在Spring Data JPA中引入Querydsl
一.环境说明 基础框架采用Spring Boot.Spring Data JPA.Hibernate.在动态查询中,有一种方式是采用Querydsl的方式. 二.具体配置 1.在pom.xml中,引入 ...
- spring data jpa实现多条件查询(分页和不分页)
目前的spring data jpa已经帮我们干了CRUD的大部分活了,但如果有些活它干不了(CrudRepository接口中没定义),那么只能由我们自己干了.这里要说的就是在它的框架里,如何实现自 ...
- Spring MVC和Spring Data JPA之按条件查询和分页(kkpaper分页组件)
推荐视频:尚硅谷Spring Data JPA视频教程,一学就会,百度一下就有, 后台代码:在DAO层继承Spring Data JPA的PagingAndSortingRepository接口实现的 ...
- spring data jpa 利用@Query进行查询
参照https://blog.csdn.net/yingxiake/article/details/51016234#reply https://blog.csdn.net/choushi300/ar ...
随机推荐
- C# 读取word2003 并且显示在界面上的方法
1.新建一个windows窗体程序 2. 引入包WinWordControl.dll 3.添加引用 4.引入组件WinWordControl组件 5.主界面上加入按钮 ,opendialog, win ...
- vs2015多行注释与取消多行注释
注释: 先CTRL+K,然后CTRL+C 取消注释: 先CTRL+K,然后CTRL+U
- 雷林鹏分享:C# 类型转换
C# 类型转换 类型转换从根本上说是类型铸造,或者说是把数据从一种类型转换为另一种类型.在 C# 中,类型铸造有两种形式: 隐式类型转换 - 这些转换是 C# 默认的以安全方式进行的转换.例如,从小的 ...
- 雷林鹏分享:C# 判断
C# 判断 判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的). 下面是大多数编程语言中典型的判断结构的一般形式: 判断语句 C ...
- WCF开发框架形成之旅---WCF的几种寄宿方式
WCF开发框架形成之旅---WCF的几种寄宿方式 WCF寄宿方式是一种非常灵活的操作,可以在IIS服务.Windows服务.Winform程序.控制台程序中进行寄宿,从而实现WCF服务的运行,为调用者 ...
- 11月26日11月26日,周日在家practice.基本了解了layouts and Rending (guides); gem font-awesome-rails的实例用法;建立路径route, member..do的实际例子
http://fontawesome.io/examples/ content_tag(:i,"", class:"fa fa-lock fa-spin fa-lg fa ...
- Fiddler拦截http请求修改数据
1.拦截http请求 使用Fiddler进行HTTP断点调试是fiddler一强大和实用的工具之一.通过设置断点,Fiddler可以做到: ①修改HTTP请求头信息.例如修改请求头的UA,Cookie ...
- 解决Requests中文乱码【有用】,读取htm文件 读取txt文件报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8 in position 0
打开这个网址https://blog.csdn.net/chaowanghn/article/details/54889835 python在open读取txt文件时,出现UnicodeDecodeE ...
- 模拟数据库丢失undo表空间
数据库无事务情况下丢失undo表空间数据文件 1. 查看当前undo表空间,并删除物理undo文件 SYS@userdata>show parameter undo_tablespace; NA ...
- java.lang.Exception: DEBUG STACK TRACE for PoolBackedDataSource.close().
java.lang.Exception: DEBUG STACK TRACE for PoolBackedDataSource.close(). java.lang.Exception: DEBUG ...