Centos下基于Hadoop安装Spark(分布式)
前提
Hadoop可成功在分布式系统下启动
下载scala 链接是https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
Master和其他子主机下
wget https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
解压
tar -zxvf scala-2.12.7.tgz
将解压后的文件复制到自己的文件路径
cp -r ./scala-2.12.7 /usr/scala
配置环境变量
vim /etc/profile
添加
export SCALA_HOME=/usr/scala
export PATH=$PATH:$SCALA_HOME/bin
执行
. /etc/profile
使之生效,后测试
scala -version
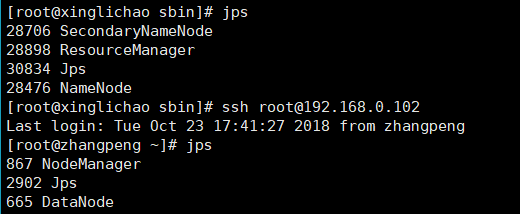
[root@xinglichao sbin]# scala -version
Scala code runner version 2.12.7 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
表示成功
下载Spark 链接是http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz(还有很多镜像可供使用)

在Master主机上使用wget下载
wget http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
同scala一样,要执行解压,复制到指定文件夹
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
cp ./spark-2.3.2-bin-hadoop2.7/* /usr/spark/
进入/usr/spark/conf
配置spark-env.sh和slaves
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vim spark-env.sh
添加配置
#java路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/jre
#scala路径
export SCALA_HOME=/usr/scala
#hadoop路径
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.5
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.5/etc/hadoop
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=xinglichao
#指定maaster提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定masster节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点的端口(可选配置)
export SPARK_WORKER_PORT=7078
#每个worker从节点的wwebui端口(可选配置)
export SPARK_WORKER_WEBUI_PORT=8081
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=1
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
vim slaves
子主机的主机名或者ip
将spark分发到子节点主机
scp /usr/spark/* root@192.168.0.102:/usr/spark/
在Master上启动spark
[root@xinglichao sbin]# pwd
/usr/spark/sbin
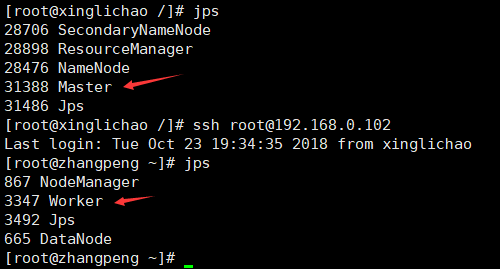
[root@xinglichao sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-xinglichao.out
zhangpeng: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhangpeng.out
[root@xinglichao sbin]#
jps查看进程
本节完......
Centos下基于Hadoop安装Spark(分布式)的更多相关文章
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备 1. 准备4台机器.或虚拟机 4台机器的名称和IP对应如下 master:192.168.199.128 slave1:192.168.199.129 slave2:192.168.19 ...
- CentOS下SNMP的安装与使用
CentOS下SNMP的安装与使用 导读 简单网络管理协议(SNMP),由一组网络管理的标准组成,包含一个应用层协议(application layer protocol).数据库模型(datab ...
- CentOS下通过yum安装svn及配置
CentOS下通过yum安装svn及配置 1.环境centos5.5 2.安装svnyum -y install subversion 3.配置 建立版本库目录mkdir /www/svndata s ...
- centos 下查找软件安装在哪里的命令
linux centos 下查找软件所安装的目录在哪里 1. 如果是rpm安装的可以:rpm -ql linux(1)package-name 具体你可以man rpm 2. 可以在根目录上直接fin ...
- CentOS下源码安装Apache2.4+PHP5.4+MySQL5.5
一.准备(把所有的源文件放在‘/home/yuanjun’目录下) apr http://mirror.bjtu.edu.cn/apache/apr/apr-1.4.6.tar.gz apr-util ...
- CentOS下Eclipse的安装教程
CentOS下Eclipse的安装教程 据了解,在Linux下的Java开发很多时候都比较喜欢使用vim + 插件,反而很少使用Eclipse,但是我是第一次使用Linux来进行Java编程,就什么都 ...
- mac与centos下redis的安装与配置
前言 最近在用redis,下面简单写一下mac和centos下redis的安装与配置方法. 安装 mac下面 安装命令:brew intall redis 运行命令:brew services sta ...
- CentOS下Redis的安装(转)
目录 CentOS下Redis的安装 前言 下载安装包 解压安装包并安装 启动和停止Redis 启动Redis 停止Redis 参考资料 CentOS下Redis的安装 前言 安装Redis需要知道自 ...
随机推荐
- JavaScript学习 - 基础(六) - DOM基础操作
DOM: DOM定义了访问HTML 和XML 文档的标准:1.核心DOM 针对结构化文档的标准模型2.XMK DOM 针对XML文档的标准模型3.HTML DOM 针对HTML文档的标准模型 DOM节 ...
- vlc-android 的编译过程
参考官方文档:https://wiki.videolan.org/AndroidCompile#Get_VLC_Source 值得注意的的地方: 1.切记安装以下工具 sudo apt-get ins ...
- CMake 示例
1.需求 [1].使用第三方动/静太库 [2].本身代码部分编译为动/静态库 [3]多项目管理 原文转自:http://blog.csdn.net/shuyong1999/article/detail ...
- JS如何防止事件冒泡
<div style="height:30px;line-height:30px;background:#FF0;text-align:center;" id="z ...
- HDFS安全模式
用户可以通过dfsadmin -safemode value 来操作安全模式,参数value的说明如下: enter - 进入安全模式 leave - 强制NameNode离开安全模式 get - 返 ...
- v4l2功能列表大全【转】
一,功能参考 目录 V4L2 close() - 关闭一个V4L2设备 V4L2 ioctl() - 创建的V4L2设备 ioctl VIDIOC_CROPCAP - 视频裁剪和缩放功能信息 ioct ...
- mysql系列十三、mysql中replace into和duplicate key的使用区
一.创建测试表 1.创建唯一索引"b" CREATE TABLE `test2` ( `id` int(10) NOT NULL AUTO_INCREMENT, `a` varch ...
- 【bzoj2653】【middle】【主席树+二分答案】
Description 一个长度为 n 的序列 a ,设其排过序之后为 b ,其中位数定义为 b[n/2] ,其中 a,b 从 0 开始标号 , 除法取下整. 给你一个长度为 n 的序列 s .回答 ...
- Zabbix Agent active批量调整客户端为主动模式监控
Zabbix Agent active批量调整客户端为主动模式监控 zabbix_server端当主机数量过多的时候,由Server端去收集数据,Zabbix会出现严重的性能问题,主要表现如下: 1. ...
- python-pandas 高级功能(通过学习kaggle案例总结)
方法.iterrows()遍历循环df中的元素. for index,row in df.iterrows(): pass 更改df一个元素中的变量值. data1.set_value(index,' ...