Centos下基于Hadoop安装Spark(分布式)
前提
Hadoop可成功在分布式系统下启动
下载scala 链接是https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
Master和其他子主机下
wget https://downloads.lightbend.com/scala/2.12.7/scala-2.12.7.tgz
解压
tar -zxvf scala-2.12.7.tgz
将解压后的文件复制到自己的文件路径
cp -r ./scala-2.12.7 /usr/scala
配置环境变量
vim /etc/profile
添加
export SCALA_HOME=/usr/scala
export PATH=$PATH:$SCALA_HOME/bin
执行
. /etc/profile
使之生效,后测试
scala -version
[root@xinglichao sbin]# scala -version
Scala code runner version 2.12.7 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
表示成功
下载Spark 链接是http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz(还有很多镜像可供使用)

在Master主机上使用wget下载
wget http://mirrors.shu.edu.cn/apache/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz
同scala一样,要执行解压,复制到指定文件夹
tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz
cp ./spark-2.3.2-bin-hadoop2.7/* /usr/spark/
进入/usr/spark/conf
配置spark-env.sh和slaves
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vim spark-env.sh
添加配置
#java路径
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64/jre
#scala路径
export SCALA_HOME=/usr/scala
#hadoop路径
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.5
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.5/etc/hadoop
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=xinglichao
#指定maaster提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定masster节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点的端口(可选配置)
export SPARK_WORKER_PORT=7078
#每个worker从节点的wwebui端口(可选配置)
export SPARK_WORKER_WEBUI_PORT=8081
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=1
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
vim slaves
子主机的主机名或者ip
将spark分发到子节点主机
scp /usr/spark/* root@192.168.0.102:/usr/spark/
在Master上启动spark
[root@xinglichao sbin]# pwd
/usr/spark/sbin
[root@xinglichao sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-xinglichao.out
zhangpeng: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-zhangpeng.out
[root@xinglichao sbin]#
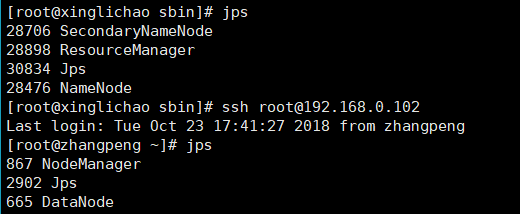
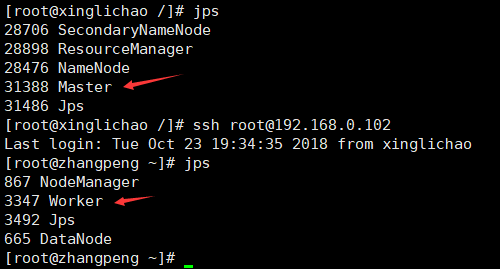
jps查看进程
本节完......
Centos下基于Hadoop安装Spark(分布式)的更多相关文章
- Ubuntu下基于Saprk安装Zeppelin
前言 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析,即一个Web笔记形式的交互式数据查询分析工具,可以在线用scal ...
- hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备 1. 准备4台机器.或虚拟机 4台机器的名称和IP对应如下 master:192.168.199.128 slave1:192.168.199.129 slave2:192.168.19 ...
- CentOS下SNMP的安装与使用
CentOS下SNMP的安装与使用 导读 简单网络管理协议(SNMP),由一组网络管理的标准组成,包含一个应用层协议(application layer protocol).数据库模型(datab ...
- CentOS下通过yum安装svn及配置
CentOS下通过yum安装svn及配置 1.环境centos5.5 2.安装svnyum -y install subversion 3.配置 建立版本库目录mkdir /www/svndata s ...
- centos 下查找软件安装在哪里的命令
linux centos 下查找软件所安装的目录在哪里 1. 如果是rpm安装的可以:rpm -ql linux(1)package-name 具体你可以man rpm 2. 可以在根目录上直接fin ...
- CentOS下源码安装Apache2.4+PHP5.4+MySQL5.5
一.准备(把所有的源文件放在‘/home/yuanjun’目录下) apr http://mirror.bjtu.edu.cn/apache/apr/apr-1.4.6.tar.gz apr-util ...
- CentOS下Eclipse的安装教程
CentOS下Eclipse的安装教程 据了解,在Linux下的Java开发很多时候都比较喜欢使用vim + 插件,反而很少使用Eclipse,但是我是第一次使用Linux来进行Java编程,就什么都 ...
- mac与centos下redis的安装与配置
前言 最近在用redis,下面简单写一下mac和centos下redis的安装与配置方法. 安装 mac下面 安装命令:brew intall redis 运行命令:brew services sta ...
- CentOS下Redis的安装(转)
目录 CentOS下Redis的安装 前言 下载安装包 解压安装包并安装 启动和停止Redis 启动Redis 停止Redis 参考资料 CentOS下Redis的安装 前言 安装Redis需要知道自 ...
随机推荐
- 拆分窗口QSplitter
拆分窗口中可以添加许多子控件,各个子控件通过拆分线相互分隔开来,拖动该拆分线可以随意改变子控件大小 import sys from PyQt5.QtCore import Qt from PyQt5. ...
- luogu P1081 开车旅行
传送门 这题的暴力做法显然是照题意模拟,从每个点出发暴力跳.而这个暴跳显然是可以倍增优化的,就是预处理出从每个点,(一开始是A)往后跳\(2^k\)步,能到哪里,以及\(A\)和\(B\)的路程,然后 ...
- luogu P2303 [SDOi2012]Longge的问题
传送门 \[\sum_{i=1}^{n}\gcd(i,n)\] 考虑枚举所有可能的gcd,可以发现这一定是\(n\)的约数,当\(\gcd(i,n)=x\)时,\(gcd(\frac{i}{x},\f ...
- java程序运存扩容
线上程序随着业务增多,运行的越来越慢,初步判定是因为内存分配的太小导致频繁的进行GC和OOM,于是着手增加内存上限. 增加内存上限都知道是修改java启动的opt,因为服务容器是tomcat 首先是在 ...
- Mybatis进阶学习笔记——动态代理方式开发Dao接口、Dao层(推荐第二种)
1.原始方法开发Dao Dao接口 package cn.sm1234.dao; import java.util.List; import cn.sm1234.domain.Customer; pu ...
- ubuntu 上下左右键变成ABCD
1.在ubuntu终端环境出现: 这表示你正在insert mode.... 按esc,回到command mode,上下左右就回复到正常的方向键功能了 2.可能写的程序是在insert mode(r ...
- Java编程:悲观锁、乐观锁的区别及使用场景
定义: 悲观锁(Pessimistic Lock): 每次获取数据的时候,都会担心数据被修改,所以每次获取数据的时候都会进行加锁,确保在自己使用的过程中数据不会被别人修改,使用完成后进行数据解锁.由于 ...
- Docker镜像命令
①docker images [Options] 用途:列出本地主机上的镜像 Options说明: -a:列出本地所有的镜像(含中间映像层) -q:只显示镜像ID --digests:显示镜像的摘要信 ...
- c++动态库封装及调用(3、windows下动态库调用)
1.DLL的隐式调用 隐式链接采用静态加载的方式,比较简单,需要.h..lib..dll三件套.新建“控制台应用程序”或“空项目”.配置如下: 项目->属性->配置属性->VC++ ...
- 【逆向工具】使用x64dbg+spy去除WinRAR5.40(64位)广告弹框
1 学习目标 WinRAR5.40(64位)的弹框广告去除,由于我的系统为x64版本,所以安装了WinRAR(x64)版本. OD无法调试64位的程序,可以让我熟悉x64dbg进行调试的界面. 其次是 ...