文本tfidf
文本分类
tf:词的频率
idf:逆文档频率



代码实例:
# tf idf
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cutword():
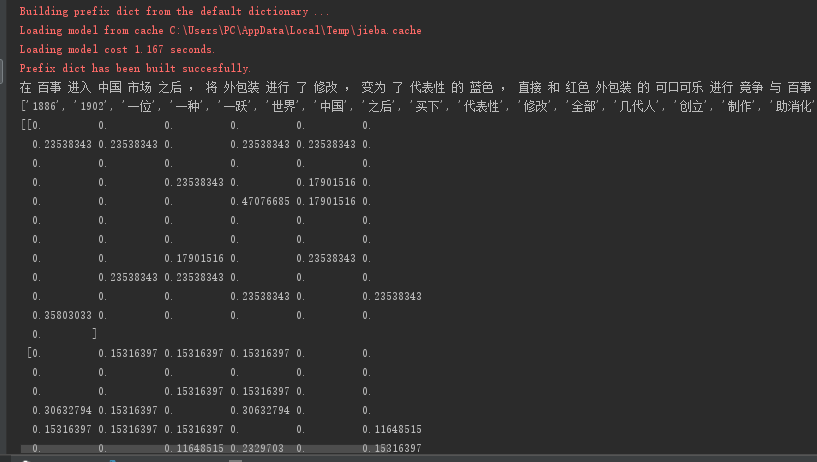
con1 = jieba.cut("在百事进入中国市场之后,将外包装进行了修改,变为了代表性的蓝色,直接和红色外包装的可口可乐进行竞争与")
con2 = jieba.cut("百事则成立于1902年,由百事可乐的发明人成立,百事可乐的发明人同样是一位药剂师,据说最开始是因为他在配制一种助消化的药剂时无意中发现某种口味深受顾客喜爱,他根据这种口味制作了碳酸饮料,也就成为了后来的百事可乐。")
con3 = jieba.cut("可口可乐公司成立1886年,由阿萨坎德勒创立,他从发明可口可乐之人约翰彭伯顿手中买下了全部的销售生产权,并开始大范围的在市场进行推广,他创立了可口可乐公司,也被称之为“可口可乐之父”,随后经过了几代人的发展,可口可乐公司也一跃成为了世界著名的饮料生产商。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
#把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3 def tfidfvec():
'''
中文特征值化
:return:None
'''
c1, c2, c3 =cutword()
print(c1, c2, c3)
cv = TfidfVectorizer()
data = cv.fit_transform([c1, c2, c3])
print(cv.get_feature_names()) # 获取特征值名称
# print(data)
print(data.toarray()) # sparse矩阵转换为数组形式
return None if __name__ == "__main__":
tfidfvec()
运行结果:
文本tfidf的更多相关文章
- 【ZH奶酪】如何用sklearn计算中文文本TF-IDF?
1. 什么是TF-IDF tf-idf(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术.tf-idf是一种统计方法 ...
- [python] 使用scikit-learn工具计算文本TF-IDF值
在文本聚类.文本分类或者比较两个文档相似程度过程中,可能会涉及到TF-IDF值的计算.这里主要讲述基于Python的机器学习模块和开源工具:scikit-learn. 希望文章对你有所帮 ...
- 什么是机器学习的特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
2.特征工程 2.1 数据集 2.1.1 可用数据集 Kaggle网址:https://www.kaggle.com/datasets UCI数据集网址: http://archive.ics.uci ...
- (6)文本挖掘(三)——文本特征TFIDF权重计算及文本向量空间VSM表示
建立文本数据数学描写叙述的过程分为三个步骤:文本预处理.建立向量空间模型和优化文本向量. 文本预处理主要採用分词.停用词过滤等技术将原始的文本字符串转化为词条串或者特点的符号串.文本预处理之后,每个文 ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 文本离散表示(三):TF-IDF结合n-gram进行关键词提取和文本相似度分析
这是文本离散表示的第二篇实战文章,要做的是运用TF-IDF算法结合n-gram,求几篇文档的TF-IDF矩阵,然后提取出各篇文档的关键词,并计算各篇文档之间的余弦距离,分析其相似度. TF-IDF与n ...
随机推荐
- vue/cli 3.0 font-size随屏幕大小变化而变化 rem设置
在安装cube-ui框架时 安装成功后在[E:\WWW\xxx\node_modules\vue-cli-plugin-cube-ui\generator\rem\index.js]修改remUnit ...
- abap特性
1:实例成员是属于某一个对象的,静态成员属于整个类. 2:abap类中,可以定义三种不同类型的成员,分布是属性(如data),方法(method),事件(event). 3: abap中定义静态属性的 ...
- DL中epoch、batch等的意义【转载】
转自:深度学习中 number of training epochs 中的 epoch到底指什么? - 知乎 https://www.zhihu.com/question/43673341 1. (1 ...
- 2018-2019-1 20189221《Linux内核原理与分析》第一周作业
Linux内核原理与分析 - 第一周作业 实验1 Linux系统简介 Linux历史 1991 年 10 月,Linus Torvalds想在自己的电脑上运行UNIX,可是 UNIX 的商业版本非常昂 ...
- componentsSeparatedByString 的注意事项
componentsSeparatedByString 两种情景 1. 没有分割符也生成一个数组,元素就是整个字符串本身,那你就需要判断“”这种字符串. 2. 分割的元素如果是相同的字符串,指向的是同 ...
- Adobe Acrobat 9 Pro序列号
其实只删除c:\Program Files\Common Files\Adobe\Adobe PCD\cache目录下的cache.db文件也是可以的,然后重新打开Adobe ,输入序列号1118-4 ...
- 一个简单的MapReduce示例(多个MapReduce任务处理)
一.需求 有一个列表,只有两列:id.pro,记录了id与pro的对应关系,但是在同一个id下,pro有可能是重复的. 现在需要写一个程序,统计一下每个id下有多少个不重复的pro. 为了写一个完整的 ...
- Elasticsearch5.x创建索引(Java)
索引创建代码使用官方给的示例代码,我把它在java项目里实现了一遍. 官方示例 1.创建索引 /** * Java创建Index */ public void CreateIndex() { int ...
- conda常用命令
1. conda基本命令 检查Anaconda是否成功安装 conda --version 检测目前安装了哪些环境 conda info --envs 检查目前有哪些版本的python可以安装: co ...
- ubuntu16.4菜单栏不见,终端不见解决方法
1.ctrl+alt+f1进入命令行 2. sudo apt-get install gnome-terminal 3.sudo apt-get install unity 4.setsid unit ...