Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用
一、Mycat和Sharding-jdbc的区别
1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
2)使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码
Mycat(proxy中间件层):
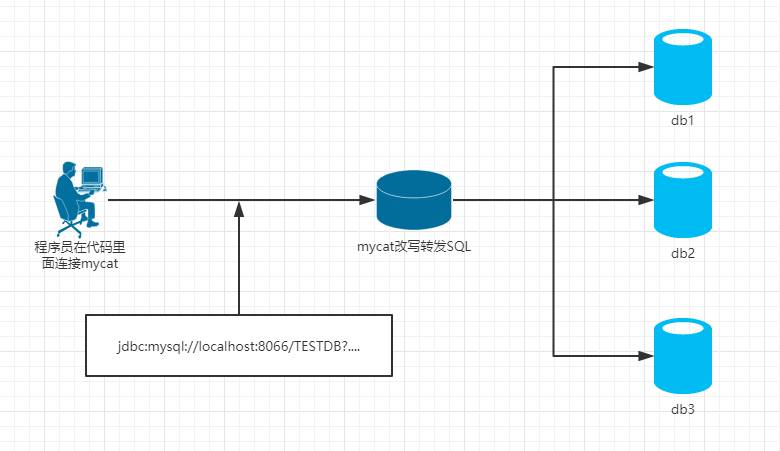
Sharding-jdbc(TDDL为代表的应用层):
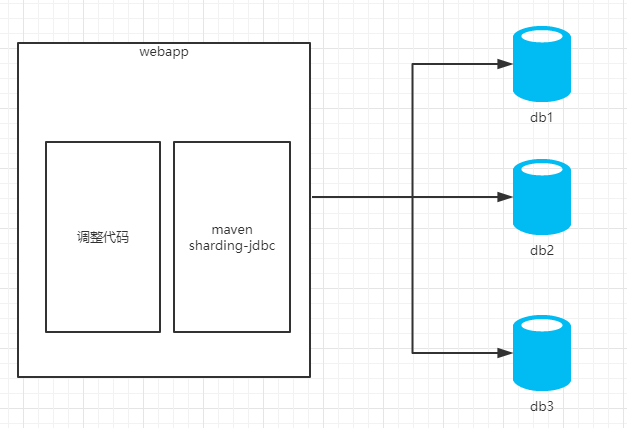
二、Mycat分片join
在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个:
1.)分布式全局唯一id
2.)分片规则和策略
3.)跨分片技术问题
4.)跨分片事物问题
下面我们来看一下Mycat是如何解决跨分片技术问题——分片join的
1. 使用全局表方式解决跨分片join问题
1.1 先在server.xml里面全局表一致性检测
<property name="useGlobleTableCheck">1</property> <!-- 1为开启全局表一致性检测、0为关闭 -->
1.2 在schema.xml里面配置全局表
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
全局表说明:
1)全局表的插入、更新操作会实时在所有节点上执行,保持各个分片数据的一致性
2)全局表的查询操作只从一个节点上获取
3)全局表可以跟任何一个表进行join操作
2. 使用Share Join方式解决跨分片join问题
Share Join是一个简单的跨分片join,基于HBT(Human Brain Tech)的方式实现。
原理:解析SQL语句,拆分成单表的SQL语句执行,然后把各个节点的数据汇集。
示例:
/*!mycat:catlet=io.mycat.catlets.ShareJoin*/select * from employee a, employee_detail b where a.id = b.id;
说明:目前只支持两张分片表的Join,如果要支持多张表需要自己改造程序代码或者改造Mycat的源代码
对应Mycat源码:
io.mycat.catlets.ShareJoin
io.mycat.catlets.Catlet
public class ShareJoin implements Catlet
3. 使用ER Join方式解决跨分片join问题
ER表也叫父子表,子表存储在哪个分片上依赖于父表的存储位置,并且和父表存储同一个分片上,即子表的记录与所关联的父表记录存放在同一个数据分片上,从而解决跨库join的问题
在schema.xml里面的配置
<table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" />
</table>
说明:
childTable:标签用来声明子表:
joinKey:声明子表的那个字段和父表关联
parentKey:声明父表的关联主键
primaryKey:父表自身的主键
三、Mycat分页中的坑
Mycat分页的大坑一定要注意:
在对应的分片上去查询分页数据的时候是从第一条记录开始扫描,然后再取出对应的分页数据,如
SELECT * FROM customer ORDER BY id LIMIT 1000100, 100;
这个sql语句被Mycat转化后
1 -> dn1{SELECT * FROM customer ORDER BY id LIMIT 0, 1000100}
2 -> dn2{SELECT * FROM customer ORDER BY id LIMIT 0, 1000100}
所以要在Mycat的server.xm里面开启使用非堆内存。否则内存会爆掉
<property name="useOffHeapForMerge">1</property>
优化:
1)先查出id
SELECT id FROM customer ORDER BY id LIMIT 1000100, 100;
这个sql语句被mycat转化后
1 -> dn1{SELECT id FROM customer ORDER BY id LIMIT 0, 1000100}
2 -> dn2{SELECT id FROM customer ORDER BY id LIMIT 0, 1000100}
2) 拿到所有的id以后再取获取需要的数据
SELECT * FROM customer where id in(1,2,3....);
这个sql语句被mycat转化后
1 -> dn1{SELECT * FROM customer where id in(1,2,3....);}
2 -> dn2{SELECT * FROM customer where id in(1,2,3....);}
四、Mycat注解
1. Mycat不支持的SQL语句:
1) 某些SQL语法,如insert into......select.....
2) 跨库关联查询
3)存储过程创建
4)存储过程调用
所以Mycat提供Mycat注解来解决上面这些不支持的SQL语句
Mycat的解决办法:Mycat注解
语法:
/*!mycat:sql=Mycat注解SQL语句*/真正执行的SQL !号方式
/*#mycat:sql=Mycat注解SQL语句*/真正执行的SQL #号方式
/**mycat:sql=Mycat注解SQL语句*/真正执行的SQL *号方式
原理:
使用mycat不支持的SQL替换mycat支持的SQL,运行Mycat不支持的SQL

Mycat注解规范:
1) 注解SQL使用select语句,不允许使用delete/update/insert等语句;虽然delete/update/insert等语句也能用在注解中,但这些语句在Sql处理中有额外的逻辑判断,从性能考虑,请使用select语句。
2) 注解SQL禁用表关联语句。
3) 注解SQL尽量用最简单的SQL语句,如select id from tab_a where id=’10000’(如果必要,最好能在注解中指定分片)
4) 无论是原始SQL 还是注解SQL,禁止DDL语句
5) 能不用注解的尽量不用
2. Mycat注解解决不支持insert into......select.....
/*!mycat:sql=select 1*/insert into travelrecord(id,user_id,traveldate,fee,days) select 3,'Tom','',100,8;
3. Mycat注解创建表
/*!mycat:sql=select 1 from test */create table test2(id int);
4. Mycat注解创建存储过程
/*!mycat:sql=select 1 from test */create procedure 'test_proc()' begin end;
5. Mycat注解调用存储过程
/*!mycat:sql=select * from user where id=1 */call test_proc();
6. Mycat注解读写分离数据源选择
/*!mycat:db_type=master */select * from travelrecord;(强制走主库)
/*!mycat:db_type=slave */select * from travelrecord;(强制走从库)
五、Catlet使用
通过Catlet支持跨分片复杂SQL实现以及存储过程支持等等
使用方式:通过mycat注解方式来执行
1. 跨分片联合查询注解支持
/*!mycat:catlet=io.mycat.catlets.ShareJoin */select o.id,u.* from order o,user u where o.user_id=u.id;
2. 批量插入与ID自增长结合的支持
/*!mycat:catlet=io.mycat.route.sequence.BatchInsertSequence */insert into user(name) values('Tom'),('Cat'),('Alan');
Mysql系列八:Mycat和Sharding-jdbc的区别、Mycat分片join、Mycat分页中的坑、Mycat注解、Catlet使用的更多相关文章
- 无法复现的“慢”SQL《死磕MySQL系列 八》
系列文章 四.S 锁与 X 锁的爱恨情仇<死磕MySQL系列 四> 五.如何选择普通索引和唯一索引<死磕MySQL系列 五> 六.五分钟,让你明白MySQL是怎么选择索引< ...
- mysql系列八、mysql数据库优化、慢查询优化、执行计划分析
mysql的性能优化无法一蹴而就,必须一步一步慢慢来,从各个方面进行优化,最终性能就会有大的提升. 一.介绍 对mysql优化是一个综合性的技术,主要包括 表的设计合理化(符合3NF) 添加适当索引( ...
- MySQL系列(八)--数据库分库分表
在互联网公司或者一些并发量比较大的项目,虽然有各种项目架构设计.NoSQL.MQ.ES等解决比较高的并发访问,但是对于数据库来说,压力 还是太大,这时候即使数据库架构.表结构.索引等都设计的很好了,但 ...
- MySQL系列:utf8_bin和utf8_general_ci编码的区别
MySQL中存在多种格式的utf8编码,其中最常见的两种为: utf8_bin utf8_general_ci utf8_bin将字符串中的每一个字符用二进制数据存储,区分大小写;utf8_gener ...
- 什么?还在用delete删除数据《死磕MySQL系列 九》
系列文章 五.如何选择普通索引和唯一索引<死磕MySQL系列 五> 六.五分钟,让你明白MySQL是怎么选择索引<死磕MySQL系列 六> 七.字符串可以这样加索引,你知吗?& ...
- MySQL统计总数就用count(*),别花里胡哨的《死磕MySQL系列 十》
有一个问题是这样的统计数据总数用count(*).count(主键ID).count(字段).count(1)那个效率高. 先说结论,不用那么花里胡哨遇到统计总数全部使用count(*). 但是有很多 ...
- 为什么MySQL字符串不加引号索引失效?《死磕MySQL系列 十一》
群里一个小伙伴在问为什么MySQL字符串不加单引号会导致索引失效,这个问题估计很多人都知道答案.没错,是因为MySQL内部进行了隐式转换. 本期文章就聊聊什么是隐式转换,为什么会发生隐式转换. 系列文 ...
- 打开order by的大门,一探究竟《死磕MySQL系列 十二》
在日常开发工作中,你一定会经常遇到要根据指定字段进行排序的需求. 这时,你的SQL语句类似这样. select id,phone,code from evt_sms where phone like ...
- C语言高速入门系列(八)
C语言高速入门系列(八) C语言位运算与文件 本章引言: 在不知不觉中我们的C高速入门系列已经慢慢地接近尾声了,而在这一节中,我们会对 C语言中的位运算和文件进行解析,相信这两章对于一些人来说是陌生的 ...
随机推荐
- [USACO11FEB]Generic Cow Protests
思路: 动态规划.首先处理出这些数的前缀和$a$,$f_i$记录从第$1$位到第$i$位的最大分组数量.DP方程为:$f_i=max(f_i,f_j+1)$,其中$j$满足$a_i-a_j≥0$. # ...
- memcached 一致性哈希算法
本文转载自:http://blog.csdn.net/kongqz/article/details/6695417 一.概述 1.我们的memcache客户端使用了一致性hash算法ketama进行数 ...
- JavaScript原型之路
简介 最近我在学习Frontend Masters 上的高级JavaScript系列教程,Kyle 带来了他的“OLOO”(对象链接其他对象)概念.这让我想起了Keith Peters 几年前发表的一 ...
- 体验jQuery和AngularJS的不同点以及AngularJS的迷人之处
本篇通过jQuery和Angular两种方式来实现同一个实例,从而体验两者的不同点以及AngularJS的迷人之处. 首先当然需要引用jquery.js和angular.js文件. ■ 使用jQuer ...
- python 中的 easydict
写在前面:当遇到一个陌生的python第三方库时,可以去pypi这个主页查看描述以迅速入门!或 import time dir(time) easydict的作用:可以使得以属性的方式去访问字典的值! ...
- c++数组的引用
引用就是某一变量(目标)的一个别名,对引用的操作与对变量直接操作完全一样.引用的声明方法:类型标识符 &引用名=目标变量名: 引用最大的好处就是提高函数效率以及节省空间; 关键问题一.传递引用 ...
- 【网络】高性能网络编程--下一个10年,是时候考虑C10M并发问题了
转载:http://www.52im.net/thread-568-1-1.html 1.前言 在本系列文章的上篇中我们回顾了过云的10年里,高性能网络编程领域著名的C10K问题及其成功的解决方案(上 ...
- 国内混合APP开发技术选型
http://www.sunzhongwei.com/weex-react-native-ionic-technology-selection 选谁? 企业级应用是要考虑性能和流畅度的, 如果只是做个 ...
- Spring MVC实现上传文件报错解决方案
报错代码: org.springframework.beans.BeanInstantiationException: Could not instantiate bean class [org.sp ...
- SQL与MySQL基本
一:概念辨析 数据库(database):是一种保存有组织的数据的容器. 数据库软件(DBMS):使用DBMS操作数据库.访问数据库. SQL:结构化查询语言,专门用来与数据库通信的语言.几乎所有DB ...