InnoDB体系架构
MySQL支持插件式存储引擎,常用的存储引擎则是MyISAM和InnoDB,通常在OLTP(Online Transaction Processing 在线事务处理)中,我们选择使用InnoDB,所以弄清楚Innodb体系架构,有助于我们更深刻的理解innodb的工作原理,以及更好的使用innodb,以及优化。
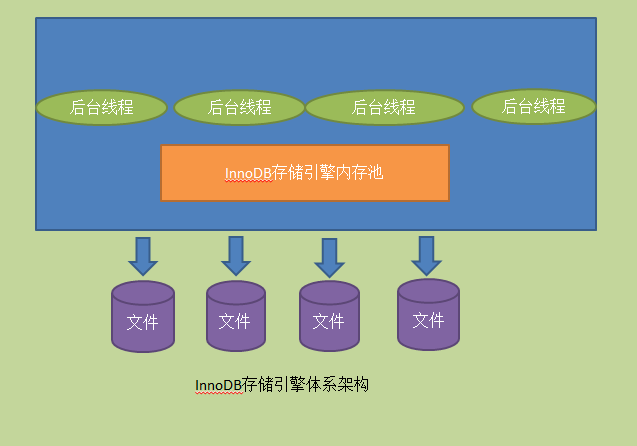
从上图大致可以看到innodb有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作:
1.维护所有进程/线程需要访问的多个内部数据结构。
2.缓存磁盘上的数据,方便快速的读取,同时在对磁盘文件的数据修改之前在这里缓存。
3.重做日志(redo log)缓冲
一.后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最新最近的数据。此外将已经修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情况下innodb能恢复正常的运行状态。
后台线程:
Innodb存储引擎是多线程的模型,因此其后台有多个不同的后台线程,负责处理不同的任务。
1.Master Thread
Master Thread 是非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新,合并插入缓冲(insert buffer),undo页的回收等。
2.IO Thread
在innodb存储引擎中大量使用了AIO(Async IO)来处理写IO请求,这样可以极大提高数据库的性能。而IO Thread的工作主要负责这些IO请求的回调(call back)处理。在innodb 1.0版本之前共有4个IO Thread,分别是write,read,insert buffer和log IO thread。从innodb 1.0.x版本开始,read thread和write thread分别增大到了4个。可以使用innodb_read_io_threads和innodb_write_io_threads参数进行设置。
mysql> show variables like 'innodb_version';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| innodb_version | 1.1.8 |
+----------------+-------+
1 row in set (0.00 sec) mysql> show variables like 'innodb_%io_threads';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_read_io_threads | 4 |
| innodb_write_io_threads | 4 |
+-------------------------+-------+
2 rows in set (0.00 sec) mysql>
3. Purge Thread
事务被提交后,其使用的undo log可能不再需要,因此Purge Thread来回收已经使用并分配的undo页。在innodb 1.1 版本之前,purge操作仅在innodb存储引擎的Master Thread中完成。从innodb1.1版本开始,purge操作可以独立到单独的线程中进行。以此来减轻Master Thread的工作。从而提高CPU的使用率以及提升存储引擎的性能。可以通过在配置文件中添加如下参数来开启独立的Purge Thread(清洗线程):
[mysqld]
innodb_purge_threads=
在innodb1.1版本中,即使innodb_purge_threads设为大于1,innodb存储引擎启动时也会将其设为1,并在错误日志中出现如下提示:
:: [Warning] option 'innodb-purge-threads': unsigned value adjusted to
从innodb1.2版本开始,innodb支持多个Purge Thread,这样做的目的是为了进一步加快undo页的回收。同时由于Purge Thread需要离散的读取undo页,这样可以更好的利用磁盘的随机读取性能。设置4个Pureg Thread线程:
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.6.10 |
+-----------+
1 row in set (0.00 sec) mysql> show variables like 'innodb_version';
+----------------+--------+
| Variable_name | Value |
+----------------+--------+
| innodb_version | 1.2.10 |
+----------------+--------+
1 row in set (0.00 sec) mysql> show variables like 'innodb_purge_threads';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| innodb_purge_threads | 4 |
+----------------------+-------+
1 row in set (0.00 sec) mysql>
4.Page cleaner Thread
page cleaner thread线程是在innodb 1.2.x的版本中引入的。其作用是将之前的版本中的脏页刷新操作都放入到单独的线程中来完成。而其目的是为了减轻原Master Thread的工作及对于用户查询线程的阻塞,进一步提高innodb存储引擎的性能。
内存
1.缓冲池
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程称为将页"FIX"在缓冲池中。下一次再读取相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中。直接读取该页。否则读取磁盘上的页。对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是每次页发生更新时触发,而是通过一种称为Checkpoint的机制刷新回磁盘。同样这也是为了提高数据库的整体性能。
对于innodb存储引擎而言,其缓冲池的配置通过参数innodb_buffer_ pool_size来设置。这是影响innodb性能的关键参数。具体来看,缓冲池中缓存的数据页类型有:索引页,数据页,undo页,插入缓冲(insert buffer),自适应哈希索引(adaptive hash index),innodb存储的锁信息(lock info),数据字典信息(data dictionary)等。不能简单的认为,缓冲池只是缓存索引页和数据页,它们只是占缓冲池很大的一部分而已。下图很好的显示了innodb存储引擎中的内存结构情况:
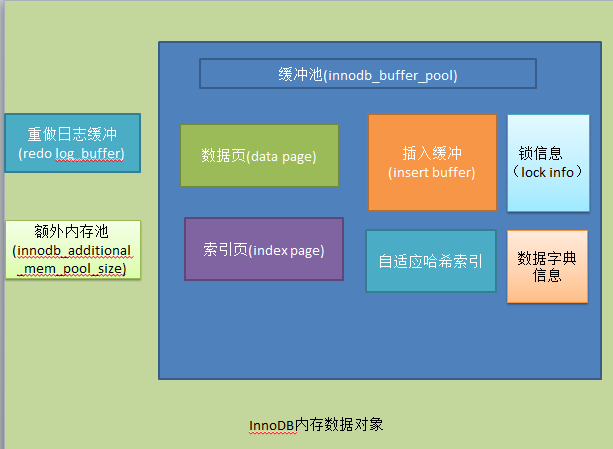
从innodb1.0.x版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。这样做的好处是减少数据库内部的资源竞争。增加数据库的并发处理能力。通过参数innodb_buffer_pool_instances来进行配置。该值默认为1。在配置文件中将innodb_buffer_pool_instances设置为大于1的值就可以得到多个缓冲池实例。
注意:innodb_buffer_pool_size必须大于1GB,生成innodb_buffer_pool多实例才有效,最多支持64个innodb_buffer_pool实例。
mysql> show engine innodb status\G
INDIVIDUAL BUFFER POOL INFO
----------------------
---BUFFER POOL 0
Buffer pool size 32768
Free buffers 32567
Database pages 201
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 201, created 0, written 0
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 201, unzip_LRU len: 0
I/O sum[]:cur[], unzip sum[]:cur[]
---BUFFER POOL 1
Buffer pool size 32768
Free buffers 32670
Database pages 98
Old database pages 0
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 98, created 0, written 0
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printou
可以看见有两个缓冲池实例在运行。
未完,待续。。。。。。
详细内容请阅读姜老师的大作<<mysql技术内幕,innodb存储引擎第2版>>
InnoDB体系架构的更多相关文章
- InnoDB体系架构(四)Master Thread工作方式
Master Thread工作方式 在前面的文章:InnoDB体系架构——后台线程 说到:InnoDB存储引擎的主要工作都是在一个单独的后台线程Master Thread中完成.这篇具体介绍该线程的具 ...
- InnoDB体系架构(三)Checkpoint技术
Checkpoint技术 前篇 InnoDB体系架构(二)内存 从缓冲池.缓冲池的管理.重做日志缓冲.额外内存缓冲这四个点介绍了InnoDB存储引擎的内存结构,而在将缓冲池的数据刷新到磁盘的过程中使用 ...
- InnoDB体系架构(二)内存
InnoDB体系架构(二)内存 上篇文章 InnoDB体系架构(一)后台线程 介绍了MySQL InnoDB存储引擎后台线程:Master Thread.IO Thread.Purge Thread. ...
- InnoDB体系架构(一)后台线程
InnoDB体系架构——后台线程 上一篇已经了解了MySQL数据库的体系结构 这一篇除了介绍InnoDB存储引擎的体系架构外,同时进一步了解InnoDB的后台线程. InnoDB存储引擎是多线程的模型 ...
- 2.3 InnoDB 体系架构
下图简单显示了InnoDB的存储引擎的体系架构,从图可见,InnoDB储存引擎有多个内存块,可以认为这些内存块组成了一个大的内存池,负责如下工作: 维护所有进程/线程需要访问的多个内部数据结构 缓存磁 ...
- InnoDB体系架构总结(二)
事务 确保事务内的SQL都可以同步执行 要么一起成功 要么一起失败.事务有四个特性原子性 一致性,隔离性,持久性 实现方式 开始事务的时候回家记录记录一个LSN日志序列 当事务执行的时候 会首先在In ...
- InnoDB体系架构总结(一)
缓冲池: 是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响.在数据库中读取的页数据会存放到缓冲池中,下次再读取相同页的时候,会首先判断该页是否在缓冲池中.对于数据库中页的修改操 ...
- MySQL技术内幕 InnoDB存储引擎 之 InnoDB体系架构
后台线程 1.Master Thread 2.IO Thread 3.Purge Thread 4.Page Cleaner Thread 内存 重做日志在以下三种情况下将重做日志缓存中的内容刷新到 ...
- MySQL--InnoDB 体系架构
InnoDB 体系架构 后台线程 Master Thread Master Thread 是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新.合并插入缓 ...
随机推荐
- Spark学习笔记——构建分类模型
Spark中常见的三种分类模型:线性模型.决策树和朴素贝叶斯模型. 线性模型,简单而且相对容易扩展到非常大的数据集:线性模型又可以分成:1.逻辑回归:2.线性支持向量机 决策树是一个强大的非线性技术, ...
- yum安装VirtualBox
参考官方文档: https://www.virtualbox.org/wiki/Linux_Downloads 配置yum源: vim /etc/yum.repos.d/virtualbox.repo ...
- js for in 获得遍历数组索引和对象属性
for in 遍历对象属性 获取的是对象的属性名 var person ={ name:"admin", age:"21", address:"sha ...
- Cordova 微信分享插件,安卓亲测可用
Cordova 微信分享插件,安卓亲测可用,收藏 https://github.com/vilic/cordova-plugin-wechat
- SQL逻辑查询语句执行顺序 需要重新整理
一.SQL语句定义顺序 1 2 3 4 5 6 7 8 9 10 SELECT DISTINCT <select_list> FROM <left_table> <joi ...
- G - Supermarket
A supermarket has a set Prod of products on sale. It earns a profit px for each product x∈Prod sold ...
- 5:CSS元素类型
5:CSS元素类型 学习目标 1.元素类型分类依据和元素类型分类 2.元素类型的转换 3.inline-block元素类型的应用 4.置换和非置换元素的概念和应用案例 一.元素类型分类依据和元素类型分 ...
- Python基础爬虫
搭建环境: win10,Python3.6,pycharm,未设虚拟环境 之前写的爬虫并没有架构的思想,且不具备面向对象的特征,现在写一个基础爬虫架构,爬取百度百科,首先介绍一下基础爬虫框架的五大模块 ...
- ELK之elasticsearch6安装认证模块search guard
参考:https://www.cnblogs.com/marility/p/9392645.html 1,安装环境及软件版本 程序 版本 安装方式 elasticsearch 6.3.1 rpm ...
- 没有上司的舞会|codevs1380|luoguP1352|树形DP|Elena
没有上司的舞会 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题目描述 Description Ural大学有N个职员,编号为1~N.他们有从属关系 ...