Hadoop概念学习系列之Java调用Shell命令和脚本,致力于hadoop/spark集群(三十六)
前言
说明的是,本博文,是在以下的博文基础上,立足于它们,致力于我的大数据领域!
http://kongcodecenter.iteye.com/blog/1231177
http://blog.csdn.net/u010376788/article/details/51337312
http://blog.csdn.net/arkblue/article/details/7897396
第一种:普通做法
首先,编号写WordCount.scala程序。
然后,打成jar包,命名为WC.jar。比如,我这里,是导出到windows桌面。
其次,上传到linux的桌面,再移动到hdfs的/目录。
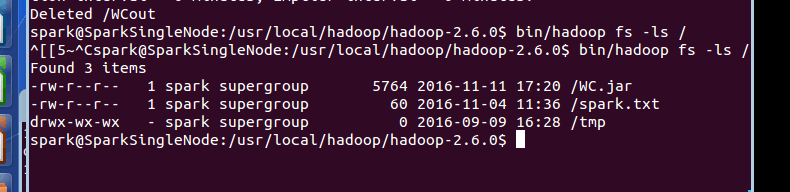
最后,在spark安装目录的bin下,执行
spark-submit \
> --class cn.spark.study.core.WordCount \
> --master local[1] \
> /home/spark/Desktop/WC.jar \
> hdfs://SparkSingleNode:9000/spark.txt \
> hdfs://SparkSingleNode:9000/WCout

第二种:高级做法
有时候我们在Linux中运行Java程序时,需要调用一些Shell命令和脚本。而Runtime.getRuntime().exec()方法给我们提供了这个功能,而且Runtime.getRuntime()给我们提供了以下几种exec()方法:
不多说,直接进入。
步骤一: 为了规范起见,命名为JavaShellUtil.java。在本地里写好

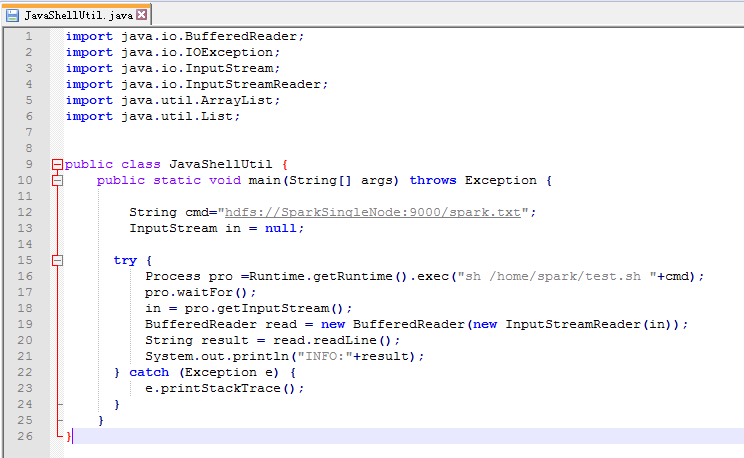
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class JavaShellUtil {
public static void main(String[] args) throws Exception {
String cmd="hdfs://SparkSingleNode:9000/spark.txt";
InputStream in = null;
try {
Process pro =Runtime.getRuntime().exec("sh /home/spark/test.sh "+cmd);
pro.waitFor();
in = pro.getInputStream();
BufferedReader read = new BufferedReader(new InputStreamReader(in));
String result = read.readLine();
System.out.println("INFO:"+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
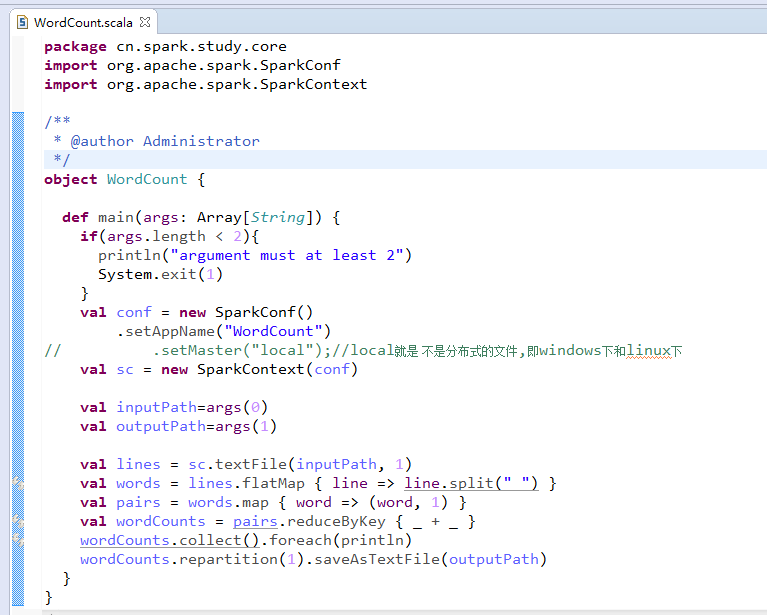
package cn.spark.study.core
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* @author Administrator
*/
object WordCount {
def main(args: Array[String]) {
if(args.length < 2){
println("argument must at least 2")
System.exit(1)
}
val conf = new SparkConf()
.setAppName("WordCount")
// .setMaster("local");//local就是 不是分布式的文件,即windows下和linux下
val sc = new SparkContext(conf)
val inputPath=args(0)
val outputPath=args(1)
val lines = sc.textFile(inputPath, 1)
val words = lines.flatMap { line => line.split(" ") }
val pairs = words.map { word => (word, 1) }
val wordCounts = pairs.reduceByKey { _ + _ }
wordCounts.collect().foreach(println)
wordCounts.repartition(1).saveAsTextFile(outputPath)
}
}
步骤二:编写好test.sh脚本

spark@SparkSingleNode:~$ cat test.sh
#!/bin/sh
/usr/local/spark/spark-1.5.2-bin-hadoop2.6/bin/spark-submit \
--class cn.spark.study.core.WordCount \
--master local[1] \
/home/spark/Desktop/WC.jar \
$1 hdfs://SparkSingleNode:9000/WCout
步骤三:上传JavaShellUtil.java,和打包好的WC.jar
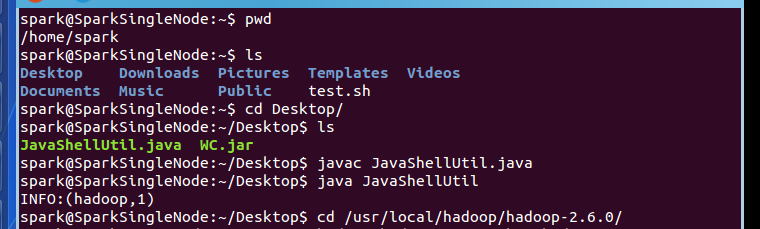
spark@SparkSingleNode:~$ pwd
/home/spark
spark@SparkSingleNode:~$ ls
Desktop Downloads Pictures Templates Videos
Documents Music Public test.sh
spark@SparkSingleNode:~$ cd Desktop/
spark@SparkSingleNode:~/Desktop$ ls
JavaShellUtil.java WC.jar
spark@SparkSingleNode:~/Desktop$ javac JavaShellUtil.java
spark@SparkSingleNode:~/Desktop$ java JavaShellUtil
INFO:(hadoop,1)
spark@SparkSingleNode:~/Desktop$ cd /usr/local/hadoop/hadoop-2.6.0/
步骤四:查看输出结果
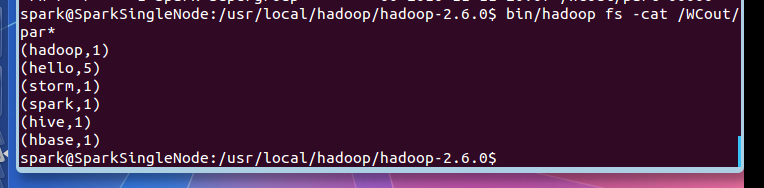
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$ bin/hadoop fs -cat /WCout/par*
(hadoop,1)
(hello,5)
(storm,1)
(spark,1)
(hive,1)
(hbase,1)
spark@SparkSingleNode:/usr/local/hadoop/hadoop-2.6.0$
成功!
关于
Shell 传递参数
见
http://www.runoob.com/linux/linux-shell-passing-arguments.html
最后说的是,不局限于此,可以穿插在以后我们生产业务里的。作为调用它即可,非常实用!
Hadoop概念学习系列之Java调用Shell命令和脚本,致力于hadoop/spark集群(三十六)的更多相关文章
- java基础/java调用shell命令和脚本
一.项目需求: 从某一机构获取证书,证书机构提供小工具,执行.sh脚本即可启动服务,本地调用该服务即可获取证书. 问题:linux服务器启动该服务,不能关闭.一旦关闭,服务即停止. 解决方案:java ...
- java调用shell命令及脚本
shell脚本在处理文本及管理操作系统时强大且简单,将shell脚本结合到应用程序中则是一种快速实现的不错途径本文介绍使用java代码调用并执行shell 我在 -/bin/ 目录下写了jbossLo ...
- shell 脚本实战笔记(10)--spark集群脚本片段念念碎
前言: 通过对spark集群脚本的研读, 对一些重要的shell脚本技巧, 做下笔记. *). 取当前脚本的目录 sbin=`dirname "$0"` sbin=`cd &quo ...
- Java 调用 Shell 命令
近日项目中有这样一个需求:系统中的外币资金调度完成以后,要将调度信息生成一个Txt文件,然后将这个Txt文件发送到另外一个系统(Kondor)中.生成文件自然使用OutputStreamWirter了 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- java 调用shell命令
原文:http://kongcodecenter.iteye.com/blog/1231177 Java通过SSH2协议执行远程Shell脚本(ganymed-ssh2-build210.jar) ...
- java 执行shell命令遇到的坑
正常来说java调用shell命令就是用 String[] cmdAry = new String[]{"/bin/bash","-c",cmd} Runtim ...
- Hadoop概念学习系列之Hadoop新手学习指导之入门需知(二十)
不多说,直接上干货! 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.从一开始什么都不懂,到能够搭建集群,开发.整个过程,只要有Linux基础,虚拟机化和java基础,其实hadoo ...
- [转载]JAVA调用Shell脚本
FROM:http://blog.csdn.net/jj12345jj198999/article/details/11891701 在实际项目中,JAVA有时候需要调用C写出来的东西,除了JNI以外 ...
随机推荐
- 两道不错的递推dp
hdoj-4055 #include <cstdio> #include <cstring> #include <iostream> #include <al ...
- python 闭包和迭代器
一 函数名的运用:(函数名是一个变量,但它是一个特殊变量,与括号配合可以执行变量. (1) 函数名可以赋值给其他变量 def chi(): print("吃月饼") fn=chi ...
- windows错误:错误0x80070091 目录不是空的
错误: Window 下目录无法删除,提示 “ 错误0x80070091 目录不是空的 ” 解决: 1.开始菜单>附件>命令提示符>右键>以管理员身份运行 2.删除文件:(如 ...
- UE4 C++ Tips
篇写的是关于UE4的C++方面的小技巧: 1.在构造函数里 //构建组件 RootComponent = CreateDefaultSubobject<USceneComponent>(T ...
- EasyUI datagrid 数据加载
网上找了好多人的方法发现都有问题发一个可用方便的 主要分三种情况 加载1,loaddata 加载2,datagrid 加载3, url 加载 第一部分,datagrid加载 第二部分,点击 datag ...
- servlet路径映射中的完全路径匹配、目录匹配、扩展名匹配
在servlet路径映射中,关于url-pattern的配置有三种,分别是完全路径匹配.目录匹配.扩展名匹配 其优先级分别为:完全路径匹配>目录匹配>扩展名匹配: 一.三种路径印射的区别 ...
- 【liunx】linux后台执行命令:&和nohup
当我们在终端或控制台工作时,可能不希望由于运行一个作业而占住了屏幕,因为可能还有更重要的事情要做,比如阅读电子邮件.对于密集访问磁盘的进程,我们更希望它能够在每天的非负荷高峰时间段运行(例如凌晨).为 ...
- jsp&el&jstl mvc和三层架构
jsp:java在html中插入java 一.JSP技术 1.jsp脚本和注释 jsp脚本:(翻译成servlet,源码位置apache-tomcat-7.0.52\work\Catalina\loc ...
- 新安装的win7/win10系统,所有驱动都没安装,插入U盘也无法识别解决方法
我是使用老毛挑安装的系统,结果安装好之后,才发现所有驱动都没有安装,例如usb,网卡驱动等 解决方法就是先把驱动下载到系统安装盘里面,然后再次进入安装系统界面,相当于重新安装系统,但实际上我们不需要. ...
- idea快捷键的修改
快捷键Ctrl+Alt+s,快速进入intellij idea设置项,点击Keymap,如图: 点击Main menu,再点开Code,如图: 点击Completion,再点击Basic,右键,如图 ...